Standard Deviation based Upper Lower RangeThis script makes use of historical data for finding the standard deviation on daily returns. Based on the mean and standard deviation, the upper and lower range for the stock is shown upto 2x standard deviation. These bounds can be treated as volatility range for the next n trading sessions. This volatility is based on historical data. Users can change the lookback historical period, and can also set the time period (days) for upcoming trading sessions.
This indicator can be useful in determining stoploss and target levels along with the traditional support/resistance levels. It can also be useful in option trading where one needs to determine a range beyond which it is safe to sell an option.
A range of 1 SD has around 65% to 68% probability that it will not be breached. A range of 2 SD has around 95% probability that it will not be breached.
The indicator is based on Normal distribution theory. In future editions, I envision to also calculate the skewness and kurtosis so that we can determine if a stock is properly following Normal Distribution theory. That may further favor the calculated range.
Mean

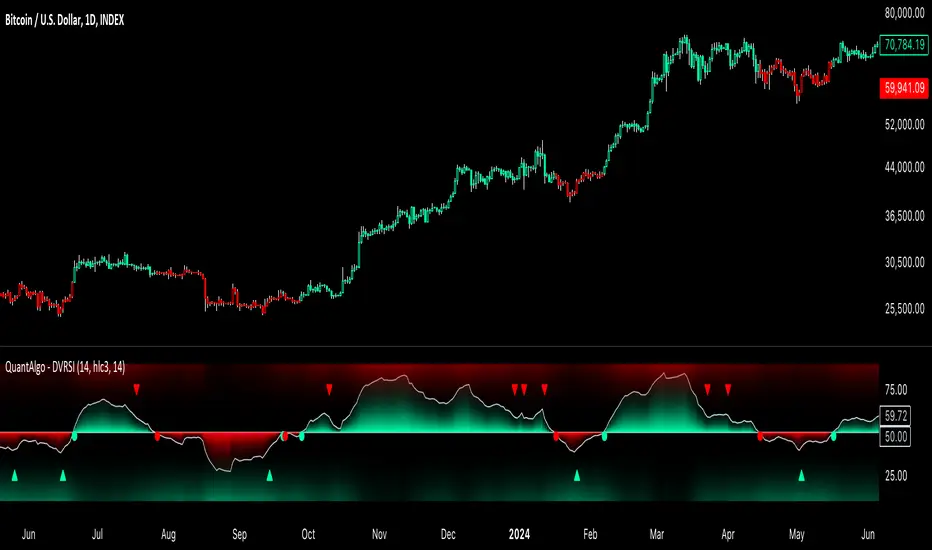
Dynamic Volume RSI (DVRSI) [QuantAlgo]Introducing the Dynamic Volume RSI (DVRSI) by QuantAlgo 📈✨
Elevate your trading and investing strategies with the Dynamic Volume RSI (DVRSI) , a powerful tool designed to provide clear insights into market momentum and trend shifts. This indicator is ideal for traders and investors who want to stay ahead of the curve by using volume-responsive calculations and adaptive smoothing techniques to enhance signal clarity and reliability.
🌟 Key Features:
🛠 Customizable RSI Settings: Tailor the indicator to your strategy by adjusting the RSI length and price source. Whether you’re focused on short-term trades or long-term investments, DVRSI adapts to your needs.
🌊 Adaptive Smoothing: Enable adaptive smoothing to filter out market noise and ensure cleaner signals in volatile or choppy market conditions.
🎨 Dynamic Color-Coding: Easily identify bullish and bearish trends with color-coded candles and RSI plots, offering clear visual cues to track market direction.
⚖️ Volume-Responsive Adjustments: The DVRSI reacts to volume changes, giving greater significance to high-volume price moves and improving the accuracy of trend detection.
🔔 Custom Alerts: Stay informed with alerts for key RSI crossovers and trend changes, allowing you to act quickly on emerging opportunities.
📈 How to Use:
✅ Add the Indicator: Set up the DVRSI by adding it to your chart and customizing the RSI length, price source, and smoothing options to fit your specific strategy.
👀 Monitor Visual Cues: Watch for trend shifts through the color-coded plot and candles, signaling changes in momentum as the RSI crosses key levels.
🔔 Set Alerts: Configure alerts for critical RSI crossovers, such as the 50 line, ensuring you stay on top of potential market reversals and opportunities.
🔍 How It Works:
The Dynamic Volume RSI (DVRSI) is a unique indicator designed to provide more accurate and responsive signals by incorporating both price movement and volume sensitivity into the RSI framework. It begins by calculating the traditional RSI values based on a user-defined length and price source, but unlike standard RSI tools, the DVRSI applies volume-weighted adjustments to reflect the strength of market participation.
The indicator dynamically adjusts its sensitivity by factoring in volume to the RSI calculation, which means that price moves backed by higher volumes carry more weight, making the signal more reliable. This method helps identify stronger trends and reduces the risk of false signals in low-volume environments. To further enhance accuracy, the DVRSI offers an adaptive smoothing option that allows users to reduce noise during periods of market volatility. This adaptive smoothing function responds to market conditions, providing a cleaner signal by reducing erratic movements or price spikes that could lead to misleading signals.
Additionally, the DVRSI uses dynamic color-coding to visually represent the strength of bullish or bearish trends. The candles and RSI plots change color based on the RSI values crossing critical thresholds, such as the 50 level, offering an intuitive way to recognize trend shifts. Traders can also configure alerts for specific RSI crossovers (e.g., above 50 or below 40), ensuring that they stay informed of potential trend reversals and significant market shifts in real-time.
The combination of volume sensitivity, adaptive smoothing, and dynamic trend visualization makes the DVRSI a robust and versatile tool for traders and investors looking to fine-tune their market analysis. By incorporating both price and volume data, this indicator delivers more precise signals, helping users make informed decisions with greater confidence.
Disclaimer:
The Dynamic Volume RSI is designed to enhance your market analysis but should not be used as a sole decision-making tool. Always consider multiple factors before making any trading or investment decisions. Past performance is not indicative of future results.
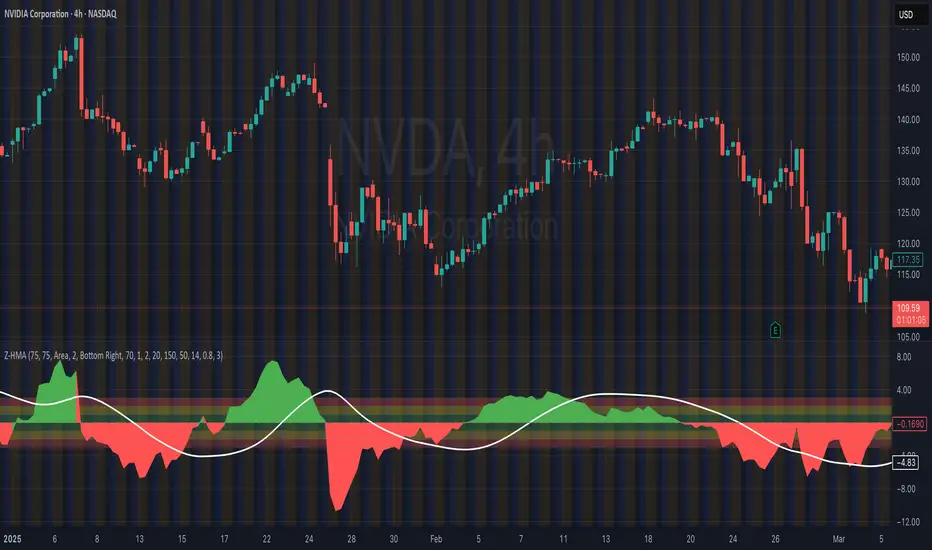
HMA Z-Score Probability Indicator by Erika BarkerThis indicator is a modified version of SteverSteves's original work, enhanced by Erika Barker. It visually represents asset price movements in terms of standard deviations from a Hull Moving Average (HMA), commonly known as a Z-Score.
Key Features:
Z-Score Calculation: Measures how many standard deviations the current price is from its HMA.
Hull Moving Average (HMA): This moving average provides a more responsive baseline for Z-Score calculations.
Flexible Display: Offers both area and candlestick visualization options for the Z-Score.
Probability Zones: Color-coded areas showing the statistical likelihood of prices based on their Z-Score.
Dynamic Price Level Labels: Displays actual price levels corresponding to Z-Score values.
Z-Table: An optional table showing the probability of occurrence for different Z-Score ranges.
Standard Deviation Lines: Horizontal lines at each standard deviation level for easy reference.
How It Works:
The indicator calculates the Z-Score by comparing the current price to its HMA and dividing by the standard deviation. This Z-Score is then plotted on a separate pane below the main chart.
Green areas/candles: Indicate prices above the HMA (positive Z-Score)
Red areas/candles: Indicate prices below the HMA (negative Z-Score)
Color-coded zones:
Green: Within 1 standard deviation (high probability)
Yellow: Between 1 and 2 standard deviations (medium probability)
Red: Beyond 2 standard deviations (low probability)
The HMA line (white) shows the trend of the Z-Score itself, offering insight into whether the asset is becoming more or less volatile over time.
Customization Options:
Adjust lookback periods for Z-Score and HMA calculations
Toggle between area and candlestick display
Show/hide probability fills, Z-Table, HMA line, and standard deviation bands
Customize text color and decimal rounding for price levels
Interpretation:
This indicator helps traders identify potential overbought or oversold conditions based on statistical probabilities. Extreme Z-Score values (beyond ±2 or ±3) often suggest a higher likelihood of mean reversion, while consistent Z-Scores in one direction may indicate a strong trend.
By combining the Z-Score with the HMA and probability zones, traders can gain a nuanced understanding of price movements relative to recent trends and their statistical significance.
Dickey-Fuller Test for Mean Reversion and Stationarity **IF YOU NEED EXTRA SPECIAL HELP UNDERSTANDING THIS INDICATOR, GO TO THE BOTTOM OF THE DESCRIPTION FOR AN EVEN SIMPLER DESCRIPTION**
Dickey Fuller Test:
The Dickey-Fuller test is a statistical test used to determine whether a time series is stationary or has a unit root (a characteristic of a time series that makes it non-stationary), indicating that it is non-stationary. Stationarity means that the statistical properties of a time series, such as mean and variance, are constant over time. The test checks to see if the time series is mean-reverting or not. Many traders falsely assume that raw stock prices are mean-reverting when they are not, as evidenced by many different types of statistical models that show how stock prices are almost always positively autocorrelated or statistical tests like this one, which show that stock prices are not stationary.
Note: This indicator uses past results, and the results will always be changing as new data comes in. Just because it's stationary during a rare occurrence doesn't mean it will always be stationary. Especially in price, where this would be a rare occurrence on this test. (The Test Statistic is below the critical value.)
The indicator also shows the option to either choose Raw Price, Simple Returns, or Log Returns for the test.
Raw Prices:
Stock prices are usually non-stationary because they follow some type of random walk, exhibiting positive autocorrelation and trends in the long term.
The Dickey-Fuller test on raw prices will indicate non-stationary most of the time since prices are expected to have a unit root. (If the test statistic is higher than the critical value, it suggests the presence of a unit root, confirming non-stationarity.)
Simple Returns and Log Returns:
Simple and log returns are more stationary than prices, if not completely stationary, because they measure relative changes rather than absolute levels.
This test on simple and log returns may indicate stationary behavior, especially over longer periods. (The test statistic being below the critical value suggests the absence of a unit root, indicating stationarity.)
Null Hypothesis (H0): The time series has a unit root (it is non-stationary).
Alternative Hypothesis (H1): The time series does not have a unit root (it is stationary)
Interpretation: If the test statistic is less than the critical value, we reject the null hypothesis and conclude that the time series is stationary.
Types of Dickey-Fuller Tests:
1. (What this indicator uses) Standard Dickey-Fuller Test:
Tests the null hypothesis that a unit root is present in a simple autoregressive model.
This test is used for simple cases where we just want to check if the series has a consistent statistical property over time without considering any trends or additional complexities.
It examines the relationship between the current value of the series and its previous value to see if the series tends to drift over time or revert to the mean.
2. Augmented Dickey-Fuller (ADF) Test:
Tests for a unit root while accounting for more complex structures like trends and higher-order correlations in the data.
This test is more robust and is used when the time series has trends or other patterns that need to be considered.
It extends the regular test by including additional terms to account for the complexities, and this test may be more reliable than the regular Dickey-Fuller Test.
For things like stock prices, the ADF would be more appropriate because stock prices are almost always trending and positively autocorrelated, while the Dickey-Fuller Test is more appropriate for more simple time series.
Critical Values
This indicator uses the following critical values that are essential for interpreting the Dickey-Fuller test results. The critical values depend on the chosen significance levels:
1% Significance Level: Critical value of -3.43.
5% Significance Level: Critical value of -2.86.
10% Significance Level: Critical value of -2.57.
These critical values are thresholds that help determine whether to reject the null hypothesis of a unit root (non-stationarity). If the test statistic is less than (or more negative than) the critical value, it indicates that the time series is stationary. Conversely, if the test statistic is greater than the critical value, the series is considered non-stationary.
This indicator uses a dotted blue line by default to show the critical value. If the test-static, which is the gray column, goes below the critical value, then the test-static will become yellow, and the test will indicate that the time series is stationary or mean reverting for the current period of time.
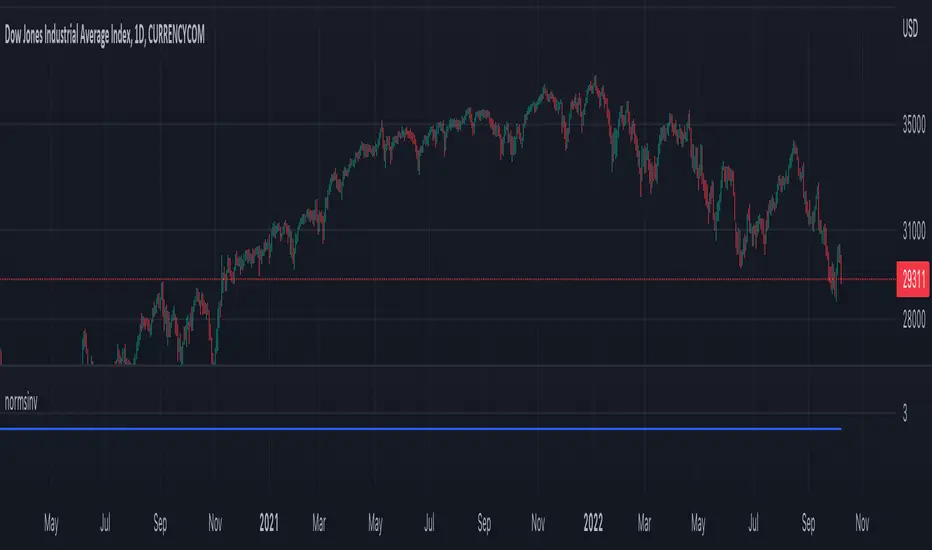
What does this mean?
This is the weekly chart of BTCUSD with the Dickey-Fuller Test, with a length of 100 and a critical value of 1%.
So basically, in the long term, mean-reversion strategies that involve raw prices are not a good idea. You don't really need a statistical test either for this; just from seeing the chart itself, you can see that prices in the long term are trending and no mean reversion is present.
For the people who can't understand that the gray column being above the blue dotted line means price doesn't mean revert, here is a more simple description (you know you are):
Average (I have to include the meaning because they may not know what average is): The middle number is when you add up all the numbers and then divide by how many numbers there are. EX: If you have the numbers 2, 4, and 6, you add them up to get 12, and then divide by 3 (because there are 3 numbers), so the average is 4. It tells you what a typical number is in a group of numbers.
This indicator checks if a time series (like stock prices) tends to return to its average value or time.
Raw prices, which is just the regular price chart, are usually not mean-reverting (It's "always" positively autocorrelating but this group of people doesn't like that word). Price follows trends.
Simple returns and log returns are more likely to have periods of mean reversion.
How to use it:
Gray Column (the gray bars) Above the Blue Dotted Line: The price does not mean revert (non-stationary).
Gray Column Below Blue Line: The time series mean reverts (stationary)
So, if the test statistic (gray column) is below the critical value, which is the blue dotted line, then the series is stationary and mean reverting, but if it is above the blue dotted line, then the time series is not stationary or mean reverting, and strategies involving mean reversion will most likely result in a loss given enough occurrences.

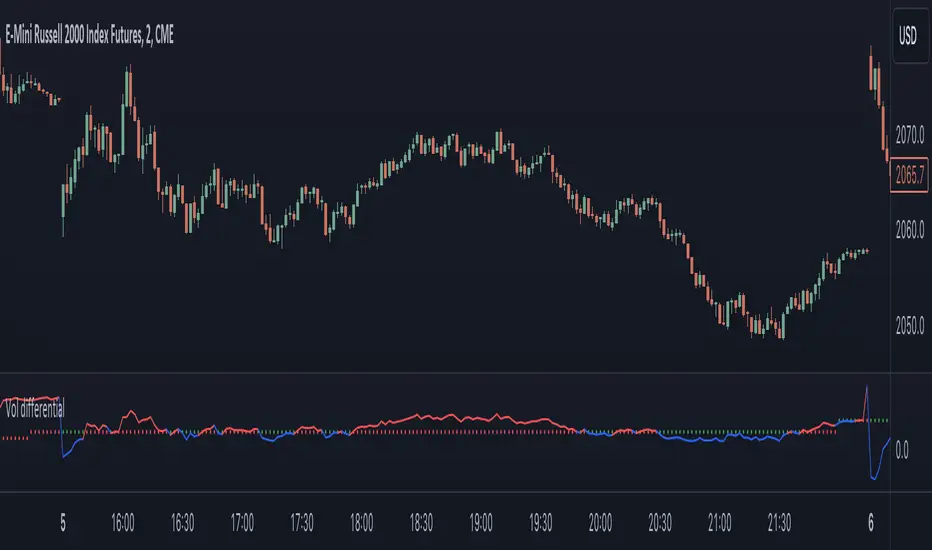
Realized volatility differentialAbout
This is a simple indicator that takes into account two types of realized volatility: Close-Close and High-Low (the latter is more useful for intraday trading).
The output of the indicator is two values / plots:
an average of High-Low volatility minus Close-Close volatility (10day period is used as a default)
the current value of the indicator
When the current value is:
lower / below the average, then it means that High-Low volatility should increase.
higher / above then obviously the opposite is true.
How to use it
It might be used as a timing tool for mean reversion strategies = when your primary strategy says a market is in mean reversion mode, you could use it as a signal for opening a position.
For example: let's say a security is in uptrend and approaching an important level (important to you).
If the current value is:
above the average, a short position can be opened, as High-Low volatility should decrease;
below the average, a trend should continue.
Intended securities
Futures contracts
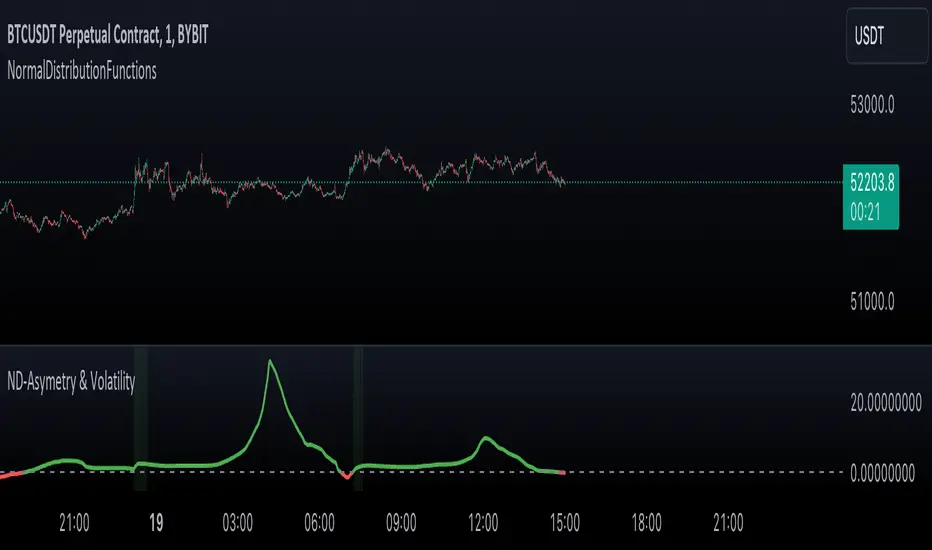
NormalDistributionFunctionsLibrary "NormalDistributionFunctions"
The NormalDistributionFunctions library encompasses a comprehensive suite of statistical tools for financial market analysis. It provides functions to calculate essential statistical measures such as mean, standard deviation, skewness, and kurtosis, alongside advanced functionalities for computing the probability density function (PDF), cumulative distribution function (CDF), Z-score, and confidence intervals. This library is designed to assist in the assessment of market volatility, distribution characteristics of asset returns, and risk management calculations, making it an invaluable resource for traders and financial analysts.
meanAndStdDev(source, length)
Calculates and returns the mean and standard deviation for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
length (int) : int: The lookback period for the calculation.
Returns: Returns an array where the first element is the mean and the second element is the standard deviation of the data series for the given period.
skewness(source, mean, stdDev, length)
Calculates and returns skewness for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns skewness value
kurtosis(source, mean, stdDev, length)
Calculates and returns kurtosis for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns kurtosis value
pdf(x, mean, stdDev)
pdf: Calculates the probability density function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the PDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the probability density function value for x.
cdf(x, mean, stdDev)
cdf: Calculates the cumulative distribution function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the CDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the cumulative distribution function value for x.
confidenceInterval(mean, stdDev, size, confidenceLevel)
Calculates the confidence interval for a data series mean.
Parameters:
mean (float) : float: The mean of the data series.
stdDev (float) : float: The standard deviation of the data series.
size (int) : int: The sample size.
confidenceLevel (float) : float: The confidence level (e.g., 0.95 for 95% confidence).
Returns: Returns the lower and upper bounds of the confidence interval.
Geometrical Mean Moving AverageThe geometric moving average is a type of moving average that calculates the geometric mean of the previous n-periods of the price time series. Unlike the simple moving average that uses the arithmetic mean to continuously calculate the moving average as new price data comes in, the geometric moving average uses the geometric mean formula to get the moving average of the price data as new ones come in.
Why use a geometric moving average?
The geometric moving average differs from the simple moving average in how it is calculated. Most importantly, the geometric mean takes into account the compounding that occurs from period to period.
How can you use a geometric mean moving average?
You can use the GMMA just as you would use any other moving average indicator. You can use it to identify the direction of the trend, and in this case, it can also serve as a support level during an uptrend or a resistance level during a downtrend.
Drawbacks with a geometric moving average
Just like other moving average indicators, the GMA has limitations. Some of them are as follows:
It lags because it uses past price data.
It is pretty useless when the price action is choppy or moving predominantly sideways. During such periods, it can give multiple false signals.
Median of Means Estimator Median of Means (MoM) is a measure of central tendency like mean (average) and median. However, it could be a better and robust estimator of central tendency when the data is not normal, asymmetric, have fat tails (like stock price data) and have outliers. The MoM can be used as a robust trend following tool and in other derived indicators.
Median of means (MoM) is calculated as follows, the MoM estimator shuffles the "n" data points and then splits them into k groups of m data points (n= k*m). It then computes the Arithmetic Mean of each group (k). Finally, it calculate the median over the resulting k Arithmetic Means. This technique diminishes the effect that outliers have on the final estimation by splitting the data and only considering the median of the resulting sub-estimations. This preserves the overall trend despite the data shuffle.
Below is an example to illustrate the advantages of MoM
Set A Set B Set C
3 4 4
3 4 4
3 5 5
3 5 5
4 5 5
4 5 5
5 5 5
5 5 5
6 6 8
6 6 8
7 7 10
7 7 15
8 8 40
9 9 50
10 100 100
Median 5 5 5
Mean 5.5 12.1 17.9
MoM 5.7 6.0 17.3
For all three sets the median is the same, though set A and B are the same except for one outlier in set B (100) it skews the mean but the median is resilient. However, in set C the group has several high values despite that the median is not responsive and still give 5 as the central tendency of the group, but the median of means is a value of 17.3 which is very close to the group mean 17.9. In all three cases (set A, B and C) the MoM provides a better snapshot of the central tendency of the group. Note: The MoM is dependent on the way we split the data initially and the value might slightly vary when the randomization is done sevral time and the resulting value can give the confidence interval of the MoM estimator.
Relational Quadratic Kernel Channel [Vin]The Relational Quadratic Kernel Channel (RQK-Channel-V) is designed to provide more valuable potential price extremes or continuation points in the price trend.
Example:
Usage:
Lookback Window: Adjust the "Lookback Window" parameter to control the number of previous bars considered when calculating the Rational Quadratic Estimate. Longer windows capture longer-term trends, while shorter windows respond more quickly to price changes.
Relative Weight: The "Relative Weight" parameter allows you to control the importance of each data point in the calculation. Higher values emphasize recent data, while lower values give more weight to historical data.
Source: Choose the data source (e.g., close price) that you want to use for the kernel estimate.
ATR Length: Set the length of the Average True Range (ATR) used for channel width calculation. A longer ATR length results in wider channels, while a shorter length leads to narrower channels.
Channel Multipliers: Adjust the "Channel Multiplier" parameters to control the width of the channels. Higher multipliers result in wider channels, while lower multipliers produce narrower channels. The indicator provides three sets of channels, each with its own multiplier for flexibility.
Details:
Rational Quadratic Kernel Function:
The Rational Quadratic Kernel Function is a type of smoothing function used to estimate a continuous curve or line from discrete data points. It is often used in time series analysis to reduce noise and emphasize trends or patterns in the data.
The formula for the Rational Quadratic Kernel Function is generally defined as:
K(x) = (1 + (x^2) / (2 * α * β))^(-α)
Where:
x represents the distance or difference between data points.
α and β are parameters that control the shape of the kernel. These parameters can be adjusted to control the smoothness or flexibility of the kernel function.
In the context of this indicator, the Rational Quadratic Kernel Function is applied to a specified source (e.g., close prices) over a defined lookback window. It calculates a smoothed estimate of the source data, which is then used to determine the central value of the channels. The kernel function allows the indicator to adapt to different market conditions and reduce noise in the data.
The specific parameters (length and relativeWeight) in your indicator allows to fine-tune how the Rational Quadratic Kernel Function is applied, providing flexibility in capturing both short-term and long-term trends in the data.
To know more about unsupervised ML implementations, I highly recommend to follow the users, @jdehorty and @LuxAlgo
Optimizing the parameters:
Lookback Window (length): The lookback window determines how many previous bars are considered when calculating the kernel estimate.
For shorter-term trading strategies, you may want to use a shorter lookback window (e.g., 5-10).
For longer-term trading or investing, consider a longer lookback window (e.g., 20-50).
Relative Weight (relativeWeight): This parameter controls the importance of each data point in the calculation.
A higher relative weight (e.g., 2 or 3) emphasizes recent data, which can be suitable for trend-following strategies.
A lower relative weight (e.g., 1) gives more equal importance to historical and recent data, which may be useful for strategies that aim to capture both short-term and long-term trends.
ATR Length (atrLength): The length of the Average True Range (ATR) affects the width of the channels.
Longer ATR lengths result in wider channels, which may be suitable for capturing broader price movements.
Shorter ATR lengths result in narrower channels, which can be helpful for identifying smaller price swings.
Channel Multipliers (channelMultiplier1, channelMultiplier2, channelMultiplier3): These parameters determine the width of the channels relative to the ATR.
Adjust these multipliers based on your risk tolerance and desired channel width.
Higher multipliers result in wider channels, which may lead to fewer signals but potentially larger price movements.
Lower multipliers create narrower channels, which can result in more frequent signals but potentially smaller price movements.

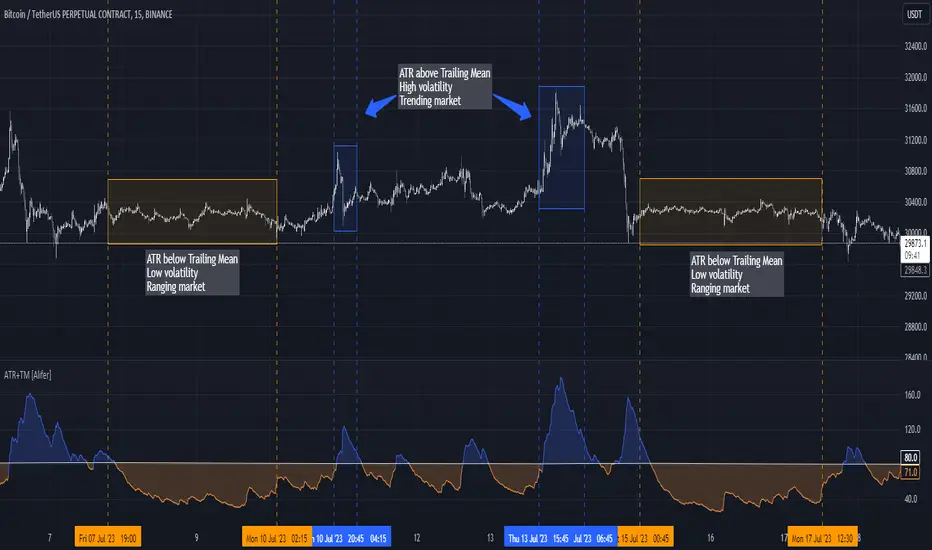
Average True Range Trailing Mean [Alifer]Upgrade of the Average True Range default indicator by TradingView. It adds and plots a trailing mean to show periods of increased volatility more clearly.
ATR TRAILING MEAN
A trailing mean, also known as a moving average, is a statistical calculation used to smooth out data over time and identify trends or patterns in a time series.
In our indicator, it clearly shows when the ATR value spikes outside of it's average range, making it easier to identify periods of increased volatility.
Here's how the ATR Trailing Mean (atr_mean) is calculated:
atr_mean = ta.cum(atr) / (bar_index + 1) * atr_mult
The ta.cum() function calculates the cumulative sum of the ATR over all bars up to the current bar.
(bar_index + 1) represents the number of bars processed up to the current bar, including the current one.
By dividing the cumulative ATR ta.cum(atr) by (bar_index + 1) and then multiplying it by atr_mult (Multiplier), we obtain the ATR Trailing Mean value.
If atr_mult is set to 1.0, the ATR Trailing Mean will be equal to the simple average of the ATR values, and it will follow the ATR's general trend.
However, if atr_mult is increased, the ATR Trailing Mean will react more strongly to the ATR's recent changes, making it more sensitive to short-term fluctuations.
On the other hand, reducing atr_mult will make the ATR Trailing Mean less responsive to recent changes in ATR, making it smoother and less prone to reacting to short-term volatility.
In summary, adjusting the atr_mult input allows traders to fine-tune the ATR Trailing Mean's responsiveness based on their preferred level of sensitivity to recent changes in market volatility.
IMPLEMENTATION IN A STRATEGY
You can easily implement this indicator in an existing strategy, to only enter positions when the ATR is above the ATR Trailing Mean (with Multiplier-adjusted sensitivity). To do so, add the following lines of codes.
Under Inputs:
length = input.int(title="Length", defval=20, minval=1)
atr_mult = input.float(defval=1.0, step = 0.1, title = "Multiplier", tooltip = "Adjust the sensitivity of the ATR Trailing Mean line.")
smoothing = input.string(title="Smoothing", defval="RMA", options= )
ma_function(source, length) =>
switch smoothing
"RMA" => ta.rma(source, length)
"SMA" => ta.sma(source, length)
"EMA" => ta.ema(source, length)
=> ta.wma(source, length)
This will allow you to define the Length of the ATR (lookback length over which the ATR is calculated), the Multiplier to adjust the Trailing Mean's sensitivity and the type of Smoothing to be used for the ATR.
Under Calculations:
atr= ma_function(ta.tr(true), length)
atr_mean = ta.cum(atr) / (bar_index+1) * atr_mult
This will calculate the ATR based on Length and Smoothing, and the resulting ATR Trailing Mean.
Under Entry Conditions, add the following to your existing conditions:
and atr > atr_mean
This will make it so that entries are only triggered when the ATR is above the ATR Trailing Mean (adjusted by the Multiplier value you defined earlier).
ATR - DEFINITION AND HISTORY
The Average True Range (ATR) is a technical indicator used to measure market volatility, regardless of the direction of the price. It was developed by J. Welles Wilder and introduced in his book "New Concepts in Technical Trading Systems" in 1978. ATR provides valuable insights into the degree of price movement or volatility experienced by a financial asset, such as a stock, currency pair, commodity, or cryptocurrency, over a specific period.
ATR - CALCULATION AND USAGE
The ATR calculation involves three components:
1 — True Range (TR): The True Range is a measure of the asset's price movement for a given period. It takes into account the following factors:
The difference between the high and low prices of the current period.
The absolute value of the difference between the high price of the current period and the closing price of the previous period.
The absolute value of the difference between the low price of the current period and the closing price of the previous period.
Mathematically, the True Range (TR) for the current period is calculated as follows:
TR = max(high - low, abs(high - previous_close), abs(low - previous_close))
2 — ATR Calculation: The ATR is calculated as a Moving Average (MA) of the True Range over a specified period.
The ATR is calculated as follows:
ATR = MA(TR, length)
3 — ATR Interpretation: The ATR value represents the average volatility of the asset over the chosen period. Higher ATR values indicate higher volatility, while lower ATR values suggest lower volatility.
Traders and investors can use ATR in various ways:
Setting Stop Loss and Take Profit Levels: ATR can help determine appropriate stop-loss and take-profit levels in trading strategies. A larger ATR value might require wider stop-loss levels to allow for the asset's natural price fluctuations, while a smaller ATR value might allow for tighter stop-loss levels.
Identifying Market Volatility: A sharp increase in ATR might indicate heightened market uncertainty or the potential for significant price movements. Conversely, a decreasing ATR might suggest a period of low volatility and possible consolidation.
Comparing Volatility Between Assets: Since ATR uses absolute values, it shouldn't be used to compare volatility between different assets, as assets with higher prices will consistently have higher ATR values, while assets with lower prices will consistently have lower ATR values. However, the addition of a trailing mean makes such a comparison possible. An asset whose ATR is consistently close to its ATR Trailing Mean will have a lower volatility than an asset whose ATR continuously moves far above and below its ATR Trailing Mean. This can help traders and investors decide which markets to trade based on their risk tolerance and trading strategies.
Determining Position Size: ATR can be used to adjust position sizes, taking into account the asset's volatility. Smaller position sizes might be appropriate for more volatile assets to manage risk effectively.
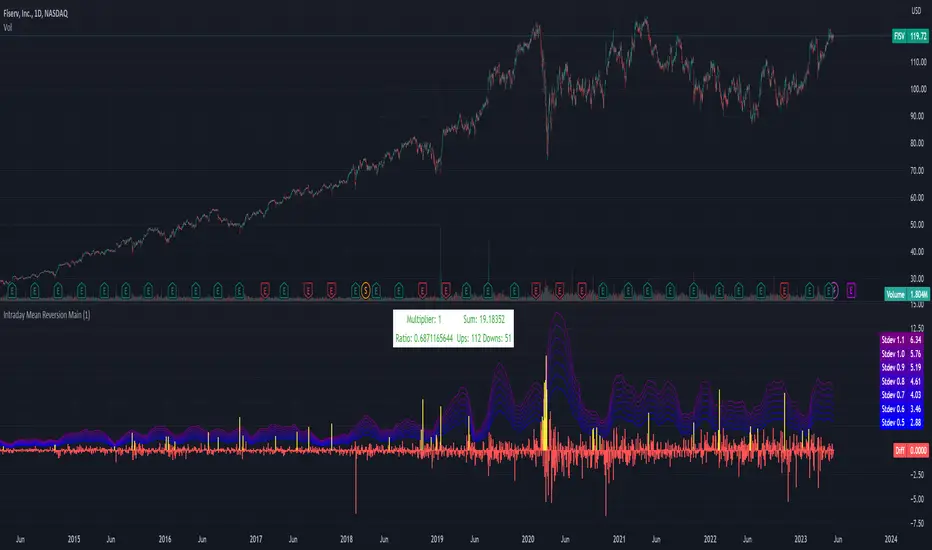
Intraday Mean Reversion MainThe Intraday Mean Reversion Indicator works well on certain stocks. It should be used for day trading stocks but need to be applied on the Day to Day timeframe.
The logic behind the indicator is that stocks that opens substantially lower than yesterdays close, very often bounces back during the day and closes higher than the open price, thus the name Intraday Mean reversal. The stock so to speak, reverses to the mean.
The indicator has 7 levels to choose from:
0.5 * standard deviation
0.6 * standard deviation
0.7 * standard deviation
0.8 * standard deviation
0.9 * standard deviation
1.0 * standard deviation
1.1 * standard deviation
The script can easily be modified to test other levels as well, but according to my experience these levels work the best.
The info box shows the performance of one of these levels, chosen by the user.
Every Yellow bar in the graph shows a buy signal. That is: The stocks open is substantially lower (0.5 - 1.1 standard deviations) than yesterdays close. This means we have a buy signal.
The Multiplier shows which multiplier is chosen, the sum shows the profit following the strategy if ONE stock is bought on every buy signal. The Ratio shows the ratio between winning and losing trades if we followed the strategy historically.
We want to find stocks that have a high ratio and a positive sum. That is More Ups than downs. A ratio over 0.5 is good, but of course we want a margin of safety so, 0.75 is a better choice but harder to find.
If we find a stock that meets our criteria then the strategy will be to buy as early as possible on the open, and sell as close as possible on the close!
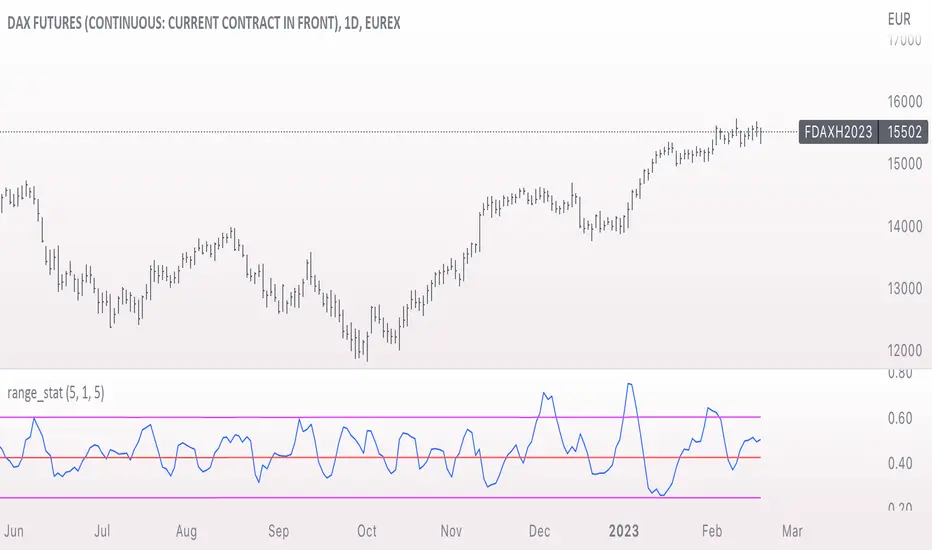
range_statA basic statistic to describe "ranges". There are three inputs:
- short range
- long range
- moving average length
The output is a ratio of the short range to the long range. In the screenshot example, the short range is a single day (bar) and the long range is five days. A value near "1" would mean that every day entirely fills the five day range, and that a consolidation is likely present. A value near 0 would mean that each day fills only a small portion of the five day range, and price is probably "trending".
The moving average length is for smoothing the result (which also lags it of course).
The mean, and +- 2 standard deviations are plotted as fuchsia colored lines.
Keltner Channels Bands (RMA)Keltner Channel Bands
These normally consist of:
Keltner Channel Upper Band = EMA + Multiplier ∗ ATR
Keltner Channel Lower Band = EMA − Multiplier ∗ ATR
However instead of using ATR we are using RMA
This gives us a much smoother take of the KCB
We are also using 2 sets of bands built on 1 Moving average, this is a common set up for mean reversion strategies.
This can often be paired with RSI for lower timeframe divergences
Divergence
This is using the RSI to calculate when price sets new lows/highs whilst the RSI movement is in the opposite direction.
The way this is calculated is slightly different to traditional divergence scripts. instead of looking for pivot highs/lows in the RSI we are logging the RSI value when price makes it pivot highs/lows.
Gradient Bands
The Gradient Colouring on the bands is measuring how long price has been either side of the MA.
As Keltner bands are commonly used as a mean reversion strategy, I thought it would be useful to see how long price has been trending in a certain direction, the stronger the colours get,
the longer price has been trending that direction which could suggest we are looking for a retrace soon.
Alerts
Alerts included let you choose whether you want to receive an alert for the inside, outside or both band touches.
To set up these alerts, simply toggle them on in the settings, then click on the 3 dots next to the indicators name, from there you click 'Add Alert'.
From there you can customise the alert settings but make sure to leave the 2 top boxes which control the alert conditions. They will be default selected onto your correct settings, the rest you may want to change.
Once you create the alert, it will then trigger as soon as price touches your chosen inside/outside band.
Suggestions
Please feel free to offer any suggestions which you think could improve the script
Disclaimer
The default settings/parameters were shared by Jimtalbott, feel free to play about with the and use this code to make your own strategies.

Mean Reversion DotsMarkets tend to mean revert. This indicator plots a moving average from a higher time frame (type of MA and length selectable by the user). It then calculates standard deviations in two dimensions:
- Standard deviation of move of price away from this moving average
- Standard deviations of number of bars spent in this extended range
The indicator plots a table in the upper right corner with the % of distance of price from the moving average. It then plots 'mean reversion dots' once price has been 1 or more standard deviations away from the moving average for one or more standard deviations number of bars. The dots change color, becoming more intense, the longer the move persists. Optionally, the user can display the standard deviations in movement away from the moving average as channels, and the user can also select which levels of moves they want to see. Opting to see only more extreme moves will result in fewer signals, but signals that are more likely to imminently result in mean reversion back to the moving average.
In my opinion, this indicator is more likely to be useful for indices, futures, commodities, and select larger cap names.
Combinations I have found that work well for SPX are plotting the 30min 21ema on a 5min chart and the daily 21ema on an hourly chart.
In many cases, once mean reversion dots for an extreme enough move (level 1.3 or 2.2 and above) begin to appear, a trade may be initiated from a support/resistance level. A safer way to use these signals is to consider them as a 'heads up' that the move is overextended, and then look for a buy/sell signal from another indicator to initiate a position.
Note: I borrowed the code for the higher timeframe MA from the below indicator. I added the ability to select type of MA.
normsinvLibrary "normsinv"
Description:
Returns the inverse of the standard normal cumulative distribution.
The distribution has a mean of zero and a standard deviation of one; i.e.,
normsinv seeks that value z such that a normal distribtuion of mean of zero
and standard deviation one is equal to the input probability.
Reference:
github.com
normsinv(y0)
Returns the inverse of the standard normal cumulative distribution. The distribution has a mean of zero and a standard deviation of one.
Parameters:
y0 : float, probability corresponding to the normal distribution.
Returns: float, z-score
Trend Day IndentificationVolatility is cyclical, after a large move up or down the market typically "ranges" during the next session. Directional order flow that enters the market during this subsequent session tends not to persist, this non-persistency of transactions leads to a non-trend day which is when I trade intraday reversionary strategies.
This script finds trend days in BTC with the purpose of:
1) counting trend day frequency
2) predicting range contraction for the next 1-2 days so I can run intraday reversion strategies
Trend down is defined as daily bar opening within X% of high and closing within X% of low
Trend up is defined as daily bar opening within X% of low and closing within X% of high
default parameters are:
1) open range extreme = 15% (open is within 15% of high or low)
2) close range extreme = 15% (close is within 15% of high or low)
There is also an atr filter that checks that the trend day has a larger range than the previous 4 bars this is to make sure we find true range expansion vs recent ranges.
Notes:
If a trend day occurs after a prolonged sideways contraction it can signal a breakout - this is less common but is an exception to the rule. These types of occurrences can lead to the persistency of order flow and result in extended directional daily runs.
If a trend day occurs close to 20 days high or low (stopping just short OR pushing slightly through) then wait an additional day before trading intraday reversion strategies.

Ergodic Mean Deviation Indicator [CC]The Ergodic Mean Deviation Indicator was created by William Blau and this is a hidden gem that takes the difference between the current price and it's exponential moving average and then double smooths the result to create this indicator. This double smoothing of course creates a lag that allows it to give off a sustained buy signal during a bullish trend and vice versa. This is a very fun indicator to experiment with and surprised that no one on here gives William Blau much attention so I will go ahead and publish the rest of his scripts eventually. I have included strong buy and sell signals in addition to normal ones so strong signals are darker in color and normal signals are lighter in color. Buy when the line turns green and sell when it turns red.
Let me know if there are any other indicators or scripts you would like to see me publish!

Ichimoku Kinko Hyo1) Plot up to 8 moving averages or donchian channels.
2) Moving average types include SMA, EMA, Double EMA, Triple EMA, Quadruple EMA, Pentuple EMA, Zero-Lag EMA, Tillson's T3, Hull's MA, Smoothed MA, Weighted MA, Volume-Weighted MA.
3) Donchian channels can be plotted for a user specified period with upper and lower lines based on either A) highest and lowest prices or B) highest candle body (open/close) and lowest candle body (open/close) over a specified period.
4) Plot 2 arithmetic means averaging any 2 to 8 of the previously mentioned moving averages or donchian median lines.
5) Display 2 fills/clouds between any of the previously mentioned plots.
6) Enough flexibility in the script to utilize Ichimoku Kinko Hyo with correctly adjusted offsets.
7) Ichimoku Kinko Hyo is the default settings. Display additional moving averages or donchian channels for comparison.
"One Half" color scheme by Son A. Pham

Deviation BandsThis indicator plots the 1, 2 and 3 standard deviations from the mean as bands of color (hot and cold). Useful in identifying likely points of mean reversion.
Default mean is WMA 200 but can be SMA, EMA, VWMA, and VAWMA.
Calculating the standard deviation is done by first cleaning the data of outliers (configurable).

ETF 3-Day Reversion StrategyIntroduction: This strategy is a modification of the “3-day Mean Reversion Strategy” from the book "High Probability ETF Trading" by Larry Connors and Cesar Alvarez. In the book, the authors discuss a high-probability ETF mean reversion strategy for a 1-day time-frame with these simple rules:
The price must be above the 200 day SMA and below the 5 day SMA.
The low of today must be lower than the low of yesterday (must be true for 3 consecutive days)
The high of today must be lower than the high of yesterday (must be true for 3 consecutive days)
If the 3 rules above are true, then buy on the close of the current day.
Exit when the closing price crosses above the 5 day SMA.
In practice and in backtesting, I’ve found that the strategy consistently works better when using an EMA for the trend-line instead of an SMA. So, this script uses an EMA for the trend-line. I’ve also made the length of the exit EMA adjustable.
How it works:
The Strategy will buy when the buy conditions above are true. The strategy will sell when the closing price crosses over the Exit Moving Average
Plots:
Green line = Exit Moving Average (Default 5 Day EMA)
Blue line = 5 Day EMA (Used as Entry Criteria)
Disclaimer: Open-source scripts I publish in the community are largely meant to spark ideas that can be used as building blocks for part of a more robust trade management strategy. If you would like to implement a version of any script, I would recommend making significant additions/modifications to the strategy & risk management functions. If you don’t know how to program in Pine, then hire a Pine-coder. We can help!

EMA MTF PlusI like trading the 1 minute and 3 minutes time-frames. I'm what is commonly called a "scalper". Long term investments yes, I have some, but for trading, I don't have neither the time,
nor the patience to wait hours or days for my trade to be complete.
This doesn't mean I discount the higher time-frames, no, I actually rely heavily on them. I found that EMAs do a decent job as support/resistance, sometimes to a tick level of precision. And this is important for a 1 minute trader.
As such, I made this script that tracks the higher time-frames EMAs and displays the last value as a line.
I do not need the whole EMA, I'm not interested in crossovers or crossunders, these are anyway late signals for me.
What's with the triangles? These are local tops/bottoms , candles that have a have decent size of the wick. These tops and bottoms are by no means "final", they are merely a rejection at certain levels of price. Due to markets complexities (and human erratic behaviors hehe) these levels could be breached at the very next candle. For a more "final" version (nothing is really final but..) I added Schaff Trend Cycle as filter, so a triangle will pop only when a trend is mature enough ( STC with a value near 0 or near 100).
Colored bars. When the body of the candle is big, it shows strength. Strong bars tend to have follow through, especially when breaking key levels. The script looks at the body of the candle and compares it with ATR (Average True Range), if it's at least 0.8 of ATR it changes the bar color to yellow (bull candles) or fuchsia(bear candles).
Range identifier. This code is copied from Lazy Bear (if there are any issues please let me know), it's very useful in conjunction with colored bars.
I look for breakout candles that go outside of the range as a signal for a trade.
There are many ways in which this script can be useful, like trading mean reversions or momentum trades (breakouts) or simply trend following trades.
I hope you guys find it useful, you can play with default values and change them as you like, these are what I found to be working best for me and my trading universe (mostly crypto).
Special thanks for the original work of:
LazyBear
everget
Jim8080
Pythagorean Means of Moving AveragesDESCRIPTION
Pythagorean Means of Moving Averages
1. Calculates a set of moving averages for high, low, close, open and typical prices, each at multiple periods.
Period values follow the Fibonacci sequence.
The "short" set includes moving average having the following periods: 5, 8, 13, 21, 34, 55, 89, 144, 233, 377.
The "mid" set includes moving average having the following periods: 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597.
The "long" set includes moving average having the following periods: 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181.
2. User selects the type of moving average: SMA, EMA, HMA, RMA, WMA, VWMA.
3. Calculates the mean of each set of moving averages.
4. User selects the type of mean to be calculated: 1) arithmetic, 2) geometric, 3) harmonic, 4) quadratic, 5) cubic. Multiple mean calculations may be displayed simultaneously, allowing for comparison.
5. Plots the mean for high, low, close, open, and typical prices.
6. User selects which plots to display: 1) high and low prices, 2) close prices, 3) open prices, and/or 4) typical prices.
7. Calculates and plots a vertical deviation from an origin mean--the mean from which the deviation is measured.
8. Deviation = origin mean x a x b^(x/y)/c.
9. User selects the deviation origin mean: 1) high and low prices plot, 2) close prices plot, or 3) typical prices plot.
10. User defines deviation variables a, b, c, x and y.
Examples of deviation:
a) Percent of the mean = 1.414213562 = 2^(1/2) = Pythagoras's constant (default).
b) Percent of the mean = 0.7071067812 = = = sin 45˚ = cos 45˚.
11. Displaces the plots horizontally +/- by a user defined number of periods.
PURPOSE
1. Identify price trends and potential levels of support and resistance.
CREDITS
1. "Fibonacci Moving Average" by Sofien Kaabar: two plots, each an arithmetic mean of EMAs of 1) high prices and 2) low prices, with periods 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181.
2. "Solarized" color scheme by Ethan Schoonover.

Keltner Channels BandsKeltner Channel Bands
Great indicator for mean reversion strategies.
Alerts you can set:
Crossover EMA
Crossunder EMA
Crossover upper band
Crossunder upper band
Crossover lower band
Crossunder lower band
Have fun!
