CVD Flow Labels for Sessions Ranges [AMT Edition]CVD Flow Labels for Session Ranges
Description:
This script provides a session-aware Cumulative Volume Delta (CVD) analysis designed to enhance the “Session Ranges ” framework by combining price extremes with detailed volume flow dynamics. Unlike generic trend or scalping indicators, this tool focuses on identifying aggressive buying and selling pressure, distinguishing between absorption (failed auctions where aggressive flows are rejected) and acceptance (confirmed continuation of flows).
How it works:
CVD Calculation: The script calculates delta for each bar using a choice of Total, Periodic, or EMA-based cumulative methods. Delta represents the net difference between estimated buying and selling volume per bar.
Normalization: By normalizing delta relative to recent volatility, it highlights extreme flows that are statistically significant, making large shifts in market sentiment easier to spot.
Session-Specific Analysis: The indicator separates Asia, London, and New York sessions to allow context-sensitive interpretation of price and volume interactions. Each session’s extremes are monitored, and flow labels are plotted relative to these extremes.
Flow Labels: Bullish and bearish absorption (“ABS”) and acceptance (“ACC WEAK/STRONG”) labels provide immediate visual cues about whether aggressive flows are being absorbed or accepted at key price levels.
Alerts: Configurable alerts trigger when absorption or acceptance occurs, supporting active trading or strategy automation.
Originality & Usefulness:
This script is original because it integrates volume-based auction theory with session-specific market structure, rather than simply showing trend or scalping signals. By combining CVD dynamics with session extreme levels from the “Session Ranges ” script, traders can:
Identify where price is likely to be accepted or rejected.
Confirm aggressive buying or selling flows before entering trades.
Time entries near session extremes with higher probability setups.
How to use:
Apply the “Session Ranges ” to see session highs, lows, and interaction lines.
Use this CVD Flow Labels script to visualize absorption and acceptance at these session levels.
Enter trades based on alignment of session extremes and flow signals:
Absorption at a session extreme may indicate a potential reversal.
Acceptance suggests continuation in the direction of the flow.
Alerts can help manage trades without constant screen monitoring.
This tool is designed to give traders a structured, session-based view of market auctions, providing actionable insights that go beyond typical trend-following or scalping methods. It emphasizes flow analysis and statistical extremes, enabling traders to make more informed decisions grounded in market microstructure.
Patternrecognition

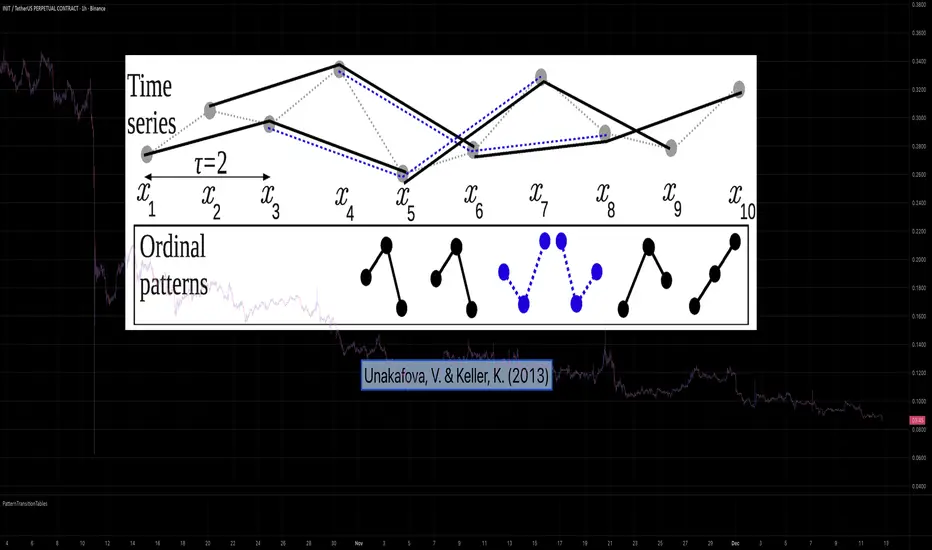
PatternTransitionTablesPatternTransitionTables Library
🌸 Part of GoemonYae Trading System (GYTS) 🌸
🌸 --------- 1. INTRODUCTION --------- 🌸
💮 Overview
This library provides precomputed state transition tables to enable ultra-efficient, O(1) computation of Ordinal Patterns. It is designed specifically to support high-performance indicators calculating Permutation Entropy and related complexity measures.
💮 The Problem & Solution
Calculating Permutation Entropy, as introduced by Bandt and Pompe (2002), typically requires computing ordinal patterns within a sliding window at every time step. The standard successive-pattern method (Equations 2+3 in the paper) requires ≤ 4d-1 operations per update.
Unakafova and Keller (2013) demonstrated that successive ordinal patterns "overlap" significantly. By knowing the current pattern index and the relative rank (position l) of just the single new data point, the next pattern index can be determined via a precomputed look-up table. Computing l still requires d comparisons, but the table lookup itself is O(1), eliminating the need for d multiplications and d additions. This reduces total operations from ≤ 4d-1 to ≤ 2d per update (Table 4). This library contains these precomputed tables for orders d = 2 through d = 5.
🌸 --------- 2. THEORETICAL BACKGROUND --------- 🌸
💮 Permutation Entropy
Bandt, C., & Pompe, B. (2002). Permutation entropy: A natural complexity measure for time series.
doi.org
This concept quantifies the complexity of a system by comparing the order of neighbouring values rather than their magnitudes. It is robust against noise and non-linear distortions, making it ideal for financial time series analysis.
💮 Efficient Computation
Unakafova, V. A., & Keller, K. (2013). Efficiently Measuring Complexity on the Basis of Real-World Data.
doi.org
This library implements the transition function φ_d(n, l) described in Equation 5 of the paper. It maps a current pattern index (n) and the position of the new value (l) to the successor pattern, reducing the complexity of updates to constant time O(1).
🌸 --------- 3. LIBRARY FUNCTIONALITY --------- 🌸
💮 Data Structure
The library stores transition matrices as flattened 1D integer arrays. These tables are mathematically rigorous representations of the factorial number system used to enumerate permutations.
💮 Core Function: get_successor()
This is the primary interface for the library for direct pattern updates.
• Input: The current pattern index and the rank position of the incoming price data.
• Process: Routes the request to the specific transition table for the chosen order (d=2 to d=5).
• Output: The integer index of the next ordinal pattern.
💮 Table Access: get_table()
This function returns the entire flattened transition table for a specified dimension. This enables local caching of the table (e.g. in an indicator's init() method), avoiding the overhead of repeated library calls during the calculation loop.
💮 Supported Orders & Terminology
The parameter d is the order of ordinal patterns (following Bandt & Pompe 2002). Each pattern of order d contains (d+1) data points, yielding (d+1)! unique patterns:
• d=2: 3 points → 6 unique patterns, 3 successor positions
• d=3: 4 points → 24 unique patterns, 4 successor positions
• d=4: 5 points → 120 unique patterns, 5 successor positions
• d=5: 6 points → 720 unique patterns, 6 successor positions
Note: d=6 is not implemented. The resulting code size (approx. 191k tokens) exceeds the Pine Script limit of 100k tokens (as of 2025-12).
SMC N-Gram Probability Matrix [PhenLabs]📊 SMC N-Gram Probability Matrix
Version: PineScript™ v6
📌 Description
The SMC N-Gram Probability Matrix applies computational linguistics methodology to Smart Money Concepts trading. By treating SMC patterns as a discrete “alphabet” and analyzing their sequential relationships through N-gram modeling, this indicator calculates the statistical probability of which pattern will appear next based on historical transitions.
Traditional SMC analysis is reactive—traders identify patterns after they form and then anticipate the next move. This indicator inverts that approach by building a transition probability matrix from up to 5,000 bars of pattern history, enabling traders to see which SMC formations most frequently follow their current market sequence.
The indicator detects and classifies 11 distinct SMC patterns including Fair Value Gaps, Order Blocks, Liquidity Sweeps, Break of Structure, and Change of Character in both bullish and bearish variants, then tracks how these patterns transition from one to another over time.
🚀 Points of Innovation
First indicator to apply N-gram sequence modeling from computational linguistics to SMC pattern analysis
Dynamic transition matrix rebuilds every 50 bars for adaptive probability calculations
Supports bigram (2), trigram (3), and quadgram (4) sequence lengths for varying analysis depth
Priority-based pattern classification ensures higher-significance patterns (CHoCH, BOS) take precedence
Configurable minimum occurrence threshold filters out statistically insignificant predictions
Real-time probability visualization with graphical confidence bars
🔧 Core Components
Pattern Alphabet System: 11 discrete SMC patterns encoded as integers for efficient matrix indexing and transition tracking
Swing Point Detection: Uses ta.pivothigh/pivotlow with configurable sensitivity for non-repainting structure identification
Transition Count Matrix: Flattened array storing occurrence counts for all possible pattern sequence transitions
Context Encoder: Converts N-gram pattern sequences into unique integer IDs for matrix lookup
Probability Calculator: Transforms raw transition counts into percentage probabilities for each possible next pattern
🔥 Key Features
Multi-Pattern SMC Detection: Simultaneously identifies FVGs, Order Blocks, Liquidity Sweeps, BOS, and CHoCH formations
Adjustable N-Gram Length: Choose between 2-4 pattern sequences to balance specificity against sample size
Flexible Lookback Range: Analyze anywhere from 100 to 5,000 historical bars for matrix construction
Pattern Toggle Controls: Enable or disable individual SMC pattern types to customize analysis focus
Probability Threshold Filtering: Set minimum occurrence requirements to ensure prediction reliability
Alert Integration: Built-in alert conditions trigger when high-probability predictions emerge
🎨 Visualization
Probability Table: Displays current pattern, recent sequence, sample count, and top N predicted patterns with percentage probabilities
Graphical Probability Bars: Visual bar representation (█░) showing relative probability strength at a glance
Chart Pattern Markers: Color-coded labels placed directly on price bars identifying detected SMC formations
Pattern Short Codes: Compact notation (F+, F-, O+, O-, L↑, L↓, B+, B-, C+, C-) for quick pattern identification
Customizable Table Position: Place probability display in any corner of your chart
📖 Usage Guidelines
N-Gram Configuration
N-Gram Length: Default 2, Range 2-4. Lower values provide more samples but less specificity. Higher values capture complex sequences but require more historical data.
Matrix Lookback Bars: Default 500, Range 100-5000. More bars increase statistical significance but may include outdated market behavior.
Min Occurrences for Prediction: Default 2, Range 1-10. Higher values filter noise but may reduce prediction availability.
SMC Detection Settings
Swing Detection Length: Default 5, Range 2-20. Controls pivot sensitivity for structure analysis.
FVG Minimum Size: Default 0.1%, Range 0.01-2.0%. Filters insignificant gaps.
Order Block Lookback: Default 10, Range 3-30. Bars to search for OB formations.
Liquidity Sweep Threshold: Default 0.3%, Range 0.05-1.0%. Minimum wick extension beyond swing points.
Display Settings
Show Probability Table: Toggle the probability matrix display on/off.
Show Top N Probabilities: Default 5, Range 3-10. Number of predicted patterns to display.
Show SMC Markers: Toggle on-chart pattern labels.
✅ Best Use Cases
Anticipating continuation or reversal patterns after liquidity sweeps
Identifying high-probability BOS/CHoCH sequences for trend trading
Filtering FVG and Order Block signals based on historical follow-through rates
Building confluence by comparing predicted patterns with other technical analysis
Studying how SMC patterns typically sequence on specific instruments or timeframes
⚠️ Limitations
Predictions are based solely on historical pattern frequency and do not account for fundamental factors
Low sample counts produce unreliable probabilities—always check the Samples display
Market regime changes can invalidate historical transition patterns
The indicator requires sufficient historical data to build meaningful probability matrices
Pattern detection uses standardized parameters that may not capture all institutional activity
💡 What Makes This Unique
Linguistic Modeling Applied to Markets: Treats SMC patterns like words in a language, analyzing how they “flow” together
Quantified Pattern Relationships: Transforms subjective SMC analysis into objective probability percentages
Adaptive Learning: Matrix rebuilds periodically to incorporate recent pattern behavior
Comprehensive SMC Coverage: Tracks all major Smart Money Concepts in a unified probability framework
🔬 How It Works
1. Pattern Detection Phase
Each bar is analyzed for SMC formations using configurable detection parameters
A priority hierarchy assigns the most significant pattern when multiple detections occur
2. Sequence Encoding Phase
Detected patterns are stored in a rolling history buffer of recent classifications
The current N-gram context is encoded into a unique integer identifier
3. Matrix Construction Phase
Historical pattern sequences are iterated to count transition occurrences
Each context-to-next-pattern transition increments the appropriate matrix cell
4. Probability Calculation Phase
Current context ID retrieves corresponding transition counts from the matrix
Raw counts are converted to percentages based on total context occurrences
5. Visualization Phase
Probabilities are sorted and the top N predictions are displayed in the table
Chart markers identify the current detected pattern for visual reference
💡 Note:
This indicator performs best when used as a confluence tool alongside traditional SMC analysis. The probability predictions highlight statistically common pattern sequences but should not be used as standalone trading signals. Always verify predictions against price action context, higher timeframe structure, and your overall trading plan. Monitor the sample count to ensure predictions are based on adequate historical data.

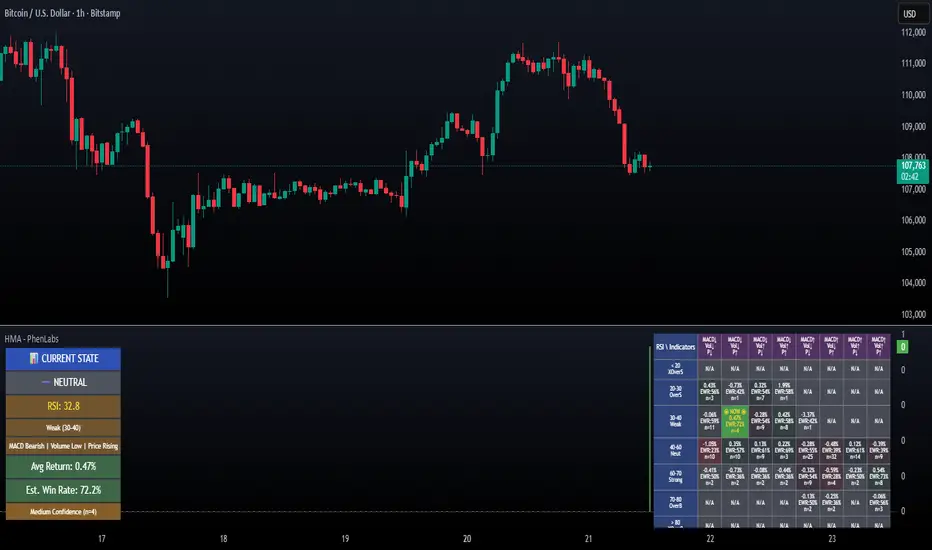
Historical Matrix Analyzer [PhenLabs]📊Historical Matrix Analyzer
Version: PineScriptv6
📌Description
The Historical Matrix Analyzer is an advanced probabilistic trading tool that transforms technical analysis into a data-driven decision support system. By creating a comprehensive 56-cell matrix that tracks every combination of RSI states and multi-indicator conditions, this indicator reveals which market patterns have historically led to profitable outcomes and which have not.
At its core, the indicator continuously monitors seven distinct RSI states (ranging from Extreme Oversold to Extreme Overbought) and eight unique indicator combinations (MACD direction, volume levels, and price momentum). For each of these 56 possible market states, the system calculates average forward returns, win rates, and occurrence counts based on your configurable lookback period. The result is a color-coded probability matrix that shows you exactly where you stand in the historical performance landscape.
The standout feature is the Current State Panel, which provides instant clarity on your active market conditions. This panel displays signal strength classifications (from Strong Bullish to Strong Bearish), the average return percentage for similar past occurrences, an estimated win rate using Bayesian smoothing to prevent small-sample distortions, and a confidence level indicator that warns you when insufficient data exists for reliable conclusions.
🚀Points of Innovation
Multi-dimensional state classification combining 7 RSI levels with 8 indicator combinations for 56 unique trackable market conditions
Bayesian win rate estimation with adjustable smoothing strength to provide stable probability estimates even with limited historical samples
Real-time active cell highlighting with “NOW” marker that visually connects current market conditions to their historical performance data
Configurable color intensity sensitivity allowing traders to adjust heat-map responsiveness from conservative to aggressive visual feedback
Dual-panel display system separating the comprehensive statistics matrix from an easy-to-read current state summary panel
Intelligent confidence scoring that automatically warns traders when occurrence counts fall below reliable thresholds
🔧Core Components
RSI State Classification: Segments RSI readings into 7 distinct zones (Extreme Oversold <20, Oversold 20-30, Weak 30-40, Neutral 40-60, Strong 60-70, Overbought 70-80, Extreme Overbought >80) to capture momentum extremes and transitions
Multi-Indicator Condition Tracking: Simultaneously monitors MACD crossover status (bullish/bearish), volume relative to moving average (high/low), and price direction (rising/falling) creating 8 binary-encoded combinations
Historical Data Storage Arrays: Maintains rolling lookback windows storing RSI states, indicator states, prices, and bar indices for precise forward-return calculations
Forward Performance Calculator: Measures price changes over configurable forward bar periods (1-20 bars) from each historical state, accumulating total returns and win counts per matrix cell
Bayesian Smoothing Engine: Applies statistical prior assumptions (default 50% win rate) weighted by user-defined strength parameter to stabilize estimated win rates when sample sizes are small
Dynamic Color Mapping System: Converts average returns into color-coded heat map with intensity adjusted by sensitivity parameter and transparency modified by confidence levels
🔥Key Features
56-Cell Probability Matrix: Comprehensive grid displaying every possible combination of RSI state and indicator condition, with each cell showing average return percentage, estimated win rate, and occurrence count for complete statistical visibility
Current State Info Panel: Dedicated display showing your exact position in the matrix with signal strength emoji indicators, numerical statistics, and color-coded confidence warnings for immediate situational awareness
Customizable Lookback Period: Adjustable historical window from 50 to 500 bars allowing traders to focus on recent market behavior or capture longer-term pattern stability across different market cycles
Configurable Forward Performance Window: Select target holding periods from 1 to 20 bars ahead to align probability calculations with your trading timeframe, whether day trading or swing trading
Visual Heat Mapping: Color-coded cells transition from red (bearish historical performance) through gray (neutral) to green (bullish performance) with intensity reflecting statistical significance and occurrence frequency
Intelligent Data Filtering: Minimum occurrence threshold (1-10) removes unreliable patterns with insufficient historical samples, displaying gray warning colors for low-confidence cells
Flexible Layout Options: Independent positioning of statistics matrix and info panel to any screen corner, accommodating different chart layouts and personal preferences
Tooltip Details: Hover over any matrix cell to see full RSI label, complete indicator status description, precise average return, estimated win rate, and total occurrence count
🎨Visualization
Statistics Matrix Table: A 9-column by 8-row grid with RSI states labeling vertical axis and indicator combinations on horizontal axis, using compact abbreviations (XOverS, OverB, MACD↑, Vol↓, P↑) for space efficiency
Active Cell Indicator: The current market state cell displays “⦿ NOW ⦿” in yellow text with enhanced color saturation to immediately draw attention to relevant historical performance
Signal Strength Visualization: Info panel uses emoji indicators (🔥 Strong Bullish, ✅ Bullish, ↗️ Weak Bullish, ➖ Neutral, ↘️ Weak Bearish, ⛔ Bearish, ❄️ Strong Bearish, ⚠️ Insufficient Data) for rapid interpretation
Histogram Plot: Below the price chart, a green/red histogram displays the current cell’s average return percentage, providing a time-series view of how historical performance changes as market conditions evolve
Color Intensity Scaling: Cell background transparency and saturation dynamically adjust based on both the magnitude of average returns and the occurrence count, ensuring visual emphasis on reliable patterns
Confidence Level Display: Info panel bottom row shows “High Confidence” (green), “Medium Confidence” (orange), or “Low Confidence” (red) based on occurrence counts relative to minimum threshold multipliers
📖Usage Guidelines
RSI Period
Default: 14
Range: 1 to unlimited
Description: Controls the lookback period for RSI momentum calculation. Standard 14-period provides widely-recognized overbought/oversold levels. Decrease for faster, more sensitive RSI reactions suitable for scalping. Increase (21, 28) for smoother, longer-term momentum assessment in swing trading. Changes affect how quickly the indicator moves between the 7 RSI state classifications.
MACD Fast Length
Default: 12
Range: 1 to unlimited
Description: Sets the faster exponential moving average for MACD calculation. Standard 12-period setting works well for daily charts and captures short-term momentum shifts. Decreasing creates more responsive MACD crossovers but increases false signals. Increasing smooths out noise but delays signal generation, affecting the bullish/bearish indicator state classification.
MACD Slow Length
Default: 26
Range: 1 to unlimited
Description: Defines the slower exponential moving average for MACD calculation. Traditional 26-period setting balances trend identification with responsiveness. Must be greater than Fast Length. Wider spread between fast and slow increases MACD sensitivity to trend changes, impacting the frequency of indicator state transitions in the matrix.
MACD Signal Length
Default: 9
Range: 1 to unlimited
Description: Smoothing period for the MACD signal line that triggers bullish/bearish state changes. Standard 9-period provides reliable crossover signals. Shorter values create more frequent state changes and earlier signals but with more whipsaws. Longer values produce more confirmed, stable signals but with increased lag in detecting momentum shifts.
Volume MA Period
Default: 20
Range: 1 to unlimited
Description: Lookback period for volume moving average used to classify volume as “high” or “low” in indicator state combinations. 20-period default captures typical monthly trading patterns. Shorter periods (10-15) make volume classification more reactive to recent spikes. Longer periods (30-50) require more sustained volume changes to trigger state classification shifts.
Statistics Lookback Period
Default: 200
Range: 50 to 500
Description: Number of historical bars used to calculate matrix statistics. 200 bars provides substantial data for reliable patterns while remaining responsive to regime changes. Lower values (50-100) emphasize recent market behavior and adapt quickly but may produce volatile statistics. Higher values (300-500) capture long-term patterns with stable statistics but slower adaptation to changing market dynamics.
Forward Performance Bars
Default: 5
Range: 1 to 20
Description: Number of bars ahead used to calculate forward returns from each historical state occurrence. 5-bar default suits intraday to short-term swing trading (5 hours on hourly charts, 1 week on daily charts). Lower values (1-3) target short-term momentum trades. Higher values (10-20) align with position trading and longer-term pattern exploitation.
Color Intensity Sensitivity
Default: 2.0
Range: 0.5 to 5.0, step 0.5
Description: Amplifies or dampens the color intensity response to average return magnitudes in the matrix heat map. 2.0 default provides balanced visual emphasis. Lower values (0.5-1.0) create subtle coloring requiring larger returns for full saturation, useful for volatile instruments. Higher values (3.0-5.0) produce vivid colors from smaller returns, highlighting subtle edges in range-bound markets.
Minimum Occurrences for Coloring
Default: 3
Range: 1 to 10
Description: Required minimum sample size before applying color-coded performance to matrix cells. Cells with fewer occurrences display gray “insufficient data” warning. 3-occurrence default filters out rare patterns. Lower threshold (1-2) shows more data but includes unreliable single-event statistics. Higher thresholds (5-10) ensure only well-established patterns receive visual emphasis.
Table Position
Default: top_right
Options: top_left, top_right, bottom_left, bottom_right
Description: Screen location for the 56-cell statistics matrix table. Position to avoid overlapping critical price action or other indicators on your chart. Consider chart orientation and candlestick density when selecting optimal placement.
Show Current State Panel
Default: true
Options: true, false
Description: Toggle visibility of the dedicated current state information panel. When enabled, displays signal strength, RSI value, indicator status, average return, estimated win rate, and confidence level for active market conditions. Disable to declutter charts when only the matrix table is needed.
Info Panel Position
Default: bottom_left
Options: top_left, top_right, bottom_left, bottom_right
Description: Screen location for the current state information panel (when enabled). Position independently from statistics matrix to optimize chart real estate. Typically placed opposite the matrix table for balanced visual layout.
Win Rate Smoothing Strength
Default: 5
Range: 1 to 20
Description: Controls Bayesian prior weighting for estimated win rate calculations. Acts as virtual sample size assuming 50% win rate baseline. Default 5 provides moderate smoothing preventing extreme win rate estimates from small samples. Lower values (1-3) reduce smoothing effect, allowing win rates to reflect raw data more directly. Higher values (10-20) increase conservatism, pulling win rate estimates toward 50% until substantial evidence accumulates.
✅Best Use Cases
Pattern-based discretionary trading where you want historical confirmation before entering setups that “look good” based on current technical alignment
Swing trading with holding periods matching your forward performance bar setting, using high-confidence bullish cells as entry filters
Risk assessment and position sizing, allocating larger size to trades originating from cells with strong positive average returns and high estimated win rates
Market regime identification by observing which RSI states and indicator combinations are currently producing the most reliable historical patterns
Backtesting validation by comparing your manual strategy signals against the historical performance of the corresponding matrix cells
Educational tool for developing intuition about which technical condition combinations have actually worked versus those that feel right but lack historical evidence
⚠️Limitations
Historical patterns do not guarantee future performance, especially during unprecedented market events or regime changes not represented in the lookback period
Small sample sizes (low occurrence counts) produce unreliable statistics despite Bayesian smoothing, requiring caution when acting on low-confidence cells
Matrix statistics lag behind rapidly changing market conditions, as the lookback period must accumulate new state occurrences before updating performance data
Forward return calculations use fixed bar periods that may not align with actual trade exit timing, support/resistance levels, or volatility-adjusted profit targets
💡What Makes This Unique
Multi-Dimensional State Space: Unlike single-indicator tools, simultaneously tracks 56 distinct market condition combinations providing granular pattern resolution unavailable in traditional technical analysis
Bayesian Statistical Rigor: Implements proper probabilistic smoothing to prevent overconfidence from limited data, a critical feature missing from most pattern recognition tools
Real-Time Contextual Feedback: The “NOW” marker and dedicated info panel instantly connect current market conditions to their historical performance profile, eliminating guesswork
Transparent Occurrence Counts: Displays sample sizes directly in each cell, allowing traders to judge statistical reliability themselves rather than hiding data quality issues
Fully Customizable Analysis Window: Complete control over lookback depth and forward return horizons lets traders align the tool precisely with their trading timeframe and strategy requirements
🔬How It Works
1. State Classification and Encoding
Each bar’s RSI value is evaluated and assigned to one of 7 discrete states based on threshold levels (0: <20, 1: 20-30, 2: 30-40, 3: 40-60, 4: 60-70, 5: 70-80, 6: >80)
Simultaneously, three binary conditions are evaluated: MACD line position relative to signal line, current volume relative to its moving average, and current close relative to previous close
These three binary conditions are combined into a single indicator state integer (0-7) using binary encoding, creating 8 possible indicator combinations
The RSI state and indicator state are stored together, defining one of 56 possible market condition cells in the matrix
2. Historical Data Accumulation
As each bar completes, the current state classification, closing price, and bar index are stored in rolling arrays maintained at the size specified by the lookback period
When the arrays reach capacity, the oldest data point is removed and the newest added, creating a sliding historical window
This continuous process builds a comprehensive database of past market conditions and their subsequent price movements
3. Forward Return Calculation and Statistics Update
On each bar, the indicator looks back through the stored historical data to find bars where sufficient forward bars exist to measure outcomes
For each historical occurrence, the price change from that bar to the bar N periods ahead (where N is the forward performance bars setting) is calculated as a percentage return
This percentage return is added to the cumulative return total for the specific matrix cell corresponding to that historical bar’s state classification
Occurrence counts are incremented, and wins are tallied for positive returns, building comprehensive statistics for each of the 56 cells
The Bayesian smoothing formula combines these raw statistics with prior assumptions (neutral 50% win rate) weighted by the smoothing strength parameter to produce estimated win rates that remain stable even with small samples
💡Note:
The Historical Matrix Analyzer is designed as a decision support tool, not a standalone trading system. Best results come from using it to validate discretionary trade ideas or filter systematic strategy signals. Always combine matrix insights with proper risk management, position sizing rules, and awareness of broader market context. The estimated win rate feature uses Bayesian statistics specifically to prevent false confidence from limited data, but no amount of smoothing can create reliable predictions from fundamentally insufficient sample sizes. Focus on high-confidence cells (green-colored confidence indicators) with occurrence counts well above your minimum threshold for the most actionable insights.
CNN Statistical Trading System [PhenLabs]📌 DESCRIPTION
An advanced pattern recognition system utilizing Convolutional Neural Network (CNN) principles to identify statistically significant market patterns and generate high-probability trading signals.
CNN Statistical Trading System transforms traditional technical analysis by applying machine learning concepts directly to price action. Through six specialized convolution kernels, it detects momentum shifts, reversal patterns, consolidation phases, and breakout setups simultaneously. The system combines these pattern detections using adaptive weighting based on market volatility and trend strength, creating a sophisticated composite score that provides both directional bias and signal confidence on a normalized -1 to +1 scale.
🚀 CONCEPTS
• Built on Convolutional Neural Network pattern recognition methodology adapted for financial markets
• Six specialized kernels detect distinct price patterns: upward/downward momentum, peak/trough formations, consolidation, and breakout setups
• Activation functions create non-linear responses with tanh-like behavior, mimicking neural network layers
• Adaptive weighting system adjusts pattern importance based on current market regime (volatility < 2% and trend strength)
• Multi-confirmation signals require CNN threshold breach (±0.65), RSI boundaries, and volume confirmation above 120% of 20-period average
🔧 FEATURES
Six-Kernel Pattern Detection:
Simultaneous analysis of upward momentum, downward momentum, peak/resistance, trough/support, consolidation, and breakout patterns using mathematically optimized convolution kernels.
Adaptive Neural Architecture:
Dynamic weight adjustment based on market volatility (ATR/Price) and trend strength (EMA differential), ensuring optimal performance across different market conditions.
Professional Visual Themes:
Four sophisticated color palettes (Professional, Ocean, Sunset, Monochrome) with cohesive design language. Default Monochrome theme provides clean, distraction-free analysis.
Confidence Band System:
Upper and lower confidence zones at 150% of threshold values (±0.975) help identify high-probability signal areas and potential exhaustion zones.
Real-Time Information Panel:
Live display of CNN score, market state with emoji indicators, net momentum, confidence percentage, and RSI confirmation with dynamic color coding based on signal strength.
Individual Feature Analysis:
Optional display of all six kernel outputs with distinct visual styles (step lines, circles, crosses, area fills) for advanced pattern component analysis.
User Guide
• Monitor CNN Score crossing above +0.65 for long signals or below -0.65 for short signals with volume confirmation
• Use confidence bands to identify optimal entry zones - signals within confidence bands carry higher probability
• Background intensity reflects signal strength - darker backgrounds indicate stronger conviction
• Enter long positions when blue circles appear above oscillator with RSI < 75 and volume > 120% average
• Enter short positions when dark circles appear below oscillator with RSI > 25 and volume confirmation
• Information panel provides real-time confidence percentage and momentum direction for position sizing decisions
• Individual feature plots allow granular analysis of specific pattern components for strategy refinement
💡Conclusion
CNN Statistical Trading System represents the evolution of technical analysis, combining institutional-grade pattern recognition with retail accessibility. The six-kernel architecture provides comprehensive market pattern coverage while adaptive weighting ensures relevance across all market conditions. Whether you’re seeking systematic entry signals or advanced pattern confirmation, this indicator delivers mathematically rigorous analysis with intuitive visual presentation.

Volume Predictor [PhenLabs]📊 Volume Predictor
Version: PineScript™ v6
📌 Description
The Volume Predictor is an advanced technical indicator that leverages machine learning and statistical modeling techniques to forecast future trading volume. This innovative tool analyzes historical volume patterns to predict volume levels for upcoming bars, providing traders with valuable insights into potential market activity. By combining multiple prediction algorithms with pattern recognition techniques, the indicator delivers forward-looking volume projections that can enhance trading strategies and market analysis.
🚀 Points of Innovation:
Machine learning pattern recognition using Lorentzian distance metrics
Multi-algorithm prediction framework with algorithm selection
Ensemble learning approach combining multiple prediction methods
Real-time accuracy metrics with visual performance dashboard
Dynamic volume normalization for consistent scale representation
Forward-looking visualization with configurable prediction horizon
🔧 Core Components
Pattern Recognition Engine : Identifies similar historical volume patterns using Lorentzian distance metrics
Multi-Algorithm Framework : Offers five distinct prediction methods with configurable parameters
Volume Normalization : Converts raw volume to percentage scale for consistent analysis
Accuracy Tracking : Continuously evaluates prediction performance against actual outcomes
Advanced Visualization : Displays actual vs. predicted volume with configurable future bar projections
Interactive Dashboard : Shows real-time performance metrics and prediction accuracy
🔥 Key Features
The indicator provides comprehensive volume analysis through:
Multiple Prediction Methods : Choose from Lorentzian, KNN Pattern, Ensemble, EMA, or Linear Regression algorithms
Pattern Matching : Identifies similar historical volume patterns to project future volume
Adaptive Predictions : Generates volume forecasts for multiple bars into the future
Performance Tracking : Calculates and displays real-time prediction accuracy metrics
Normalized Scale : Presents volume as a percentage of historical maximums for consistent analysis
Customizable Visualization : Configure how predictions and actual volumes are displayed
Interactive Dashboard : View algorithm performance metrics in a customizable information panel
🎨 Visualization
Actual Volume Columns : Color-coded green/red bars showing current normalized volume
Prediction Columns : Semi-transparent blue columns representing predicted volume levels
Future Bar Projections : Forward-looking volume predictions with configurable transparency
Prediction Dots : Optional white dots highlighting future prediction points
Reference Lines : Visual guides showing the normalized volume scale
Performance Dashboard : Customizable panel displaying prediction method and accuracy metrics
📖 Usage Guidelines
History Lookback Period
Default: 20
Range: 5-100
This setting determines how many historical bars are analyzed for pattern matching. A longer period provides more historical data for pattern recognition but may reduce responsiveness to recent changes. A shorter period emphasizes recent market behavior but might miss longer-term patterns.
🧠 Prediction Method
Algorithm
Default: Lorentzian
Options: Lorentzian, KNN Pattern, Ensemble, EMA, Linear Regression
Selects the algorithm used for volume prediction:
Lorentzian: Uses Lorentzian distance metrics for pattern recognition, offering excellent noise resistance
KNN Pattern: Traditional K-Nearest Neighbors approach for historical pattern matching
Ensemble: Combines multiple methods with weighted averaging for robust predictions
EMA: Simple exponential moving average projection for trend-following predictions
Linear Regression: Projects future values based on linear trend analysis
Pattern Length
Default: 5
Range: 3-10
Defines the number of bars in each pattern for machine learning methods. Shorter patterns increase sensitivity to recent changes, while longer patterns may identify more complex structures but require more historical data.
Neighbors Count
Default: 3
Range: 1-5
Sets the K value (number of nearest neighbors) used in KNN and Lorentzian methods. Higher values produce smoother predictions by averaging more historical patterns, while lower values may capture more specific patterns but could be more susceptible to noise.
Prediction Horizon
Default: 5
Range: 1-10
Determines how many future bars to predict. Longer horizons provide more forward-looking information but typically decrease accuracy as the prediction window extends.
📊 Display Settings
Display Mode
Default: Overlay
Options: Overlay, Prediction Only
Controls how volume information is displayed:
Overlay: Shows both actual volume and predictions on the same chart
Prediction Only: Displays only the predictions without actual volume
Show Prediction Dots
Default: false
When enabled, adds white dots to future predictions for improved visibility and clarity.
Future Bar Transparency (%)
Default: 70
Range: 0-90
Controls the transparency of future prediction bars. Higher values make future bars more transparent, while lower values make them more visible.
📱 Dashboard Settings
Show Dashboard
Default: true
Toggles display of the prediction accuracy dashboard. When enabled, shows real-time accuracy metrics.
Dashboard Location
Default: Bottom Right
Options: Top Left, Top Right, Bottom Left, Bottom Right
Determines where the dashboard appears on the chart.
Dashboard Text Size
Default: Normal
Options: Small, Normal, Large
Controls the size of text in the dashboard for various display sizes.
Dashboard Style
Default: Solid
Options: Solid, Transparent
Sets the visual style of the dashboard background.
Understanding Accuracy Metrics
The dashboard provides key performance metrics to evaluate prediction quality:
Average Error
Shows the average difference between predicted and actual values
Positive values indicate the prediction tends to be higher than actual volume
Negative values indicate the prediction tends to be lower than actual volume
Values closer to zero indicate better prediction accuracy
Accuracy Percentage
A measure of how close predictions are to actual outcomes
Higher percentages (>70%) indicate excellent prediction quality
Moderate percentages (50-70%) indicate acceptable predictions
Lower percentages (<50%) suggest weaker prediction reliability
The accuracy metrics are color-coded for quick assessment:
Green: Strong prediction performance
Orange: Moderate prediction performance
Red: Weaker prediction performance
✅ Best Use Cases
Anticipate upcoming volume spikes or drops
Identify potential volume divergences from price action
Plan entries and exits around expected volume changes
Filter trading signals based on predicted volume support
Optimize position sizing by forecasting market participation
Prepare for potential volatility changes signaled by volume predictions
Enhance technical pattern analysis with volume projection context
⚠️ Limitations
Volume predictions become less accurate over longer time horizons
Performance varies based on market conditions and asset characteristics
Works best on liquid assets with consistent volume patterns
Requires sufficient historical data for pattern recognition
Sudden market events can disrupt prediction accuracy
Volume spikes may be muted in predictions due to normalization
💡 What Makes This Unique
Machine Learning Approach : Applies Lorentzian distance metrics for robust pattern matching
Algorithm Selection : Offers multiple prediction methods to suit different market conditions
Real-time Accuracy Tracking : Provides continuous feedback on prediction performance
Forward Projection : Visualizes multiple future bars with configurable display options
Normalized Scale : Presents volume as a percentage of maximum volume for consistent analysis
Interactive Dashboard : Displays key metrics with customizable appearance and placement
🔬 How It Works
The Volume Predictor processes market data through five main steps:
1. Volume Normalization:
Converts raw volume to percentage of maximum volume in lookback period
Creates consistent scale representation across different timeframes and assets
Stores historical normalized volumes for pattern analysis
2. Pattern Detection:
Identifies similar volume patterns in historical data
Uses Lorentzian distance metrics for robust similarity measurement
Determines strength of pattern match for prediction weighting
3. Algorithm Processing:
Applies selected prediction algorithm to historical patterns
For KNN/Lorentzian: Finds K nearest neighbors and calculates weighted prediction
For Ensemble: Combines multiple methods with optimized weighting
For EMA/Linear Regression: Projects trends based on statistical models
4. Accuracy Calculation:
Compares previous predictions to actual outcomes
Calculates average error and prediction accuracy
Updates performance metrics in real-time
5. Visualization:
Displays normalized actual volume with color-coding
Shows current and future volume predictions
Presents performance metrics through interactive dashboard
💡 Note:
The Volume Predictor performs optimally on liquid assets with established volume patterns. It’s most effective when used in conjunction with price action analysis and other technical indicators. The multi-algorithm approach allows adaptation to different market conditions by switching prediction methods. Pay special attention to the accuracy metrics when evaluating prediction reliability, as sudden market changes can temporarily reduce prediction quality. The normalized percentage scale makes the indicator consistent across different assets and timeframes, providing a standardized approach to volume analysis.

AiTrend Pattern Matrix for kNN Forecasting (AiBitcoinTrend)The AiTrend Pattern Matrix for kNN Forecasting (AiBitcoinTrend) is a cutting-edge indicator that combines advanced mathematical modeling, AI-driven analytics, and segment-based pattern recognition to forecast price movements with precision. This tool is designed to provide traders with deep insights into market dynamics by leveraging multivariate pattern detection and sophisticated predictive algorithms.
👽 Core Features
Segment-Based Pattern Recognition
At its heart, the indicator divides price data into discrete segments, capturing key elements like candle bodies, high-low ranges, and wicks. These segments are normalized using ATR-based volatility adjustments to ensure robustness across varying market conditions.
AI-Powered k-Nearest Neighbors (kNN) Prediction
The predictive engine uses the kNN algorithm to identify the closest historical patterns in a multivariate dictionary. By calculating the distance between current and historical segments, the algorithm determines the most likely outcomes, weighting predictions based on either proximity (distance) or averages.
Dynamic Dictionary of Historical Patterns
The indicator maintains a rolling dictionary of historical patterns, storing multivariate data for:
Candle body ranges, High-low ranges, Wick highs and lows.
This dynamic approach ensures the model adapts continuously to evolving market conditions.
Volatility-Normalized Forecasting
Using ATR bands, the indicator normalizes patterns, reducing noise and enhancing the reliability of predictions in high-volatility environments.
AI-Driven Trend Detection
The indicator not only predicts price levels but also identifies market regimes by comparing current conditions to historically significant highs, lows, and midpoints. This allows for clear visualizations of trend shifts and momentum changes.
👽 Deep Dive into the Core Mathematics
👾 Segment-Based Multivariate Pattern Analysis
The indicator analyzes price data by dividing each bar into distinct segments, isolating key components such as:
Body Ranges: Differences between the open and close prices.
High-Low Ranges: Capturing the full volatility of a bar.
Wick Extremes: Quantifying deviations beyond the body, both above and below.
Each segment contributes uniquely to the predictive model, ensuring a rich, multidimensional understanding of price action. These segments are stored in a rolling dictionary of patterns, enabling the indicator to reference historical behavior dynamically.
👾 Volatility Normalization Using ATR
To ensure robustness across varying market conditions, the indicator normalizes patterns using Average True Range (ATR). This process scales each component to account for the prevailing market volatility, allowing the algorithm to compare patterns on a level playing field regardless of differing price scales or fluctuations.
👾 k-Nearest Neighbors (kNN) Algorithm
The AI core employs the kNN algorithm, a machine-learning technique that evaluates the similarity between the current pattern and a library of historical patterns.
Euclidean Distance Calculation:
The indicator computes the multivariate distance across four distinct dimensions: body range, high-low range, wick low, and wick high. This ensures a comprehensive and precise comparison between patterns.
Weighting Schemes: The contribution of each pattern to the forecast is either weighted by its proximity (distance) or averaged, based on user settings.
👾 Prediction Horizon and Refinement
The indicator forecasts future price movements (Y_hat) by predicting logarithmic changes in the price and projecting them forward using exponential scaling. This forecast is smoothed using a user-defined EMA filter to reduce noise and enhance actionable clarity.
👽 AI-Driven Pattern Recognition
Dynamic Dictionary of Patterns: The indicator maintains a rolling dictionary of N multivariate patterns, continuously updated to reflect the latest market data. This ensures it adapts seamlessly to changing market conditions.
Nearest Neighbor Matching: At each bar, the algorithm identifies the most similar historical pattern. The prediction is based on the aggregated outcomes of the closest neighbors, providing confidence levels and directional bias.
Multivariate Synthesis: By combining multiple dimensions of price action into a unified prediction, the indicator achieves a level of depth and accuracy unattainable by single-variable models.
Visual Outputs
Forecast Line (Y_hat_line):
A smoothed projection of the expected price trend, based on the weighted contribution of similar historical patterns.
Trend Regime Bands:
Dynamic high, low, and midlines highlight the current market regime, providing actionable insights into momentum and range.
Historical Pattern Matching:
The nearest historical pattern is displayed, allowing traders to visualize similarities
👽 Applications
Trend Identification:
Detect and follow emerging trends early using dynamic trend regime analysis.
Reversal Signals:
Anticipate market reversals with high-confidence predictions based on historically similar scenarios.
Range and Momentum Trading:
Leverage multivariate analysis to understand price ranges and momentum, making it suitable for both breakout and mean-reversion strategies.
Disclaimer: This information is for entertainment purposes only and does not constitute financial advice. Please consult with a qualified financial advisor before making any investment decisions.

TechniTrend: Advance Custom Candle Finder (CCF)🟦 Description:
The TechniTrend: Advanced Custom Candle Finder (CCF) is a versatile tool designed to help traders identify custom candlestick patterns using various configurable criteria. This indicator provides a flexible framework to filter and highlight specific candles based on volume, volatility, candle characteristics, and other important metrics. Below is a detailed explanation of each filter and its customization options:
🟦 Volume-Based Filters
🔸Volume Spike Filter:
Enable filtering based on volume spikes. Use the Volume Spike Multiplier to define what constitutes a significant increase in volume compared to the average. A spike indicates unusually high trading interest.
🔸Volume Range Filter:
Filter candles based on specific volume ranges. Set Minimum Volume and Maximum Volume thresholds to isolate candles with trading volumes within your desired boundaries.
🟦 Candle Body & Wick Filters
🔸Body Size Filter:
Filter candles based on the size of their body. A Body Size Multiplier determines what is considered a large body relative to historical averages.
🔸Body Percentage Filter:
Filter based on the proportion of the body to the entire candle size. Use the Body Percentage Threshold to highlight candles where the body makes up a certain percentage of the total candle range.
🔸Wick-to-Body Ratio Filter:
Identify candles with specific wick-to-body ratios. A higher Wick-to-Body Ratio can indicate indecision or reversals.
🟦 Volatility & Range Filters
🔸Volatility Filter:
Highlight candles based on price changes relative to volume. The Volatility Multiplier sets the threshold for what is considered a volatile candle.
🔸Candle Range Filter:
Filter based on the range (High - Low) of each candle. Use Minimum Candle Range and Maximum Candle Range to specify your desired candle size in points or pips.
🔸Short-Term and Long-Term Volatility Filters:
Analyze volatility over different periods. Enable Short-Term Volatility or Long-Term Volatility filters to compare recent volatility against historical averages, helping you detect sudden market shifts.
🟦 Candle Color & Open/Close Filters
🔸Candle Color Filter:
Filter based on the candle's color. Choose between Bullish (close > open) or Bearish (close < open) to focus on specific market sentiments.
🔸Open/Close Price Range Filter:
Filter based on the difference between the open and close prices. Use Minimum Open/Close Range and Maximum Open/Close Range to specify your acceptable range in price movements.
🟦 Core Functionality
The CCF indicator combines these filters to provide a final signal whenever a candle meets all the enabled criteria. By default, it highlights any qualifying candle directly on the chart and changes the background color for added visibility.
🟦 Key Features:
🔸Highly Customizable Filters: Adjust the parameters for each filter to tailor the indicator to your specific needs.
🔸Multiple Conditions: Combine several conditions to identify complex candlestick patterns.
🔸Real-Time Alerts: Receive instant notifications when a matching candle pattern is found based on your custom criteria.
🟦 How to Use:
🔸Enable the filters you wish to apply (e.g., Volume Spike, Candle Body Size, Volatility).
🔸Adjust the thresholds for each filter to fine-tune the pattern recognition criteria.
🔸Observe the chart to see visual cues for candles that match your specified conditions.
🟦 Notes:
🔸Ensure that you clearly understand each filter’s role. Over-filtering with very strict criteria may reduce the number of signals.
🔸This indicator is designed to be a customizable tool, not providing buy or sell recommendations.
🔸Use in combination with other analysis tools and indicators for the best results.
Sniffer
╭━━━╮╱╱╱╱╭━╮╭━╮
┃╭━╮┃╱╱╱╱┃╭╯┃╭╯
┃╰━━┳━╮╭┳╯╰┳╯╰┳━━┳━╮
╰━━╮┃╭╮╋╋╮╭┻╮╭┫┃━┫╭╯
┃╰━╯┃┃┃┃┃┃┃╱┃┃┃┃━┫┃
╰━━━┻╯╰┻╯╰╯╱╰╯╰━━┻╯
Overview
A vast majority of modern data analysis & modelling techniques rely upon the idea of hidden patterns, wether it is some type of visualisation tool or some form of a complex machine learning algorithm, the one thing that they have in common is the belief, that patterns tell us what’s hidden behind plain numbers. The same philosophy has been adopted by many traders & investors worldwide, there’s an entire school of thought that operates purely based on chart patterns. This is where Sniffer comes in, it is a tool designed to simplify & quantify the job of pattern recognition on any given price chart, by combining various factors & techniques that generate high-quality results.
This tool analyses bars selected by the user, and highlights bar clusters on the chart that exhibit similar behaviour across multiple dimensions. It can detect a single candle pattern like hammers or dojis, or it can handle multiple candles like morning/evening stars or double tops/bottoms, and many more. In fact, the tool is completely independent of such specific candle formations, instead, it works on the idea of vector similarity and generates a degree of similarity for every single combination of candles. Only the top-n matches are highlighted, users get to choose which patterns they want to analyse and to what degree, by customising the feature-space.
Background
In the world of trading, a common use-case is to scan a price chart for some specific candlestick formations & price structures, and then the chart is further analysed in reference to these events. Traders are often trying to answer questions like, when was the last time price showed similar behaviour, what are the instances similar to what price is doing right now, what happens when price forms a pattern like this, what were some of other indicators doing when this happened last(RSI, CCI, ADX etc), and many other abstract ideas to have a stronger confluence or to confirm a bias.Having such a context can be vital in making better informed decisions, but doing this manually on a chart that has thousands of candles can have many disadvantages. It’s tedious, human errors are rather likely, and even if it’s done with pin-point accuracy, chances are that we’ll miss out on many pieces of information. This is the thought that gave birth to Sniffer .
Sniffer tries to provide a general solution for pattern-based analysis by deploying vector-similarity computation techniques, that cover the full-breadth of a price chart and generate a list of top-n matches based on the criteria selected by the user. Most of these techniques come from the data science space, where vector similarity is often implemented to solve classification & clustering problems. Sniffer uses same principles of vector comparison, and computes a degree of similarity for every single candle formation within the selected range, and as a result generates a similarity matrix that captures how similar or dissimilar a set of candles is to the input set selected by the user.
How It Works
A brief overview of how the tool is implemented:
- Every bar is processed, and a set of features are mapped to it.
- Bars selected by the user are captured, and saved for later use.
- Once the all the bars have been processed, candles are back-tracked and degree of similarity is computed for every single bar(max-limit is 5000 bars).
- Degree of similarity is computed by comparing attributes like price range, candle breadth & volume etc.
- Similarity matrix is sorted and top-n results are highlighted on the chart through boxes of different colors.
A brief overview of the features space for bars:
- Range: Difference between high & low
- Body: Difference between close & open
- Volume: Traded volume for that candle
- Head: Upper wick for green candles & lower wick for red candles
- Tail: Lower wick for green candles & upper wick for red candles
- BTR: Body to Range ratio
- HTR: Head to Range ratio
- TTR: Tail to Range ratio
- HTB: Head to Body ratio
- TTB: Tail to Body ratio
- ROC: Rate of change for HL2 for four different periods
- RSI: Relative Strength Index
- CCI: Commodity Channel Index
- Stochastic: Stochastic Index
- ADX: DMI+, DMI- & ADX
A brief overview of how degree of similarity is calculated:
- Each bar set is compared to the inout bar set within the selected feature space
- Features are represented as vectors, and distance between the vectors is calculated
- Shorter the distance, greater the similarity
- Different distance calculation methods are available to choose from, such as Cosine, Euclidean, Lorentzian, Manhattan, & Pearson
- Each method is likely to generate slightly different results, users are expected to select the method & the feature space that best fits their use-case
How To Use It
- Usage of this tool is relatively straightforward, users can add this indicator to their chart and similar clusters will be highlighted automatically
- Users need to select a time range that will be treated as input, and bars within that range become the input formation for similarity calculations
- Boxes will be draw around the clusters that fit the matching criteria
- Boxes are color-coded, green color boxes represent the top one-third of the top-n matches, yellow boxes represent the middle third, red boxes are for bottom third, and white box represents user-input
- Boxes colors will be adjusted as you adjust input parameters, such as number of matches or look-back period
User Settings
Users can configure the following options:
- Select the time-range to set input bars
- Select the look-back period, number of candles to backtrack for similarity search
- Select the number of top-n matches to show on the chart
- Select the method for similarity calculation
- Adjust the feature space, this enables addition of custom features, such as pattern recognition, technical indicators, rate of change etc
- Toggle verbosity, shows degree of similarity as a percentage value inside the box
Top Features
- Pattern Agnostic: Designed to work with variable number of candles & complex patterns
- Customisable Feature Space: Users get to add custom features to each bar
- Comprehensive Comparison: Generates a degree of similarity for all possible combinations
Final Note
- Similarity matches will be shown only within last 4500 bars.
- In theory, it is possible to compute similarity for any size candle formations, indicator has been tested with formations of 50+ candles, but it is recommended to select smaller range for faster & cleaner results.
- As you move to smaller time frames, selected time range will provide a larger number of candles as input, which can produce undesired results, it is advised to adjust your selection when you change time frames. Seeking suggestions on how to directly receive bars as user input, instead of time range.
- At times, users may see array index out of bound error when setting up this indicator, this generally happens when the input range is not properly configured. So, it should disappear after you select the input range, still trying to figure out where it is coming from, suggestions are welcome.
Credits
- @HeWhoMustNotBeNamed for publishing such a handy PineScript Logger, it certainly made the job a lot easier.

FunctionPatternDecompositionLibrary "FunctionPatternDecomposition"
Methods for decomposing price into common grid/matrix patterns.
series_to_array(source, length) Helper for converting series to array.
Parameters:
source : float, data series.
length : int, size.
Returns: float array.
smooth_data_2d(data, rate) Smooth data sample into 2d points.
Parameters:
data : float array, source data.
rate : float, default=0.25, the rate of smoothness to apply.
Returns: tuple with 2 float arrays.
thin_points(data_x, data_y, rate) Thin the number of points.
Parameters:
data_x : float array, points x value.
data_y : float array, points y value.
rate : float, default=2.0, minimum threshold rate of sample stdev to accept points.
Returns: tuple with 2 float arrays.
extract_point_direction(data_x, data_y) Extract the direction each point faces.
Parameters:
data_x : float array, points x value.
data_y : float array, points y value.
Returns: float array.
find_corners(data_x, data_y, rate) ...
Parameters:
data_x : float array, points x value.
data_y : float array, points y value.
rate : float, minimum threshold rate of data y stdev.
Returns: tuple with 2 float arrays.
grid_coordinates(data_x, data_y, m_size) transforms points data to a constrained sized matrix format.
Parameters:
data_x : float array, points x value.
data_y : float array, points y value.
m_size : int, default=10, size of the matrix.
Returns: flat 2d pseudo matrix.

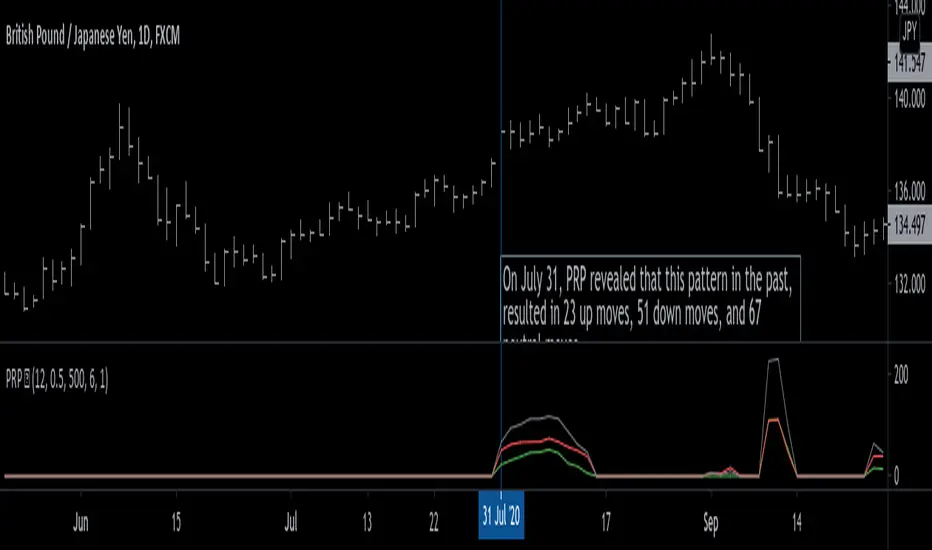
Pattern Recognition Probabilities [racer8]Brief 🌟
Pattern Recognition Probabilities (PRP) is a REALLY smart indicator. It uses the correlation coefficient formula to determine if the current set of bars resembles that of past patterns. It counts the number of times the current pattern has occurred in the past and looks at how it performed historically to determine the probability of an up move, down move, or neutral move.
I'd like to say, I'm proud of this indicator 😆🤙 This is the SMARTEST indicator I have ever made 🧠🧠🧠
Note: PRP doesn't give you actual probabilities, but gives you instead the historical occurrences of up, down, and neutral moves that resulted after the pattern. So you can calculate probabilities based on these valuable statistics. So for example, PRP can tell you this pattern has historically resulted in 55 up moves, 20 down moves, and 60 neutral moves.
Parameters 🌟
You can adjust the Pattern length, Minimum correlation, Statistics lookback, Exit after time, and Atr multiplier parameters.
Pattern length - determines how long the pattern is
Minimum correlation - determines the minimum correlation coefficient needed to pass as a similiar enough pattern.
Statistics lookback - lookback period for gathering all the patterns in the past.
Exit after time - determines when exit occurred (number of periods after pattern) ; is the point that represents the pattern's result.
Atr multiplier - determines minimum atr move needed to qualify whether result was an up/down move or a neutral move. If a particular historical pattern resulted in a move that was less than the min atr, then it is recorded as a neutral move in the statistics.
Thanks for reading! 🙏
Good luck 🍀 Stay safe 😷 Drink lots of water💧
Enjoy! 🥳 and Hit the like button! 👍
Test: Pattern RecognitionEXPERIMENTAL:
a test on how to compare price at different frequency's with static patterns.
