FiveFactorEdgeUses ATR14, TSI, RSI, Fast Stochastic and Slow Stochastic information to determine potential high and low price, trend strength and direction. The information ia easy to read, self-descriptive and color coded for quick reference. Since it incorporates 5 different elements it could be used by itself but as with any indicator it's highly recommended to use it with other tried and true indicators.
M-oscillator

OG Trend MeterDescription:
The OG Trend Meter gives you a visual snapshot of multiple timeframe trends in one glance. Built for speed and clarity, it helps confirm direction across key intraday timeframes: 1m, 5m, 15m, and 30m.
How it works:
Each timeframe analyzes EMA alignment, price action, and momentum.
Displays clear green/red indicators for bullish/bearish trends on each timeframe.
Great for aligning trades with higher timeframe bias.
Best for:
Traders who want multi-timeframe confirmation before pulling the trigger.
Reducing fakeouts by staying with the dominant trend.
Scalping with the 1m chart while respecting 5m–30m direction.
Pair With: OG Supertrend or EMA Stack for high-probability confluence.

OG ATR RangeDescription:
The OG ATR Tool is a clean, visualized version of the Average True Range indicator for identifying volatility, stop-loss levels, and realistic price movement expectations.
How it works:
Calculates the average range (in points/pips) of recent candles.
Overlays ATR bands to help define breakout potential or squeeze zones.
Can be used to size trades or set dynamic stop-loss and target levels.
Best for:
Intraday traders who want to avoid unrealistic targets.
Volatility-based setups and breakout strategies.
Creating position sizing rules based on instrument volatility.
Pro Tip: Combine with your trend indicators to set sniper entries and exits that respect volatility.
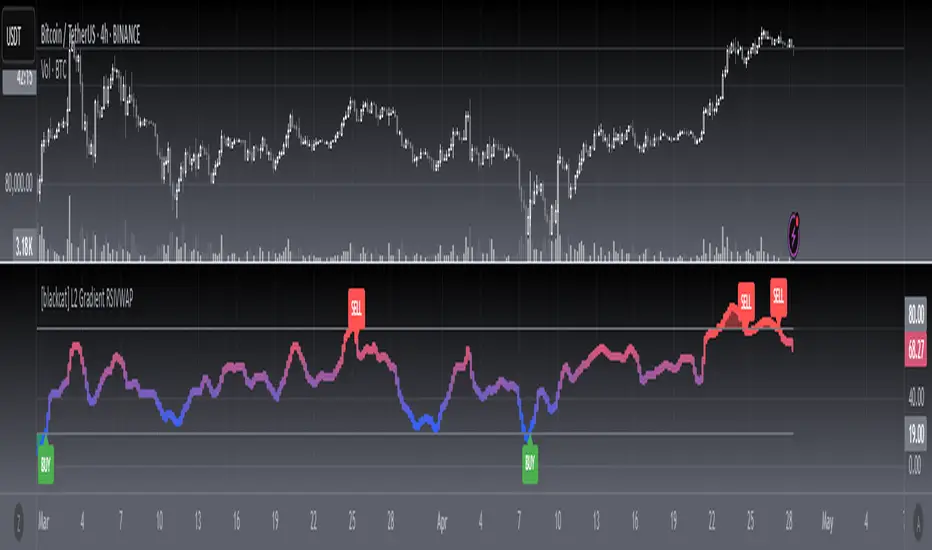
[blackcat] L2 Gradient RSIVWAPOVERVIEW
The L2 Gradient RSIVWAP indicator offers traders a powerful tool for assessing market conditions by combining Relative Strength Index (RSI) with Volume Weighted Average Price (VWAP). It features dynamic coloring and clear buy/sell signals to enhance decision-making.
Customizable Inputs: Adjust key parameters such as RSI-VWAP length, oversold/overbought levels, and smoothing period.
Gradient Color Visualization: Provides intuitive gradient coloring to represent RSI-VWAP values.
Buy/Sell Indicators: On-chart labels highlight potential buying and selling opportunities.
Transparent Fills: Visually distinguishes overbought and oversold zones without obscuring other data.
Access the TradingView platform and select the chart where you wish to implement the indicator.
Go to “Indicators” in the toolbar and search for “ L2 Gradient RSIVWAP.”
Click “Add to Chart” to integrate the indicator into your chart.
Customize settings via the input options:
Toggle between standard RSI and RSI-based VWAP.
Set preferred lengths and thresholds for RSI-VWAP calculations.
Configure the smoothing period for ALMA.
Performance can vary based on asset characteristics like liquidity and volatility.
Historical backtests do not predict future market behavior accurately.
The ALMA function, developed by Arnaud Legoux, enhances response times relative to simple moving averages.
Buy and sell signals are derived from RSI-VWAP crossovers; consider additional factors before making trades.
Special thanks to Arnaud Legoux for creating the ALMA function.
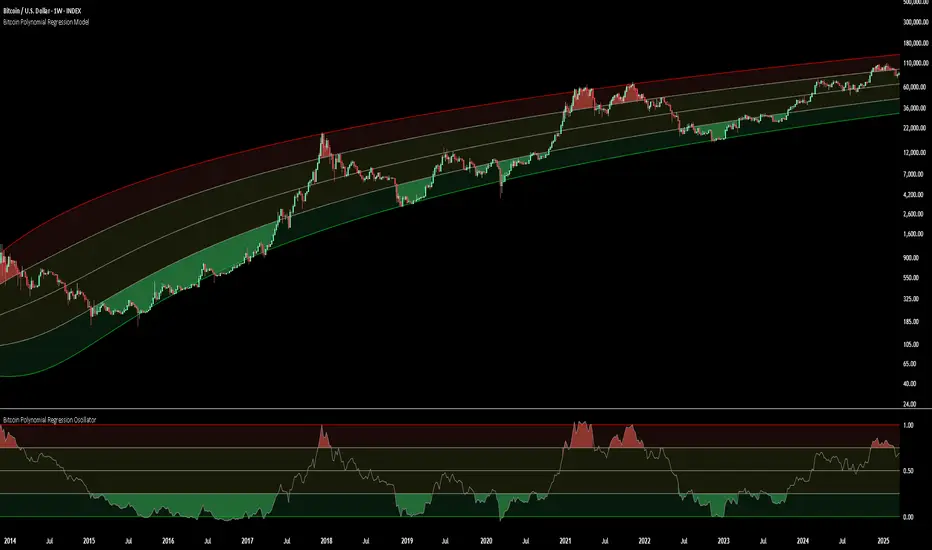
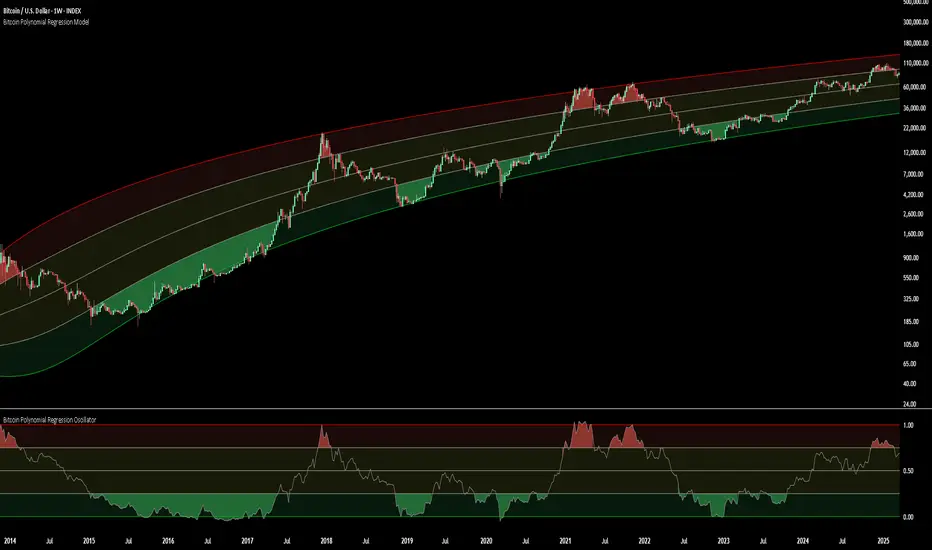
Bitcoin Polynomial Regression ModelThis is the main version of the script. Click here for the Oscillator part of the script.
💡Why this model was created:
One of the key issues with most existing models, including our own Bitcoin Log Growth Curve Model , is that they often fail to realistically account for diminishing returns. As a result, they may present overly optimistic bull cycle targets (hence, we introduced alternative settings in our previous Bitcoin Log Growth Curve Model).
This new model however, has been built from the ground up with a primary focus on incorporating the principle of diminishing returns. It directly responds to this concept, which has been briefly explored here .
📉The theory of diminishing returns:
This theory suggests that as each four-year market cycle unfolds, volatility gradually decreases, leading to more tempered price movements. It also implies that the price increase from one cycle peak to the next will decrease over time as the asset matures. The same pattern applies to cycle lows and the relationship between tops and bottoms. In essence, these price movements are interconnected and should generally follow a consistent pattern. We believe this model provides a more realistic outlook on bull and bear market cycles.
To better understand this theory, the relationships between cycle tops and bottoms are outlined below:https://www.tradingview.com/x/7Hldzsf2/
🔧Creation of the model:
For those interested in how this model was created, the process is explained here. Otherwise, feel free to skip this section.
This model is based on two separate cubic polynomial regression lines. One for the top price trend and another for the bottom. Both follow the general cubic polynomial function:
ax^3 +bx^2 + cx + d.
In this equation, x represents the weekly bar index minus an offset, while a, b, c, and d are determined through polynomial regression analysis. The input (x, y) values used for the polynomial regression analysis are as follows:
Top regression line (x, y) values:
113, 18.6
240, 1004
451, 19128
655, 65502
Bottom regression line (x, y) values:
103, 2.5
267, 211
471, 3193
676, 16255
The values above correspond to historical Bitcoin cycle tops and bottoms, where x is the weekly bar index and y is the weekly closing price of Bitcoin. The best fit is determined using metrics such as R-squared values, residual error analysis, and visual inspection. While the exact details of this evaluation are beyond the scope of this post, the following optimal parameters were found:
Top regression line parameter values:
a: 0.000202798
b: 0.0872922
c: -30.88805
d: 1827.14113
Bottom regression line parameter values:
a: 0.000138314
b: -0.0768236
c: 13.90555
d: -765.8892
📊Polynomial Regression Oscillator:
This publication also includes the oscillator version of the this model which is displayed at the bottom of the screen. The oscillator applies a logarithmic transformation to the price and the regression lines using the formula log10(x) .
The log-transformed price is then normalized using min-max normalization relative to the log-transformed top and bottom regression line with the formula:
normalized price = log(close) - log(bottom regression line) / log(top regression line) - log(bottom regression line)
This transformation results in a price value between 0 and 1 between both the regression lines. The Oscillator version can be found here.
🔍Interpretation of the Model:
In general, the red area represents a caution zone, as historically, the price has often been near its cycle market top within this range. On the other hand, the green area is considered an area of opportunity, as historically, it has corresponded to the market bottom.
The top regression line serves as a signal for the absolute market cycle peak, while the bottom regression line indicates the absolute market cycle bottom.
Additionally, this model provides a predicted range for Bitcoin's future price movements, which can be used to make extrapolated predictions. We will explore this further below.
🔮Future Predictions:
Finally, let's discuss what this model actually predicts for the potential upcoming market cycle top and the corresponding market cycle bottom. In our previous post here , a cycle interval analysis was performed to predict a likely time window for the next cycle top and bottom:
In the image, it is predicted that the next top-to-top cycle interval will be 208 weeks, which translates to November 3rd, 2025. It is also predicted that the bottom-to-top cycle interval will be 152 weeks, which corresponds to October 13th, 2025. On the macro level, these two dates align quite well. For our prediction, we take the average of these two dates: October 24th 2025. This will be our target date for the bull cycle top.
Now, let's do the same for the upcoming cycle bottom. The bottom-to-bottom cycle interval is predicted to be 205 weeks, which translates to October 19th, 2026, and the top-to-bottom cycle interval is predicted to be 259 weeks, which corresponds to October 26th, 2026. We then take the average of these two dates, predicting a bear cycle bottom date target of October 19th, 2026.
Now that we have our predicted top and bottom cycle date targets, we can simply reference these two dates to our model, giving us the Bitcoin top price prediction in the range of 152,000 in Q4 2025 and a subsequent bottom price prediction in the range of 46,500 in Q4 2026.
For those interested in understanding what this specifically means for the predicted diminishing return top and bottom cycle values, the image below displays these predicted values. The new values are highlighted in yellow:
And of course, keep in mind that these targets are just rough estimates. While we've done our best to estimate these targets through a data-driven approach, markets will always remain unpredictable in nature. What are your targets? Feel free to share them in the comment section below.
Bitcoin Polynomial Regression OscillatorThis is the oscillator version of the script. Click here for the other part of the script.
💡Why this model was created:
One of the key issues with most existing models, including our own Bitcoin Log Growth Curve Model , is that they often fail to realistically account for diminishing returns. As a result, they may present overly optimistic bull cycle targets (hence, we introduced alternative settings in our previous Bitcoin Log Growth Curve Model).
This new model however, has been built from the ground up with a primary focus on incorporating the principle of diminishing returns. It directly responds to this concept, which has been briefly explored here .
📉The theory of diminishing returns:
This theory suggests that as each four-year market cycle unfolds, volatility gradually decreases, leading to more tempered price movements. It also implies that the price increase from one cycle peak to the next will decrease over time as the asset matures. The same pattern applies to cycle lows and the relationship between tops and bottoms. In essence, these price movements are interconnected and should generally follow a consistent pattern. We believe this model provides a more realistic outlook on bull and bear market cycles.
To better understand this theory, the relationships between cycle tops and bottoms are outlined below:https://www.tradingview.com/x/7Hldzsf2/
🔧Creation of the model:
For those interested in how this model was created, the process is explained here. Otherwise, feel free to skip this section.
This model is based on two separate cubic polynomial regression lines. One for the top price trend and another for the bottom. Both follow the general cubic polynomial function:
ax^3 +bx^2 + cx + d.
In this equation, x represents the weekly bar index minus an offset, while a, b, c, and d are determined through polynomial regression analysis. The input (x, y) values used for the polynomial regression analysis are as follows:
Top regression line (x, y) values:
113, 18.6
240, 1004
451, 19128
655, 65502
Bottom regression line (x, y) values:
103, 2.5
267, 211
471, 3193
676, 16255
The values above correspond to historical Bitcoin cycle tops and bottoms, where x is the weekly bar index and y is the weekly closing price of Bitcoin. The best fit is determined using metrics such as R-squared values, residual error analysis, and visual inspection. While the exact details of this evaluation are beyond the scope of this post, the following optimal parameters were found:
Top regression line parameter values:
a: 0.000202798
b: 0.0872922
c: -30.88805
d: 1827.14113
Bottom regression line parameter values:
a: 0.000138314
b: -0.0768236
c: 13.90555
d: -765.8892
📊Polynomial Regression Oscillator:
This publication also includes the oscillator version of the this model which is displayed at the bottom of the screen. The oscillator applies a logarithmic transformation to the price and the regression lines using the formula log10(x) .
The log-transformed price is then normalized using min-max normalization relative to the log-transformed top and bottom regression line with the formula:
normalized price = log(close) - log(bottom regression line) / log(top regression line) - log(bottom regression line)
This transformation results in a price value between 0 and 1 between both the regression lines.
🔍Interpretation of the Model:
In general, the red area represents a caution zone, as historically, the price has often been near its cycle market top within this range. On the other hand, the green area is considered an area of opportunity, as historically, it has corresponded to the market bottom.
The top regression line serves as a signal for the absolute market cycle peak, while the bottom regression line indicates the absolute market cycle bottom.
Additionally, this model provides a predicted range for Bitcoin's future price movements, which can be used to make extrapolated predictions. We will explore this further below.
🔮Future Predictions:
Finally, let's discuss what this model actually predicts for the potential upcoming market cycle top and the corresponding market cycle bottom. In our previous post here , a cycle interval analysis was performed to predict a likely time window for the next cycle top and bottom:
In the image, it is predicted that the next top-to-top cycle interval will be 208 weeks, which translates to November 3rd, 2025. It is also predicted that the bottom-to-top cycle interval will be 152 weeks, which corresponds to October 13th, 2025. On the macro level, these two dates align quite well. For our prediction, we take the average of these two dates: October 24th 2025. This will be our target date for the bull cycle top.
Now, let's do the same for the upcoming cycle bottom. The bottom-to-bottom cycle interval is predicted to be 205 weeks, which translates to October 19th, 2026, and the top-to-bottom cycle interval is predicted to be 259 weeks, which corresponds to October 26th, 2026. We then take the average of these two dates, predicting a bear cycle bottom date target of October 19th, 2026.
Now that we have our predicted top and bottom cycle date targets, we can simply reference these two dates to our model, giving us the Bitcoin top price prediction in the range of 152,000 in Q4 2025 and a subsequent bottom price prediction in the range of 46,500 in Q4 2026.
For those interested in understanding what this specifically means for the predicted diminishing return top and bottom cycle values, the image below displays these predicted values. The new values are highlighted in yellow:
And of course, keep in mind that these targets are just rough estimates. While we've done our best to estimate these targets through a data-driven approach, markets will always remain unpredictable in nature. What are your targets? Feel free to share them in the comment section below.
Volume Weighted RSI (VW RSI)The Volume Weighted RSI (VW RSI) is a momentum oscillator designed for TradingView, implemented in Pine Script v6, that enhances the traditional Relative Strength Index (RSI) by incorporating trading volume into its calculation. Unlike the standard RSI, which measures the speed and change of price movements based solely on price data, the VW RSI weights its analysis by volume, emphasizing price movements backed by significant trading activity. This makes the VW RSI particularly effective for identifying bullish or bearish momentum, overbought/oversold conditions, and potential trend reversals in markets where volume plays a critical role, such as stocks, forex, and cryptocurrencies.
Key Features
Volume-Weighted Momentum Calculation:
The VW RSI calculates momentum by comparing the volume associated with upward price movements (up-volume) to the volume associated with downward price movements (down-volume).
Up-volume is the volume on bars where the closing price is higher than the previous close, while down-volume is the volume on bars where the closing price is lower than the previous close.
These volumes are smoothed over a user-defined period (default: 14 bars) using a Running Moving Average (RMA), and the VW RSI is computed using the formula:
\text{VW RSI} = 100 - \frac{100}{1 + \text{VoRS}}
where
\text{VoRS} = \frac{\text{Average Up-Volume}}{\text{Average Down-Volume}}
.
Oscillator Range and Interpretation:
The VW RSI oscillates between 0 and 100, with a centerline at 50.
Above 50: Indicates bullish volume momentum, suggesting that volume on up bars dominates, which may signal buying pressure and a potential uptrend.
Below 50: Indicates bearish volume momentum, suggesting that volume on down bars dominates, which may signal selling pressure and a potential downtrend.
Overbought/Oversold Levels: User-defined thresholds (default: 70 for overbought, 30 for oversold) help identify potential reversal points:
VW RSI > 70: Overbought, indicating a possible pullback or reversal.
VW RSI < 30: Oversold, indicating a possible bounce or reversal.
Visual Elements:
VW RSI Line: Plotted in a separate pane below the price chart, colored dynamically based on its value:
Green when above 50 (bullish momentum).
Red when below 50 (bearish momentum).
Gray when at 50 (neutral).
Centerline: A dashed line at 50, optionally displayed, serving as the neutral threshold between bullish and bearish momentum.
Overbought/Oversold Lines: Dashed lines at the user-defined overbought (default: 70) and oversold (default: 30) levels, optionally displayed, to highlight extreme conditions.
Background Coloring: The background of the VW RSI pane is shaded red when the indicator is in overbought territory and green when in oversold territory, providing a quick visual cue of potential reversal zones.
Alerts:
Built-in alerts for key events:
Bullish Momentum: Triggered when the VW RSI crosses above 50, indicating a shift to bullish volume momentum.
Bearish Momentum: Triggered when the VW RSI crosses below 50, indicating a shift to bearish volume momentum.
Overbought Condition: Triggered when the VW RSI crosses above the overbought threshold (default: 70), signaling a potential pullback.
Oversold Condition: Triggered when the VW RSI crosses below the oversold threshold (default: 30), signaling a potential bounce.
Input Parameters
VW RSI Length (default: 14): The period over which the up-volume and down-volume are smoothed to calculate the VW RSI. A longer period results in smoother signals, while a shorter period increases sensitivity.
Overbought Level (default: 70): The threshold above which the VW RSI is considered overbought, indicating a potential reversal or pullback.
Oversold Level (default: 30): The threshold below which the VW RSI is considered oversold, indicating a potential reversal or bounce.
Show Centerline (default: true): Toggles the display of the 50 centerline, which separates bullish and bearish momentum zones.
Show Overbought/Oversold Lines (default: true): Toggles the display of the overbought and oversold threshold lines.
How It Works
Volume Classification:
For each bar, the indicator determines whether the price movement is upward or downward:
If the current close is higher than the previous close, the bar’s volume is classified as up-volume.
If the current close is lower than the previous close, the bar’s volume is classified as down-volume.
If the close is unchanged, both up-volume and down-volume are set to 0 for that bar.
Smoothing:
The up-volume and down-volume are smoothed using a Running Moving Average (RMA) over the specified period (default: 14 bars) to reduce noise and provide a more stable measure of volume momentum.
VW RSI Calculation:
The Volume Relative Strength (VoRS) is calculated as the ratio of smoothed up-volume to smoothed down-volume.
The VW RSI is then computed using the standard RSI formula, but with volume data instead of price changes, resulting in a value between 0 and 100.
Visualization and Alerts:
The VW RSI is plotted with dynamic coloring to reflect its momentum direction, and optional lines are drawn for the centerline and overbought/oversold levels.
Background coloring highlights overbought and oversold conditions, and alerts notify the trader of significant crossings.
Usage
Timeframe: The VW RSI can be used on any timeframe, but it is particularly effective on intraday charts (e.g., 1-hour, 4-hour) or daily charts where volume data is reliable. Shorter timeframes may require a shorter length for increased sensitivity, while longer timeframes may benefit from a longer length for smoother signals.
Markets: Best suited for markets with significant and reliable volume data, such as stocks, forex, and cryptocurrencies. It may be less effective in markets with low or inconsistent volume, such as certain futures contracts.
Trading Strategies:
Trend Confirmation:
Use the VW RSI to confirm the direction of a trend. For example, in an uptrend, look for the VW RSI to remain above 50, indicating sustained bullish volume momentum, and consider buying on pullbacks when the VW RSI dips but stays above 50.
In a downtrend, look for the VW RSI to remain below 50, indicating sustained bearish volume momentum, and consider selling on rallies when the VW RSI rises but stays below 50.
Overbought/Oversold Conditions:
When the VW RSI crosses above 70, the market may be overbought, suggesting a potential pullback or reversal. Consider taking profits on long positions or preparing for a short entry, but confirm with price action or other indicators.
When the VW RSI crosses below 30, the market may be oversold, suggesting a potential bounce or reversal. Consider entering long positions or covering shorts, but confirm with additional signals.
Divergences:
Look for divergences between the VW RSI and price to spot potential reversals. For example, if the price makes a higher high but the VW RSI makes a lower high, this bearish divergence may signal an impending downtrend.
Conversely, if the price makes a lower low but the VW RSI makes a higher low, this bullish divergence may signal an impending uptrend.
Momentum Shifts:
A crossover above 50 can signal the start of bullish momentum, making it a potential entry point for long trades.
A crossunder below 50 can signal the start of bearish momentum, making it a potential entry point for short trades or an exit for long positions.
Example
On a 4-hour SOLUSDT chart:
During an uptrend, the VW RSI might rise above 50 and stay there, confirming bullish volume momentum. If it approaches 70, it may indicate overbought conditions, as seen near a price peak of 145.08, suggesting a potential pullback.
During a downtrend, the VW RSI might fall below 50, confirming bearish volume momentum. If it drops below 30 near a price low of 141.82, it may indicate oversold conditions, suggesting a potential bounce, as seen in a slight recovery afterward.
A bullish divergence might occur if the price makes a lower low during the downtrend, but the VW RSI makes a higher low, signaling a potential reversal.
Limitations
Lagging Nature: Like the traditional RSI, the VW RSI is a lagging indicator because it relies on smoothed data (RMA). It may not react quickly to sudden price reversals, potentially missing the start of new trends.
False Signals in Ranging Markets: In choppy or ranging markets, the VW RSI may oscillate around 50, generating frequent crossovers that lead to false signals. Combining it with a trend filter (e.g., ADX) can help mitigate this.
Volume Data Dependency: The VW RSI relies on accurate volume data, which may be inconsistent or unavailable in some markets (e.g., certain forex pairs or futures contracts). In such cases, the indicator’s effectiveness may be reduced.
Overbought/Oversold in Strong Trends: During strong trends, the VW RSI can remain in overbought or oversold territory for extended periods, leading to premature exit signals. Use additional confirmation to avoid exiting too early.
Potential Improvements
Smoothing Options: Add options to use different smoothing methods (e.g., EMA, SMA) instead of RMA for the up/down volume calculations, allowing users to adjust the indicator’s responsiveness.
Divergence Detection: Include logic to detect and plot bullish/bearish divergences between the VW RSI and price, providing visual cues for potential reversals.
Customizable Colors: Allow users to customize the colors of the VW RSI line, centerline, overbought/oversold lines, and background shading.
Trend Filter: Integrate a trend strength filter (e.g., ADX > 25) to ensure signals are generated only during strong trends, reducing false signals in ranging markets.
The Volume Weighted RSI (VW RSI) is a powerful tool for traders seeking to incorporate volume into their momentum analysis, offering a unique perspective on market dynamics by emphasizing price movements backed by significant trading activity. It is best used in conjunction with other indicators and price action analysis to confirm signals and improve trading decisions.

Enhanced Fuzzy SMA Analyzer (Multi-Output Proxy) [FibonacciFlux]EFzSMA: Decode Trend Quality, Conviction & Risk Beyond Simple Averages
Stop Relying on Lagging Averages Alone. Gain a Multi-Dimensional Edge.
The Challenge: Simple Moving Averages (SMAs) tell you where the price was , but they fail to capture the true quality, conviction, and sustainability of a trend. Relying solely on price crossing an average often leads to chasing weak moves, getting caught in choppy markets, or missing critical signs of trend exhaustion. Advanced traders need a more sophisticated lens to navigate complex market dynamics.
The Solution: Enhanced Fuzzy SMA Analyzer (EFzSMA)
EFzSMA is engineered to address these limitations head-on. It moves beyond simple price-average comparisons by employing a sophisticated Fuzzy Inference System (FIS) that intelligently integrates multiple critical market factors:
Price deviation from the SMA ( adaptively normalized for market volatility)
Momentum (Rate of Change - ROC)
Market Sentiment/Overheat (Relative Strength Index - RSI)
Market Volatility Context (Average True Range - ATR, optional)
Volume Dynamics (Volume relative to its MA, optional)
Instead of just a line on a chart, EFzSMA delivers a multi-dimensional assessment designed to give you deeper insights and a quantifiable edge.
Why EFzSMA? Gain Deeper Market Insights
EFzSMA empowers you to make more informed decisions by providing insights that simple averages cannot:
Assess True Trend Quality, Not Just Location: Is the price above the SMA simply because of a temporary spike, or is it supported by strong momentum, confirming volume, and stable volatility? EFzSMA's core fuzzyTrendScore (-1 to +1) evaluates the health of the trend, helping you distinguish robust moves from noise.
Quantify Signal Conviction: How reliable is the current trend signal? The Conviction Proxy (0 to 1) measures the internal consistency among the different market factors analyzed by the FIS. High conviction suggests factors are aligned, boosting confidence in the trend signal. Low conviction warns of conflicting signals, uncertainty, or potential consolidation – acting as a powerful filter against chasing weak moves.
// Simplified Concept: Conviction reflects agreement vs. conflict among fuzzy inputs
bullStrength = strength_SB + strength_WB
bearStrength = strength_SBe + strength_WBe
dominantStrength = max(bullStrength, bearStrength)
conflictingStrength = min(bullStrength, bearStrength) + strength_N
convictionProxy := (dominantStrength - conflictingStrength) / (dominantStrength + conflictingStrength + 1e-10)
// Modifiers (Volatility/Volume) applied...
Anticipate Potential Reversals: Trends don't last forever. The Reversal Risk Proxy (0 to 1) synthesizes multiple warning signs – like extreme RSI readings, surging volatility, or diverging volume – into a single, actionable metric. High reversal risk flags conditions often associated with trend exhaustion, providing early warnings to protect profits or consider counter-trend opportunities.
Adapt to Changing Market Regimes: Markets shift between high and low volatility. EFzSMA's unique Adaptive Deviation Normalization adjusts how it perceives price deviations based on recent market behavior (percentile rank). This ensures more consistent analysis whether the market is quiet or chaotic.
// Core Idea: Normalize deviation by recent volatility (percentile)
diff_abs_percentile = ta.percentile_linear_interpolation(abs(raw_diff), normLookback, percRank) + 1e-10
normalized_diff := raw_diff / diff_abs_percentile
// Fuzzy sets for 'normalized_diff' are thus adaptive to volatility
Integrate Complexity, Output Clarity: EFzSMA distills complex, multi-factor analysis into clear, interpretable outputs, helping you cut through market noise and focus on what truly matters for your decision-making process.
Interpreting the Multi-Dimensional Output
The true power of EFzSMA lies in analyzing its outputs together:
A high Trend Score (+0.8) is significant, but its reliability is amplified by high Conviction (0.9) and low Reversal Risk (0.2) . This indicates a strong, well-supported trend.
Conversely, the same high Trend Score (+0.8) coupled with low Conviction (0.3) and high Reversal Risk (0.7) signals caution – the trend might look strong superficially, but internal factors suggest weakness or impending exhaustion.
Use these combined insights to:
Filter Entry Signals: Require minimum Trend Score and Conviction levels.
Manage Risk: Consider reducing exposure or tightening stops when Reversal Risk climbs significantly, especially if Conviction drops.
Time Exits: Use rising Reversal Risk and falling Conviction as potential signals to take profits.
Identify Regime Shifts: Monitor how the relationship between the outputs changes over time.
Core Technology (Briefly)
EFzSMA leverages a Mamdani-style Fuzzy Inference System. Crisp inputs (normalized deviation, ROC, RSI, ATR%, Vol Ratio) are mapped to linguistic fuzzy sets ("Low", "High", "Positive", etc.). A rules engine evaluates combinations (e.g., "IF Deviation is LargePositive AND Momentum is StrongPositive THEN Trend is StrongBullish"). Modifiers based on Volatility and Volume context adjust rule strengths. Finally, the system aggregates these and defuzzifies them into the Trend Score, Conviction Proxy, and Reversal Risk Proxy. The key is the system's ability to handle ambiguity and combine multiple, potentially conflicting factors in a nuanced way, much like human expert reasoning.
Customization
While designed with robust defaults, EFzSMA offers granular control:
Adjust SMA, ROC, RSI, ATR, Volume MA lengths.
Fine-tune Normalization parameters (lookback, percentile). Note: Fuzzy set definitions for deviation are tuned for the normalized range.
Configure Volatility and Volume thresholds for fuzzy sets. Tuning these is crucial for specific assets/timeframes.
Toggle visual elements (Proxies, BG Color, Risk Shapes, Volatility-based Transparency).
Recommended Use & Caveats
EFzSMA is a sophisticated analytical tool, not a standalone "buy/sell" signal generator.
Use it to complement your existing strategy and analysis.
Always validate signals with price action, market structure, and other confirming factors.
Thorough backtesting and forward testing are essential to understand its behavior and tune parameters for your specific instruments and timeframes.
Fuzzy logic parameters (membership functions, rules) are based on general heuristics and may require optimization for specific market niches.
Disclaimer
Trading involves substantial risk. EFzSMA is provided for informational and analytical purposes only and does not constitute financial advice. No guarantee of profit is made or implied. Past performance is not indicative of future results. Use rigorous risk management practices.
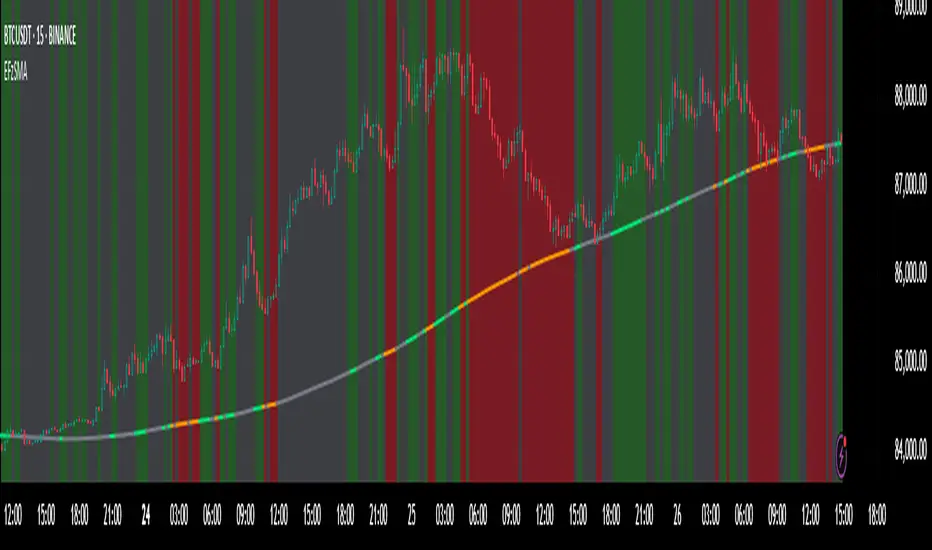
Fuzzy SMA with DCTI Confirmation[FibonacciFlux]FibonacciFlux: Advanced Fuzzy Logic System with Donchian Trend Confirmation
Institutional-grade trend analysis combining adaptive Fuzzy Logic with Donchian Channel Trend Intensity for superior signal quality
Conceptual Framework & Research Foundation
FibonacciFlux represents a significant advancement in quantitative technical analysis, merging two powerful analytical methodologies: normalized fuzzy logic systems and Donchian Channel Trend Intensity (DCTI). This sophisticated indicator addresses a fundamental challenge in market analysis – the inherent imprecision of trend identification in dynamic, multi-dimensional market environments.
While traditional indicators often produce simplistic binary signals, markets exist in states of continuous, graduated transition. FibonacciFlux embraces this complexity through its implementation of fuzzy set theory, enhanced by DCTI's structural trend confirmation capabilities. The result is an indicator that provides nuanced, probabilistic trend assessment with institutional-grade signal quality.
Core Technological Components
1. Advanced Fuzzy Logic System with Percentile Normalization
At the foundation of FibonacciFlux lies a comprehensive fuzzy logic system that transforms conventional technical metrics into degrees of membership in linguistic variables:
// Fuzzy triangular membership function with robust error handling
fuzzy_triangle(val, left, center, right) =>
if na(val)
0.0
float denominator1 = math.max(1e-10, center - left)
float denominator2 = math.max(1e-10, right - center)
math.max(0.0, math.min(left == center ? val <= center ? 1.0 : 0.0 : (val - left) / denominator1,
center == right ? val >= center ? 1.0 : 0.0 : (right - val) / denominator2))
The system employs percentile-based normalization for SMA deviation – a critical innovation that enables self-calibration across different assets and market regimes:
// Percentile-based normalization for adaptive calibration
raw_diff = price_src - sma_val
diff_abs_percentile = ta.percentile_linear_interpolation(math.abs(raw_diff), normLookback, percRank) + 1e-10
normalized_diff_raw = raw_diff / diff_abs_percentile
normalized_diff = useClamping ? math.max(-clampValue, math.min(clampValue, normalized_diff_raw)) : normalized_diff_raw
This normalization approach represents a significant advancement over fixed-threshold systems, allowing the indicator to automatically adapt to varying volatility environments and maintain consistent signal quality across diverse market conditions.
2. Donchian Channel Trend Intensity (DCTI) Integration
FibonacciFlux significantly enhances fuzzy logic analysis through the integration of Donchian Channel Trend Intensity (DCTI) – a sophisticated measure of trend strength based on the relationship between short-term and long-term price extremes:
// DCTI calculation for structural trend confirmation
f_dcti(src, majorPer, minorPer, sigPer) =>
H = ta.highest(high, majorPer) // Major period high
L = ta.lowest(low, majorPer) // Major period low
h = ta.highest(high, minorPer) // Minor period high
l = ta.lowest(low, minorPer) // Minor period low
float pdiv = not na(L) ? l - L : 0 // Positive divergence (low vs major low)
float ndiv = not na(H) ? H - h : 0 // Negative divergence (major high vs high)
float divisor = pdiv + ndiv
dctiValue = divisor == 0 ? 0 : 100 * ((pdiv - ndiv) / divisor) // Normalized to -100 to +100 range
sigValue = ta.ema(dctiValue, sigPer)
DCTI provides a complementary structural perspective on market trends by quantifying the relationship between short-term and long-term price extremes. This creates a multi-dimensional analysis framework that combines adaptive deviation measurement (fuzzy SMA) with channel-based trend intensity confirmation (DCTI).
Multi-Dimensional Fuzzy Input Variables
FibonacciFlux processes four distinct technical dimensions through its fuzzy system:
Normalized SMA Deviation: Measures price displacement relative to historical volatility context
Rate of Change (ROC): Captures price momentum over configurable timeframes
Relative Strength Index (RSI): Evaluates cyclical overbought/oversold conditions
Donchian Channel Trend Intensity (DCTI): Provides structural trend confirmation through channel analysis
Each dimension is processed through comprehensive fuzzy sets that transform crisp numerical values into linguistic variables:
// Normalized SMA Deviation - Self-calibrating to volatility regimes
ndiff_LP := fuzzy_triangle(normalized_diff, norm_scale * 0.3, norm_scale * 0.7, norm_scale * 1.1)
ndiff_SP := fuzzy_triangle(normalized_diff, norm_scale * 0.05, norm_scale * 0.25, norm_scale * 0.5)
ndiff_NZ := fuzzy_triangle(normalized_diff, -norm_scale * 0.1, 0.0, norm_scale * 0.1)
ndiff_SN := fuzzy_triangle(normalized_diff, -norm_scale * 0.5, -norm_scale * 0.25, -norm_scale * 0.05)
ndiff_LN := fuzzy_triangle(normalized_diff, -norm_scale * 1.1, -norm_scale * 0.7, -norm_scale * 0.3)
// DCTI - Structural trend measurement
dcti_SP := fuzzy_triangle(dcti_val, 60.0, 85.0, 101.0) // Strong Positive Trend (> ~85)
dcti_WP := fuzzy_triangle(dcti_val, 20.0, 45.0, 70.0) // Weak Positive Trend (~30-60)
dcti_Z := fuzzy_triangle(dcti_val, -30.0, 0.0, 30.0) // Near Zero / Trendless (~+/- 20)
dcti_WN := fuzzy_triangle(dcti_val, -70.0, -45.0, -20.0) // Weak Negative Trend (~-30 - -60)
dcti_SN := fuzzy_triangle(dcti_val, -101.0, -85.0, -60.0) // Strong Negative Trend (< ~-85)
Advanced Fuzzy Rule System with DCTI Confirmation
The core intelligence of FibonacciFlux lies in its sophisticated fuzzy rule system – a structured knowledge representation that encodes expert understanding of market dynamics:
// Base Trend Rules with DCTI Confirmation
cond1 = math.min(ndiff_LP, roc_HP, rsi_M)
strength_SB := math.max(strength_SB, cond1 * (dcti_SP > 0.5 ? 1.2 : dcti_Z > 0.1 ? 0.5 : 1.0))
// DCTI Override Rules - Structural trend confirmation with momentum alignment
cond14 = math.min(ndiff_NZ, roc_HP, dcti_SP)
strength_SB := math.max(strength_SB, cond14 * 0.5)
The rule system implements 15 distinct fuzzy rules that evaluate various market conditions including:
Established Trends: Strong deviations with confirming momentum and DCTI alignment
Emerging Trends: Early deviation patterns with initial momentum and DCTI confirmation
Weakening Trends: Divergent signals between deviation, momentum, and DCTI
Reversal Conditions: Counter-trend signals with DCTI confirmation
Neutral Consolidations: Minimal deviation with low momentum and neutral DCTI
A key innovation is the weighted influence of DCTI on rule activation. When strong DCTI readings align with other indicators, rule strength is amplified (up to 1.2x). Conversely, when DCTI contradicts other indicators, rule impact is reduced (as low as 0.5x). This creates a dynamic, self-adjusting system that prioritizes high-conviction signals.
Defuzzification & Signal Generation
The final step transforms fuzzy outputs into a precise trend score through center-of-gravity defuzzification:
// Defuzzification with precise floating-point handling
denominator = strength_SB + strength_WB + strength_N + strength_WBe + strength_SBe
if denominator > 1e-10
fuzzyTrendScore := (strength_SB * STRONG_BULL + strength_WB * WEAK_BULL +
strength_N * NEUTRAL + strength_WBe * WEAK_BEAR +
strength_SBe * STRONG_BEAR) / denominator
The resulting FuzzyTrendScore ranges from -1.0 (Strong Bear) to +1.0 (Strong Bull), with critical threshold zones at ±0.3 (Weak trend) and ±0.7 (Strong trend). The histogram visualization employs intuitive color-coding for immediate trend assessment.
Strategic Applications for Institutional Trading
FibonacciFlux provides substantial advantages for sophisticated trading operations:
Multi-Timeframe Signal Confirmation: Institutional-grade signal validation across multiple technical dimensions
Trend Strength Quantification: Precise measurement of trend conviction with noise filtration
Early Trend Identification: Detection of emerging trends before traditional indicators through fuzzy pattern recognition
Adaptive Market Regime Analysis: Self-calibrating analysis across varying volatility environments
Algorithmic Strategy Integration: Well-defined numerical output suitable for systematic trading frameworks
Risk Management Enhancement: Superior signal fidelity for risk exposure optimization
Customization Parameters
FibonacciFlux offers extensive customization to align with specific trading mandates and market conditions:
Fuzzy SMA Settings: Configure baseline trend identification parameters including SMA, ROC, and RSI lengths
Normalization Settings: Fine-tune the self-calibration mechanism with adjustable lookback period, percentile rank, and optional clamping
DCTI Parameters: Optimize trend structure confirmation with adjustable major/minor periods and signal smoothing
Visualization Controls: Customize display transparency for optimal chart integration
These parameters enable precise calibration for different asset classes, timeframes, and market regimes while maintaining the core analytical framework.
Implementation Notes
For optimal implementation, consider the following guidance:
Higher timeframes (4H+) benefit from increased normalization lookback (800+) for stability
Volatile assets may require adjusted clamping values (2.5-4.0) for optimal signal sensitivity
DCTI parameters should be aligned with chart timeframe (higher timeframes require increased major/minor periods)
The indicator performs exceptionally well as a trend filter for systematic trading strategies
Acknowledgments
FibonacciFlux builds upon the pioneering work of Donovan Wall in Donchian Channel Trend Intensity analysis. The normalization approach draws inspiration from percentile-based statistical techniques in quantitative finance. This indicator is shared for educational and analytical purposes under Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license.
Past performance does not guarantee future results. All trading involves risk. This indicator should be used as one component of a comprehensive analysis framework.
Shout out @DonovanWall
Fuzzy SMA Trend Analyzer (experimental)[FibonacciFlux]Fuzzy SMA Trend Analyzer (Normalized): Advanced Market Trend Detection Using Fuzzy Logic Theory
Elevate your technical analysis with institutional-grade fuzzy logic implementation
Research Genesis & Conceptual Framework
This indicator represents the culmination of extensive research into applying fuzzy logic theory to financial markets. While traditional technical indicators often produce binary outcomes, market conditions exist on a continuous spectrum. The Fuzzy SMA Trend Analyzer addresses this limitation by implementing a sophisticated fuzzy logic system that captures the nuanced, multi-dimensional nature of market trends.
Core Fuzzy Logic Principles
At the heart of this indicator lies fuzzy logic theory - a mathematical framework designed to handle imprecision and uncertainty:
// Improved fuzzy_triangle function with guard clauses for NA and invalid parameters.
fuzzy_triangle(val, left, center, right) =>
if na(val) or na(left) or na(center) or na(right) or left > center or center > right // Guard checks
0.0
else if left == center and center == right // Crisp set (single point)
val == center ? 1.0 : 0.0
else if left == center // Left-shoulder shape (ramp down from 1 at center to 0 at right)
val >= right ? 0.0 : val <= center ? 1.0 : (right - val) / (right - center)
else if center == right // Right-shoulder shape (ramp up from 0 at left to 1 at center)
val <= left ? 0.0 : val >= center ? 1.0 : (val - left) / (center - left)
else // Standard triangle
math.max(0.0, math.min((val - left) / (center - left), (right - val) / (right - center)))
This implementation of triangular membership functions enables the indicator to transform crisp numerical values into degrees of membership in linguistic variables like "Large Positive" or "Small Negative," creating a more nuanced representation of market conditions.
Dynamic Percentile Normalization
A critical innovation in this indicator is the implementation of percentile-based normalization for SMA deviation:
// ----- Deviation Scale Estimation using Percentile -----
// Calculate the percentile rank of the *absolute* deviation over the lookback period.
// This gives an estimate of the 'typical maximum' deviation magnitude recently.
diff_abs_percentile = ta.percentile_linear_interpolation(math.abs(raw_diff), normLookback, percRank) + 1e-10
// ----- Normalize the Raw Deviation -----
// Divide the raw deviation by the estimated 'typical max' magnitude.
normalized_diff = raw_diff / diff_abs_percentile
// ----- Clamp the Normalized Deviation -----
normalized_diff_clamped = math.max(-3.0, math.min(3.0, normalized_diff))
This percentile normalization approach creates a self-adapting system that automatically calibrates to different assets and market regimes. Rather than using fixed thresholds, the indicator dynamically adjusts based on recent volatility patterns, significantly enhancing signal quality across diverse market environments.
Multi-Factor Fuzzy Rule System
The indicator implements a comprehensive fuzzy rule system that evaluates multiple technical factors:
SMA Deviation (Normalized): Measures price displacement from the Simple Moving Average
Rate of Change (ROC): Captures price momentum over a specified period
Relative Strength Index (RSI): Assesses overbought/oversold conditions
These factors are processed through a sophisticated fuzzy inference system with linguistic variables:
// ----- 3.1 Fuzzy Sets for Normalized Deviation -----
diffN_LP := fuzzy_triangle(normalized_diff_clamped, 0.7, 1.5, 3.0) // Large Positive (around/above percentile)
diffN_SP := fuzzy_triangle(normalized_diff_clamped, 0.1, 0.5, 0.9) // Small Positive
diffN_NZ := fuzzy_triangle(normalized_diff_clamped, -0.2, 0.0, 0.2) // Near Zero
diffN_SN := fuzzy_triangle(normalized_diff_clamped, -0.9, -0.5, -0.1) // Small Negative
diffN_LN := fuzzy_triangle(normalized_diff_clamped, -3.0, -1.5, -0.7) // Large Negative (around/below percentile)
// ----- 3.2 Fuzzy Sets for ROC -----
roc_HN := fuzzy_triangle(roc_val, -8.0, -5.0, -2.0)
roc_WN := fuzzy_triangle(roc_val, -3.0, -1.0, -0.1)
roc_NZ := fuzzy_triangle(roc_val, -0.3, 0.0, 0.3)
roc_WP := fuzzy_triangle(roc_val, 0.1, 1.0, 3.0)
roc_HP := fuzzy_triangle(roc_val, 2.0, 5.0, 8.0)
// ----- 3.3 Fuzzy Sets for RSI -----
rsi_L := fuzzy_triangle(rsi_val, 0.0, 25.0, 40.0)
rsi_M := fuzzy_triangle(rsi_val, 35.0, 50.0, 65.0)
rsi_H := fuzzy_triangle(rsi_val, 60.0, 75.0, 100.0)
Advanced Fuzzy Inference Rules
The indicator employs a comprehensive set of fuzzy rules that encode expert knowledge about market behavior:
// --- Fuzzy Rules using Normalized Deviation (diffN_*) ---
cond1 = math.min(diffN_LP, roc_HP, math.max(rsi_M, rsi_H)) // Strong Bullish: Large pos dev, strong pos roc, rsi ok
strength_SB := math.max(strength_SB, cond1)
cond2 = math.min(diffN_SP, roc_WP, rsi_M) // Weak Bullish: Small pos dev, weak pos roc, rsi mid
strength_WB := math.max(strength_WB, cond2)
cond3 = math.min(diffN_SP, roc_NZ, rsi_H) // Weakening Bullish: Small pos dev, flat roc, rsi high
strength_N := math.max(strength_N, cond3 * 0.6) // More neutral
strength_WB := math.max(strength_WB, cond3 * 0.2) // Less weak bullish
This rule system evaluates multiple conditions simultaneously, weighting them by their degree of membership to produce a comprehensive trend assessment. The rules are designed to identify various market conditions including strong trends, weakening trends, potential reversals, and neutral consolidations.
Defuzzification Process
The final step transforms the fuzzy result back into a crisp numerical value representing the overall trend strength:
// --- Step 6: Defuzzification ---
denominator = strength_SB + strength_WB + strength_N + strength_WBe + strength_SBe
if denominator > 1e-10 // Use small epsilon instead of != 0.0 for float comparison
fuzzyTrendScore := (strength_SB * STRONG_BULL +
strength_WB * WEAK_BULL +
strength_N * NEUTRAL +
strength_WBe * WEAK_BEAR +
strength_SBe * STRONG_BEAR) / denominator
The resulting FuzzyTrendScore ranges from -1 (strong bearish) to +1 (strong bullish), providing a smooth, continuous evaluation of market conditions that avoids the abrupt signal changes common in traditional indicators.
Advanced Visualization with Rainbow Gradient
The indicator incorporates sophisticated visualization using a rainbow gradient coloring system:
// Normalize score to for gradient function
normalizedScore = na(fuzzyTrendScore) ? 0.5 : math.max(0.0, math.min(1.0, (fuzzyTrendScore + 1) / 2))
// Get the color based on gradient setting and normalized score
final_color = get_gradient(normalizedScore, gradient_type)
This color-coding system provides intuitive visual feedback, with color intensity reflecting trend strength and direction. The gradient can be customized between Red-to-Green or Red-to-Blue configurations based on user preference.
Practical Applications
The Fuzzy SMA Trend Analyzer excels in several key applications:
Trend Identification: Precisely identifies market trend direction and strength with nuanced gradation
Market Regime Detection: Distinguishes between trending markets and consolidation phases
Divergence Analysis: Highlights potential reversals when price action and fuzzy trend score diverge
Filter for Trading Systems: Provides high-quality trend filtering for other trading strategies
Risk Management: Offers early warning of potential trend weakening or reversal
Parameter Customization
The indicator offers extensive customization options:
SMA Length: Adjusts the baseline moving average period
ROC Length: Controls momentum sensitivity
RSI Length: Configures overbought/oversold sensitivity
Normalization Lookback: Determines the adaptive calculation window for percentile normalization
Percentile Rank: Sets the statistical threshold for deviation normalization
Gradient Type: Selects the preferred color scheme for visualization
These parameters enable fine-tuning to specific market conditions, trading styles, and timeframes.
Acknowledgments
The rainbow gradient visualization component draws inspiration from LuxAlgo's "Rainbow Adaptive RSI" (used under CC BY-NC-SA 4.0 license). This implementation of fuzzy logic in technical analysis builds upon Fermi estimation principles to overcome the inherent limitations of crisp binary indicators.
This indicator is shared under Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) license.
Remember that past performance does not guarantee future results. Always conduct thorough testing before implementing any technical indicator in live trading.

Stochastic Fusion Elite [trade_lexx]📈 Stochastic Fusion Elite is your reliable trading assistant!
📊 What is Stochastic Fusion Elite ?
Stochastic Fusion Elite is a trading indicator based on a stochastic oscillator. It analyzes the rate of price change and generates buy or sell signals based on various technical analysis methods.
💡 The main components of the indicator
📊 Stochastic oscillator (K and D)
Stochastic shows the position of the current price relative to the price range for a certain period. Values above 80 indicate overbought (an early sale is possible), and values below 20 indicate oversold (an early purchase is possible).
📈 Moving Averages (MA)
The indicator uses 10 different types of moving averages to smooth stochastic lines.:
- SMA: Simple moving average
- EMA: Exponential moving average
- WMA: Weighted moving average
- HMA: Moving Average Scale
- KAMA: Kaufman Adaptive Moving Average
- VWMA: Volume-weighted moving average
- ALMA: Arnaud Legoux Moving Average
- TEMA: Triple exponential moving average
- ZLEMA: zero delay exponential moving average
- DEMA: Double exponential moving average
The choice of the type of moving average affects the speed of the indicator's response to market changes.
🎯 Bollinger Bands (BB)
Bands around the moving average that widen and narrow depending on volatility. They help determine when the stochastic is out of the normal range.
🔄 Divergences
Divergences show discrepancies between price and stochastic:
- Bullish divergence: price is falling and stochastic is rising — an upward reversal is possible
- Bearish divergence: the price is rising, and stochastic is falling — a downward reversal is possible
🔍 Indicator signals
1️⃣ KD signals (K and D stochastic lines)
- Buy signal:
- What happens: the %K line crosses the %D line from bottom to top
- What does it look like: a green triangle with the label "KD" under the chart and the label "Buy" below the bar
- What does this mean: the price is gaining an upward momentum, growth is possible
- Sell signal:
- What happens: the %K line crosses the %D line from top to bottom
- What it looks like: a red triangle with the label "KD" above the chart and the label "Sell" above the bar
- What does this mean: the price is losing its upward momentum, possibly falling
2️⃣ Moving Average Signals (MA)
- Buy Signal:
- What happens: stochastic crosses the moving average from bottom to top
- What it looks like: a green triangle with the label "MA" under the chart and the label "Buy" below the bar
- What does this mean: stochastic is starting to accelerate upward, price growth is possible
- Sell signal:
- What happens: stochastic crosses the moving average from top to bottom
- What it looks like: a red triangle with the label "MA" above the chart and the label "Sell" above the bar
- What does this mean: stochastic is starting to accelerate downwards, a price drop is possible
3️⃣ Bollinger Band Signals (BB)
- Buy signal:
- What happens: stochastic crosses the lower Bollinger band from bottom to top
- What it looks like: a green triangle with the label "BB" under the chart and the label "Buy" below the bar
- What does this mean: stochastic was too low and is now starting to recover
- Sell signal:
- What happens: Stochastic crosses the upper Bollinger band from top to bottom
- What it looks like: a red triangle with a "BB" label above the chart and a "Sell" label above the bar
- What does this mean: stochastic was too high and is now starting to decline
4️⃣ Divergence Signals (Div)
- Buy Signal (Bullish Divergence):
- What's happening: the price is falling, and stochastic is forming higher lows
- What it looks like: a green triangle with a "Div" label under the chart and a "Buy" label below the bar
- What does this mean: despite the falling price, the momentum is already changing in an upward direction
- Sell signal (bearish divergence):
- What's going on: the price is rising, and stochastic is forming lower highs
- What it looks like: a red triangle with a "Div" label above the chart and a "Sell" label above the bar
- What does this mean: despite the price increase, the momentum is already weakening
🛠️ Filters to filter out false signals
1️⃣ Minimum distance between the signals
- What it does: sets the minimum number of candles between signals
- Why it is needed: prevents signals from being too frequent during strong market fluctuations
- How to set it up: Set the number from 0 and above (default: 5)
2️⃣ "Waiting for the opposite signal" mode
- What it does: waits for a signal in the opposite direction before generating a new signal
- Why you need it: it helps you not to miss important trend reversals
- How to set up: just turn the function on or off
3️⃣ Filter by stochastic levels
- What it does: generates signals only when the stochastic is in the specified ranges
- Why it is needed: it helps to catch the moments when the market is oversold or overbought
- How to set up:
- For buy signals: set a range for oversold (for example, 1-20)
- For sell signals: set a range for overbought (for example, 80-100)
4️⃣ MFI filter
- What it does: additionally checks the values of the cash flow index (MFI)
- Why it is needed: confirms stochastic signals with cash flow data
- How to set it up:
- For buy signals: set the range for oversold MFI (for example, 1-25)
- For sell signals: set the range for overbought MFI (for example, 75-100)
5️⃣ The RSI filter
- What it does: additionally checks the RSI values to confirm the signals
- Why it is needed: adds additional confirmation from another popular indicator
- How to set up:
- For buy signals: set the range for oversold MFI (for example, 1-30)
- For sell signals: set the range for overbought MFI (for example, 70-100)
🔄 Signal combination modes
1️⃣ Normal mode
- How it works: all signals (KD, MA, BB, Div) work independently of each other
- When to use it: for general market analysis or when learning how to work with the indicator
2️⃣ "AND" Mode ("AND Mode")
- How it works: the alarm appears only when several conditions are triggered simultaneously
- Combination options:
- KD+MA: signals from the KD and moving average lines
- KD+BB: signals from KD lines and Bollinger bands
- KD+Div: signals from the KD and divergence lines
- KD+MA+BB: three signals simultaneously
- KD+MA+Div: three signals at the same time
- KD+BB+Div: three signals at the same time
- KD+MA+BB+Div: all four signals at the same time
- When to use: for more reliable but rare signals
🔌 Connecting to trading strategies
The indicator can be connected to your trading strategies using 6 different channels.:
1. Connector KD signals: connects only the signals from the intersection of lines K and D
2. Connector MA signals: connects only signals from moving averages
3. Connector BB signal: connects only the signals from the Bollinger bands
4. Connector divergence signals: connects only divergence signals
5. Combined Connector: connects any signals
6. Connector for "And" mode: connects only combined signals
🔔 Setting up alerts
The indicator can send alerts when alarms appear.:
- Alerts for KD: when the %K line crosses the %D line
- Alerts for MA: when stochastic crosses the moving average
- Alerts for BB: when stochastic crosses the Bollinger bands
- Divergence alerts: when a divergence is detected
- Combined alerts: for all types of alarms
- Alerts for "And" mode: for combined signals
🎭 What does the indicator look like on the chart ?
- Main lines K and D: blue and orange lines
- Overbought/oversold levels: horizontal lines at levels 20 and 80
- Middle line: dotted line at level 50
- Stochastic Moving Average: yellow line
- Bollinger bands: green lines around the moving average
- Signals: green and red triangles with corresponding labels
📚 How to start using Stochastic Fusion Elite
1️⃣ Initial setup
- Add an indicator to your chart
- Select the types of signals you want to use (KD, MA, BB, Div)
- Adjust the period and smoothing for the K and D lines
2️⃣ Filter settings
- Set the distance between the signals to get rid of unnecessary noise
- Adjust stochastic, MFI and RSI levels depending on the volatility of your asset
- If you need more reliable signals, turn on the "Waiting for the opposite signal" mode.
3️⃣ Operation mode selection
- First, use the standard mode to see all possible signals.
- When you get comfortable, try the "And" mode for rarer signals.
4️⃣ Setting up Alerts
- Select the types of signals you want to be notified about
- Set up alerts for these types of signals
5️⃣ Verification and adaptation
- Check the operation of the indicator on historical data
- Adjust the parameters for a specific asset
- Adapt the settings to your trading style
🌟 Usage examples
For trend trading
- Use the KD and MA signals in the direction of the main trend
- Set the distance between the signals
- Set stricter levels for filters
For trading in a sideways range
- Use BB signals to detect bounces from the range boundaries
- Use a stochastic level filter to confirm overbought/oversold conditions
- Adjust the Bollinger bands according to the width of the range
To determine the pivot points
- Pay attention to the divergence signals
- Set the distance between the signals
- Check the MFI and RSI filters for additional confirmation

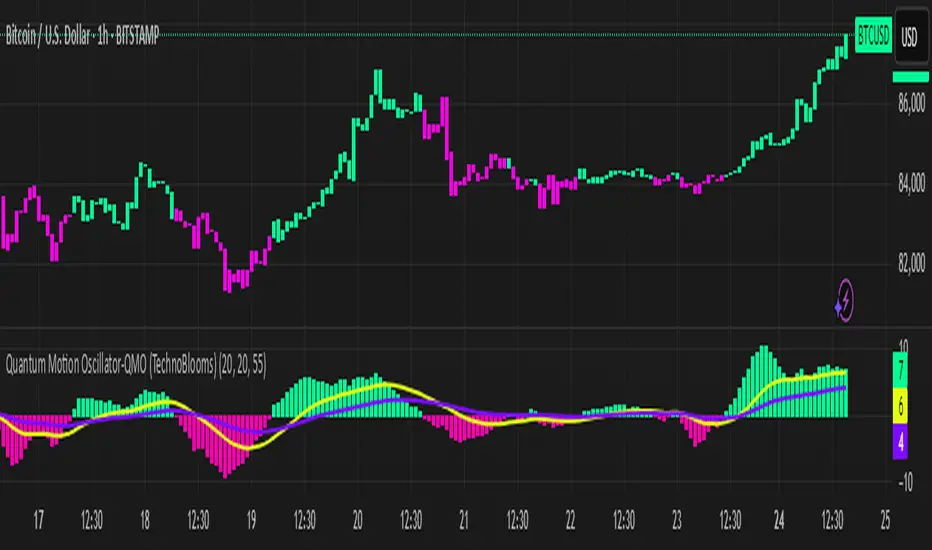
Quantum Motion Oscillator-QMO (TechnoBlooms)Quantum Motion Oscillator (QMO) is a momentum indicator designed for traders who demand precision. Combining multi-timeframe weighted linear regression with EMA crossovers, QMO offers a dynamic view of market momentum, helping traders anticipate trend shifts with greater accuracy.
This oscillator is inspired by quantum mechanics and wave theory, where market movement is seen as a series of probabilistic waves rather than rigid structures.
The histogram is plotted in proportion to the price movement of the candlesticks.
KEY FEATURES
1. Multi-Timeframe Histogram - Integrates 1 to 5 weighted linear regression averages, reducing lag while maintaining accuracy.
2. EMA Crossover Signal - Uses a Short and Long EMA to confirm trend shifts with minimal noise.
3. Adaptive Trend Analysis - Self-adjusting mechanics make QMO effective in both ranging and trending markets.
4. Scalable for Different Trading Styles - Works seamlessly for scalping, intraday, swing and position trading.
ADVANCED PROFESSIONAL INSIGHTS
1. Wave Dynamics and Market Flow - Inspired by wave mechanics, QMO reflects the energy accumulation and dissipation in price movements.
Expanding histogram waves = Strong momentum surge
Contracting waves = Momentum weakening, potential reversal zone.
2. Liquidity and Order Flow Applications - QMO works well alongside liquidity concepts and smart money techniques:
Combine with Fair Value Gaps & Order Blocks -> Enter when QMO signals align with liquidity zones.
Avoid False Moves - If price sweeps liquidity, but QMO momentum diverges, it is a sign of potential smart money manipulation.
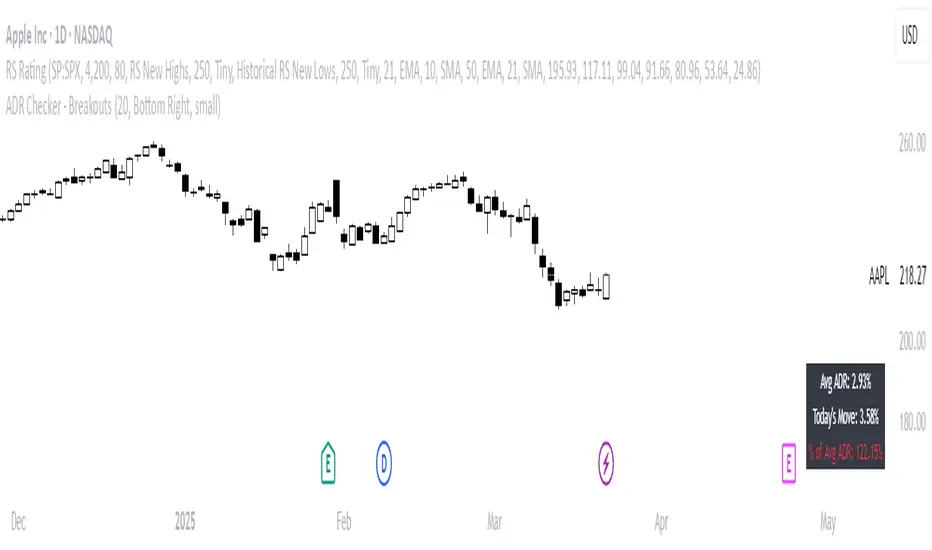
ADR Checker - Breakouts📈 ADR Checker – Breakouts
Gain the edge by knowing when a stock has already made its move.
🚀 What It Does:
The ADR Checker - Breakouts is a powerful yet simple visual tool that helps traders instantly assess whether a stock has already exceeded its Average Daily Range (ADR) for the day — a critical piece of information for momentum traders, swing traders, and especially those following breakout, VCP, or CANSLIM strategies.
Using a customizable on-screen table that always stays in view (regardless of zoom or chart scaling), this script shows:
✅ Average ADR% – 20-day average range, calculated in %.
📊 Today’s Move – how much the stock has moved today.
🔥 % of Avg ADR – today's move relative to its historical average, with live color feedback:
🟥 Over 100% (Overextended – danger!)
🟧 70-100% (Caution zone)
🟩 Below 70% (Room to move)
💡 Why It Matters:
One of the most overlooked mistakes by breakout traders is entering a trade after the move has already happened. If a stock has already moved more than its typical daily range, the odds of further continuation sharply decrease, while the risk of pullback or chop increases.
With this tool, you can:
🚫 Avoid chasing extended breakouts
🎯 Time entries before the real move
⚠️ Quickly assess risk/reward potential intraday
🧠 Example Use Case:
Imagine you're watching a classic VCP setup or flat base breakout. The stock breaks out on volume—but when you check this indicator, you see:
Today’s Move: 7.2%
Avg ADR: 5.3%
% of ADR: 135% 🟥
This tells you the stock is already well beyond its average daily range. While it may continue higher, odds now favor a consolidation, shakeout, or pullback. This is your cue to wait for a better entry or pass entirely.
On the flip side, if the breakout just started and the % of ADR is still under 50%, you have confirmation that there’s room to run — giving you more confidence to enter early.
⚙️ Fully Customizable:
Choose position on screen (top/bottom left/right)
Customize text color, background, and size
🔧 Install This Tool and:
✅ Stop chasing extended moves
✅ Add discipline to your entries
✅ Improve your breakout win rate
Perfect for VCP, CANSLIM, and BREAKOUT traders who want a clean, edge-enhancing visual guide.
TMO (True Momentum Oscillator)TMO ((T)rue (M)omentum (O)scilator)
Created by Mobius V01.05.2018 TOS Convert to TV using Claude 3.7 and ChatGPT 03 Mini :
TMO calculates momentum using the delta of price. Giving a much better picture of trend, tend reversals and divergence than momentum oscillators using price.
True Momentum Oscillator (TMO)
The True Momentum Oscillator (TMO) is a momentum-based technical indicator designed to identify trend direction, trend strength, and potential reversal points in the market. It's particularly useful for spotting overbought and oversold conditions, aiding traders in timing their entries and exits.
How it Works:
The TMO calculates market momentum by analyzing recent price action:
Momentum Calculation:
For a user-defined length (e.g., 14 bars), TMO compares the current closing price to past open prices. It assigns:
+1 if the current close is greater than the open price of the past bar (indicating bullish momentum).
-1 if it's less (indicating bearish momentum).
0 if there's no change.
The sum of these scores gives a raw momentum measure.
EMA Smoothing:
To reduce noise and false signals, this raw momentum is smoothed using Exponential Moving Averages (EMAs):
First, the raw data is smoothed by an EMA over a short calculation period (default: 5).
Then, it undergoes additional smoothing through another EMA (default: 3 bars), creating the primary "Main" line of the indicator.
Lastly, a "Signal" line is derived by applying another EMA (also default: 3 bars) to the main line, adding further refinement.
Trend Identification:
The indicator plots two lines:
Main Line: Indicates current momentum strength and direction.
Signal Line: Acts as a reference line, similar to a moving average crossover system.
When the Main line crosses above the Signal line, it suggests strengthening bullish momentum. Conversely, when the Main line crosses below the Signal line, it indicates increasing bearish momentum.
Overbought/Oversold Levels:
The indicator identifies key levels based on the chosen length parameter:
Overbought zone (positive threshold): Suggests the market might be overheated, and a potential bearish reversal or pullback could occur.
Oversold zone (negative threshold): Suggests the market might be excessively bearish, signaling a potential bullish reversal.
Clouds visually mark these overbought/oversold areas, making it easy to see potential reversal zones.
Trading Applications:
Trend-following: Traders can enter positions based on crossovers of the Main and Signal lines.
Reversals: The overbought and oversold areas highlight high-probability reversal points.
Momentum confirmation: Use TMO to confirm price action or other technical signals, improving trade accuracy and timing.
The True Momentum Oscillator provides clarity in identifying momentum shifts, making it a valuable addition to various trading strategies.

Choppiness IndicatorE.W. Dreiss, an Australian commodity trader, developed the Choppiness Index in 1993, drawing upon chaos theory to analyze financial markets. This technical indicator helps traders determine whether a market is trending or experiencing sideways (choppy) price action.
#Hint: The Market is considered TRENDING when the index is below 38.2 The Market is considered CHOPPY when the index is above 61.8. A move above the 38.2 Level indicates a possible end to a trend, and a move below 61.8 indicates a possible breakout from a period of consolidation.
Mobius constructed this in Thinkscript V001.03.2012, and Claude 3.7 Sonnet converted it to Pinescript V002. 03.2025
The Market is considered TRENDING when the index is below 38.2 The Market is considered CHOPPY when the index is above 61.8. A move above the 38.2 Level indicates a possible end to a trend, and a move below 61.8 indicates a potential breakout from a period of consolidation.

SMIIOLThis indicator generates long signals.
The operation of the indicator is as follows;
First, true strength index is calculated with closing prices. We call this the "ergodic" curve.
Then the average of the ergodic (ema) is calculated to obtain the "signal" curve.
To calculate the "oscillator", the signal is subtracted from ergodic (oscillator = ergodic - signal).
The last variable to be used in the calculation is the average volume, calculated with sma.
Calculation for long signal;
- If the ergodic curve cross up the lower band and,
- If the hma slope is positive,
If all the above conditions are fullfilled, the long input signal is issued with "Buy" label.

Dynamic Volume Profile Oscillator | AlphaAlgosDynamic Volume Profile Oscillator | AlphaAlgos
Overview
The Dynamic Volume Profile Oscillator is an advanced technical analysis tool that transforms traditional volume analysis into a responsive oscillator. By creating a dynamic volume profile and measuring price deviation from volume-weighted equilibrium levels, this indicator provides traders with powerful insights into market momentum and potential reversals.
Key Features
• Volume-weighted price deviation analysis
• Adaptive midline that adjusts to changing market conditions
• Beautiful gradient visualization with 10-level intensity zones
• Fast and slow signal lines for trend confirmation
• Mean reversion mode that identifies price extremes relative to volume
• Fully customizable sensitivity and smoothing parameters
Technical Components
1. Volume Profile Analysis
The indicator builds a dynamic volume profile by:
• Collecting recent price and volume data within a specified lookback period
• Calculating a volume-weighted mean price (similar to VWAP)
• Measuring how far current price has deviated from this weighted average
• Adjusting this deviation based on historical volatility
2. Oscillator Calculation
The oscillator offers two calculation methods:
• Mean Reversion Mode (default): Measures deviation from volume-weighted mean price, normalized to reflect potential overbought/oversold conditions
• Standard Mode : Normalizes volume activity to identify unusual volume patterns
3. Adaptive Zones
The indicator features dynamic zones that:
• Center around an adaptive midline that reflects the average oscillator value
• Expand and contract based on recent volatility (standard deviation)
• Visually represent intensity through multi-level gradient coloring
• Provide clear visualization of bullish/bearish extremes
4. Signal Generation
Trading signals are generated through:
• Main oscillator line position relative to the adaptive midline
• Crossovers between fast (5-period) and slow (15-period) signal lines
• Color changes that instantly identify trend direction
• Distance from the midline indicating trend strength
Configuration Options
Volume Analysis Settings:
• Price Source - Select which price data to analyze
• Volume Source - Define volume data source
• Lookback Period - Number of bars for main calculations
• Profile Calculation Periods - Frequency of profile recalculation
Oscillator Settings:
• Smoothing Length - Controls oscillator smoothness
• Sensitivity - Adjusts responsiveness to price/volume changes
• Mean Reversion Mode - Toggles calculation methodology
Threshold Settings:
• Adaptive Midline - Uses dynamic midline based on historical values
• Midline Period - Lookback period for midline calculation
• Zone Width Multiplier - Controls width of bullish/bearish zones
Display Settings:
• Color Bars - Option to color price bars based on trend direction
Trading Strategies
Trend Following:
• Enter long positions when the oscillator crosses above the adaptive midline
• Enter short positions when the oscillator crosses below the adaptive midline
• Use signal line crossovers for entry timing
• Monitor gradient intensity to gauge trend strength
Mean Reversion Trading:
• Look for oscillator extremes shown by intense gradient colors
• Prepare for potential reversals when the oscillator reaches upper/lower zones
• Use divergences between price and oscillator for confirmation
• Consider scaling positions based on gradient intensity
Volume Analysis:
• Use Standard Mode to identify unusual volume patterns
• Confirm breakouts when accompanied by strong oscillator readings
• Watch for divergences between price and volume-based readings
• Use extended periods in extreme zones as trend confirmation
Best Practices
• Adjust sensitivity based on the asset's typical volatility
• Use longer smoothing for swing trading, shorter for day trading
• Combine with support/resistance levels for optimal entry/exit points
• Consider multiple timeframe analysis for comprehensive market view
• Test different profile calculation periods to match your trading style
This indicator is provided for informational purposes only. Always use proper risk management when trading based on any technical indicator. Not financial advise.

Multi-Oscillator Adaptive Kernel | AlphaAlgosMulti-Oscillator Adaptive Kernel | AlphaAlgos
Overview
The Multi-Oscillator Adaptive Kernel (MOAK) is an advanced technical analysis tool that combines multiple oscillators through sophisticated kernel-based smoothing algorithms. This indicator is designed to provide clearer trend signals while filtering out market noise, offering traders a comprehensive view of market momentum across multiple timeframes.
Key Features
• Fusion of multiple technical oscillators (RSI, Stochastic, MFI, CCI)
• Advanced kernel smoothing technology with three distinct mathematical models
• Customizable sensitivity and lookback periods
• Clear visual signals for trend shifts and reversals
• Overbought/oversold zones for precise entry and exit timing
• Adaptive signal that responds to varying market conditions
Technical Components
The MOAK indicator utilizes a multi-layer approach to signal generation:
1. Oscillator Fusion
The core of the indicator combines normalized readings from up to four popular oscillators:
• RSI (Relative Strength Index) - Measures the speed and change of price movements
• Stochastic - Compares the closing price to the price range over a specific period
• MFI (Money Flow Index) - Volume-weighted RSI that includes trading volume
• CCI (Commodity Channel Index) - Measures current price level relative to an average price
2. Kernel Smoothing
The combined oscillator data is processed through one of three kernel functions:
• Exponential Kernel - Provides stronger weighting to recent data with exponential decay
• Linear Kernel - Applies a linear weighting from most recent to oldest data points
• Gaussian Kernel - Uses a bell curve distribution that helps filter out extreme values
3. Dual Signal Lines
• Fast Signal Line - Responds quickly to price changes
• Slow Signal Line - Provides confirmation and shows the underlying trend direction
Configuration Options
Oscillator Selection:
• Enable/disable each oscillator (RSI, Stochastic, MFI, CCI)
• Customize individual lookback periods for each oscillator
Kernel Settings:
• Kernel Type - Choose between Exponential, Linear, or Gaussian mathematical models
• Kernel Length - Adjust the smoothing period (higher values = smoother line)
• Sensitivity - Fine-tune the indicator's responsiveness (higher values = more responsive)
Display Options:
• Color Bars - Toggle price bar coloring based on indicator direction
How to Interpret the Indicator
Signal Line Direction:
• Upward movement (teal) indicates bullish momentum
• Downward movement (magenta) indicates bearish momentum
Trend Shifts:
• Small circles mark the beginning of new uptrends
• X-marks indicate the start of new downtrends
Overbought/Oversold Conditions:
• Values above +50 suggest overbought conditions (potential reversal or pullback)
• Values below -50 suggest oversold conditions (potential reversal or bounce)
Trading Strategies
Trend Following:
• Enter long positions when the signal line turns teal and shows an uptrend
• Enter short positions when the signal line turns magenta and shows a downtrend
• Use the slow signal line (area fill) as confirmation of the underlying trend
Counter-Trend Trading:
• Look for divergences between price and the indicator
• Consider profit-taking when the indicator reaches overbought/oversold areas
• Wait for trend shift signals before entering counter-trend positions
Multiple Timeframe Analysis:
• Use the indicator across different timeframes for confirmation
• Higher timeframe signals carry more weight than lower timeframe signals
Best Practices
• Experiment with different kernel types for various market conditions
• Gaussian kernels often work well in ranging markets
• Exponential kernels can provide earlier signals in trending markets
• Combine with volume analysis for higher probability trades
• Use appropriate stop-loss levels as the indicator does not guarantee price movements
This indicator is provided as-is with no guarantees of profit. Always use proper risk management when trading with any technical indicator. Nothing is financial advise.
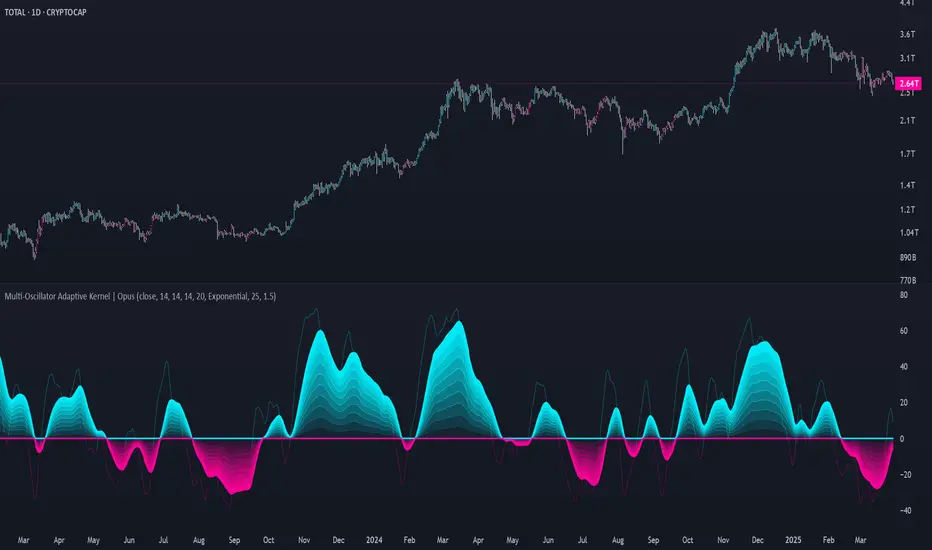
Smart Liquidity Wave [The_lurker]"Smart Liquidity Wave" هو مؤشر تحليلي متطور يهدف لتحديد نقاط الدخول والخروج المثلى بناءً على تحليل السيولة، قوة الاتجاه، وإشارات السوق المفلترة. يتميز المؤشر بقدرته على تصنيف الأدوات المالية إلى أربع فئات سيولة (ضعيفة، متوسطة، عالية، عالية جدًا)، مع تطبيق شروط مخصصة لكل فئة تعتمد على تحليل الموجات السعرية، الفلاتر المتعددة، ومؤشر ADX.
فكرة المؤشر
الفكرة الأساسية هي الجمع بين قياس السيولة اليومية الثابتة وتحليل ديناميكي للسعر باستخدام فلاتر متقدمة لتوليد إشارات دقيقة. المؤشر يركز على تصفية الضوضاء في السوق من خلال طبقات متعددة من التحليل، مما يجعله أداة ذكية تتكيف مع الأدوات المالية المختلفة بناءً على مستوى سيولتها.
طريقة عمل المؤشر
1- قياس السيولة:
يتم حساب السيولة باستخدام متوسط حجم التداول على مدى 14 يومًا مضروبًا في سعر الإغلاق، ويتم ذلك دائمًا على الإطار الزمني اليومي لضمان ثبات القيمة بغض النظر عن الإطار الزمني المستخدم في الرسم البياني.
يتم تصنيف السيولة إلى:
ضعيفة: أقل من 5 ملايين (قابل للتعديل).
متوسطة: من 5 إلى 20 مليون.
عالية: من 20 إلى 50 مليون.
عالية جدًا: أكثر من 50 مليون.
هذا الثبات في القياس يضمن أن تصنيف السيولة لا يتغير مع تغير الإطار الزمني، مما يوفر أساسًا موثوقًا للإشارات.
2- تحليل الموجات السعرية:
يعتمد المؤشر على تحليل الموجات باستخدام متوسطات متحركة متعددة الأنواع (مثل SMA، EMA، WMA، HMA، وغيرها) يمكن للمستخدم اختيارها وتخصيص فتراتها ، يتم دمج هذا التحليل مع مؤشرات إضافية مثل RSI (مؤشر القوة النسبية) وMFI (مؤشر تدفق الأموال) بوزن محدد (40% للموجات، 30% لكل من RSI وMFI) للحصول على تقييم شامل للاتجاه.
3- الفلاتر وطريقة عملها:
المؤشر يستخدم نظام فلاتر متعدد الطبقات لتصفية الإشارات وتقليل الضوضاء، وهي من أبرز الجوانب المخفية التي تعزز دقته:
الفلتر الرئيسي (Main Filter):
يعمل على تنعيم التغيرات السعرية السريعة باستخدام معادلة رياضية تعتمد على تحليل الإشارات (Signal Processing).
يتم تطبيقه على السعر لاستخراج الاتجاهات الأساسية بعيدًا عن التقلبات العشوائية، مع فترة زمنية قابلة للتعديل (افتراضي: 30).
يستخدم تقنية مشابهة للفلاتر عالية التردد (High-Pass Filter) للتركيز على الحركات الكبيرة.
الفلتر الفرعي (Sub Filter):
يعمل كطبقة ثانية للتصفية، مع فترة أقصر (افتراضي: 12)، لضبط الإشارات بدقة أكبر.
يستخدم معادلات تعتمد على الترددات المنخفضة للتأكد من أن الإشارات الناتجة تعكس تغيرات حقيقية وليست مجرد ضوضاء.
إشارة الزناد (Signal Trigger):
يتم تطبيق متوسط متحرك على نتائج الفلتر الرئيسي لتوليد خط إشارة (Signal Line) يُقارن مع عتبات محددة للدخول والخروج.
يمكن تعديل فترة الزناد (افتراضي: 3 للدخول، 5 للخروج) لتسريع أو تبطيء الإشارات.
الفلتر المربع (Square Filter):
خاصية مخفية تُفعّل افتراضيًا تعزز دقة الفلاتر عن طريق تضييق نطاق التذبذبات المسموح بها، مما يقلل من الإشارات العشوائية في الأسواق المتقلبة.
4- تصفية الإشارات باستخدام ADX:
يتم استخدام مؤشر ADX كفلتر نهائي للتأكد من قوة الاتجاه قبل إصدار الإشارة:
ضعيفة ومتوسطة: دخول عندما يكون ADX فوق 40، خروج فوق 50.
عالية: دخول فوق 40، خروج فوق 55.
عالية جدًا: دخول فوق 35، خروج فوق 38.
هذه العتبات قابلة للتعديل، مما يسمح بتكييف المؤشر مع استراتيجيات مختلفة.
5- توليد الإشارات:
الدخول: يتم إصدار إشارة شراء عندما تنخفض خطوط الإشارة إلى ما دون عتبة محددة (مثل -9) مع تحقق شروط الفلاتر، السيولة، وADX.
الخروج: يتم إصدار إشارة بيع عندما ترتفع الخطوط فوق عتبة (مثل 109 أو 106 حسب الفئة) مع تحقق الشروط الأخرى.
تُعرض الإشارات بألوان مميزة (أزرق للدخول، برتقالي للضعيفة والمتوسطة، أحمر للعالية والعالية جدًا) وبثلاثة أحجام (صغير، متوسط، كبير).
6- عرض النتائج:
يظهر مستوى السيولة الحالي في جدول في أعلى يمين الرسم البياني، مما يتيح للمستخدم معرفة فئة الأصل بسهولة.
7- دعم التنبيهات:
تنبيهات فورية لكل فئة سيولة، مما يسهل التداول الآلي أو اليدوي.
%%%%% الجوانب المخفية في الكود %%%%%
معادلات الفلاتر المتقدمة: يستخدم المؤشر معادلات رياضية معقدة مستوحاة من معالجة الإشارات لتنعيم البيانات واستخراج الاتجاهات، مما يجعله أكثر دقة من المؤشرات التقليدية.
التكيف التلقائي: النظام يضبط نفسه داخليًا بناءً على التغيرات في السعر والحجم، مع عوامل تصحيح مخفية (مثل معامل التنعيم في الفلاتر) للحفاظ على الاستقرار.
التوزيع الموزون: الدمج بين الموجات، RSI، وMFI يتم بأوزان محددة (40%، 30%، 30%) لضمان توازن التحليل، وهي تفاصيل غير ظاهرة مباشرة للمستخدم لكنها تؤثر على النتائج.
الفلتر المربع: خيار مخفي يتم تفعيله افتراضيًا لتضييق نطاق الإشارات، مما يقلل من التشتت في الأسواق ذات التقلبات العالية.
مميزات المؤشر
1- فلاتر متعددة الطبقات: تضمن تصفية الضوضاء وإنتاج إشارات موثوقة فقط.
2- ثبات السيولة: قياس السيولة اليومي يجعل التصنيف متسقًا عبر الإطارات الزمنية.
3- تخصيص شامل: يمكن تعديل حدود السيولة، عتبات ADX، فترات الفلاتر، وأنواع المتوسطات المتحركة.
4- إشارات مرئية واضحة: تصميم بصري يسهل التفسير مع تنبيهات فورية.
5- تقليل الإشارات الخاطئة: الجمع بين الفلاتر وADX يعزز الدقة ويقلل من التشتت.
إخلاء المسؤولية
لا يُقصد بالمعلومات والمنشورات أن تكون، أو تشكل، أي نصيحة مالية أو استثمارية أو تجارية أو أنواع أخرى من النصائح أو التوصيات المقدمة أو المعتمدة من TradingView.
#### **What is the Smart Liquidity Wave Indicator?**
"Smart Liquidity Wave" is an advanced analytical indicator designed to identify optimal entry and exit points based on liquidity analysis, trend strength, and filtered market signals. It stands out with its ability to categorize financial instruments into four liquidity levels (Weak, Medium, High, Very High), applying customized conditions for each category based on price wave analysis, multi-layered filters, and the ADX (Average Directional Index).
#### **Concept of the Indicator**
The core idea is to combine a stable daily liquidity measurement with dynamic price analysis using sophisticated filters to generate precise signals. The indicator focuses on eliminating market noise through multiple analytical layers, making it an intelligent tool that adapts to various financial instruments based on their liquidity levels.
#### **How the Indicator Works**
1. **Liquidity Measurement:**
- Liquidity is calculated using the 14-day average trading volume multiplied by the closing price, always based on the daily timeframe to ensure value consistency regardless of the chart’s timeframe.
- Liquidity is classified as:
- **Weak:** Less than 5 million (adjustable).
- **Medium:** 5 to 20 million.
- **High:** 20 to 50 million.
- **Very High:** Over 50 million.
- This consistency in measurement ensures that liquidity classification remains unchanged across different timeframes, providing a reliable foundation for signals.
2. **Price Wave Analysis:**
- The indicator relies on wave analysis using various types of moving averages (e.g., SMA, EMA, WMA, HMA, etc.), which users can select and customize in terms of periods.
- This analysis is integrated with additional indicators like RSI (Relative Strength Index) and MFI (Money Flow Index), weighted specifically (40% waves, 30% RSI, 30% MFI) to provide a comprehensive trend assessment.
3. **Filters and Their Functionality:**
- The indicator employs a multi-layered filtering system to refine signals and reduce noise, a key hidden feature that enhances its accuracy:
- **Main Filter:**
- Smooths rapid price fluctuations using a mathematical equation rooted in signal processing techniques.
- Applied to price data to extract core trends away from random volatility, with an adjustable period (default: 30).
- Utilizes a technique similar to high-pass filters to focus on significant movements.
- **Sub Filter:**
- Acts as a secondary filtering layer with a shorter period (default: 12) for finer signal tuning.
- Employs low-frequency-based equations to ensure resulting signals reflect genuine changes rather than mere noise.
- **Signal Trigger:**
- Applies a moving average to the main filter’s output to generate a signal line, compared against predefined entry and exit thresholds.
- Trigger period is adjustable (default: 3 for entry, 5 for exit) to speed up or slow down signals.
- **Square Filter:**
- A hidden feature activated by default, enhancing filter precision by narrowing the range of permissible oscillations, reducing random signals in volatile markets.
4. **Signal Filtering with ADX:**
- ADX is used as a final filter to confirm trend strength before issuing signals:
- **Weak and Medium:** Entry when ADX exceeds 40, exit above 50.
- **High:** Entry above 40, exit above 55.
- **Very High:** Entry above 35, exit above 38.
- These thresholds are adjustable, allowing the indicator to adapt to different trading strategies.
5. **Signal Generation:**
- **Entry:** A buy signal is triggered when signal lines drop below a specific threshold (e.g., -9) and conditions for filters, liquidity, and ADX are met.
- **Exit:** A sell signal is issued when signal lines rise above a threshold (e.g., 109 or 106, depending on the category) with all conditions satisfied.
- Signals are displayed in distinct colors (blue for entry, orange for Weak/Medium, red for High/Very High) and three sizes (small, medium, large).
6. **Result Display:**
- The current liquidity level is shown in a table at the top-right of the chart, enabling users to easily identify the asset’s category.
7. **Alert Support:**
- Instant alerts are provided for each liquidity category, facilitating both automated and manual trading.
#### **Hidden Aspects in the Code**
- **Advanced Filter Equations:** The indicator uses complex mathematical formulas inspired by signal processing to smooth data and extract trends, making it more precise than traditional indicators.
- **Automatic Adaptation:** The system internally adjusts based on price and volume changes, with hidden correction factors (e.g., smoothing coefficients in filters) to maintain stability.
- **Weighted Distribution:** The integration of waves, RSI, and MFI uses fixed weights (40%, 30%, 30%) for balanced analysis, a detail not directly visible but impactful on results.
- **Square Filter:** A hidden option, enabled by default, narrows signal range to minimize dispersion in high-volatility markets.
#### **Indicator Features**
1. **Multi-Layered Filters:** Ensures noise reduction and delivers only reliable signals.
2. **Liquidity Stability:** Daily liquidity measurement keeps classification consistent across timeframes.
3. **Comprehensive Customization:** Allows adjustments to liquidity thresholds, ADX levels, filter periods, and moving average types.
4. **Clear Visual Signals:** User-friendly design with easy-to-read visuals and instant alerts.
5. **Reduced False Signals:** Combining filters and ADX enhances accuracy and minimizes clutter.
#### **Disclaimer**
The information and publications are not intended to be, nor do they constitute, financial, investment, trading, or other types of advice or recommendations provided or endorsed by TradingView.
EMA Clouds with Strict Buy/Sell SignalsEMA Clouds with Strict Buy/Sell Signals - Precision Trading Unleashed
Unlock the power of trend-following precision with the EMA Clouds with Strict Buy/Sell Signals indicator, a sophisticated tool built for traders who demand reliability and clarity in their decision-making. Inspired by the legendary Ripster EMA Clouds, this indicator takes the classic cloud concept to the next level by incorporating stricter, high-confidence signals—perfect for navigating the markets on 15-minute or higher timeframes.
Why You’ll Want This on Your Chart:
Dual EMA Clouds for Crystal-Clear Trends: Watch as two dynamic clouds—formed by carefully paired Exponential Moving Averages (8/21 and 34/50)—paint a vivid picture of market momentum. The green short-term cloud and red long-term cloud provide an intuitive, at-a-glance view of trend direction and strength.
Stricter Signals, Fewer False Moves: Tired of chasing weak signals? This indicator only triggers buy and sell signals when the stars align: a cloud crossover (short-term crossing above or below long-term) and price confirmation above or below both clouds. The result? Fewer trades, higher conviction, and a cleaner chart.
Customizable Timeframe Power: Whether you’re a scalper on the 15-minute chart or a swing trader on the daily, tailor the clouds to your preferred higher timeframe (15min, 30min, 1hr, 4hr, or daily) for seamless integration into your strategy.
Visual Mastery Meets Actionable Alerts: Green buy triangles below the bars and red sell triangles above them make spotting opportunities effortless. Pair this with built-in alerts, and you’ll never miss a high-probability trade again.
How It Works:
Buy Signal: Triggers when the short-term cloud crosses above the long-term cloud and the price surges above both, signaling a robust bullish breakout.
Sell Signal: Activates when the short-term cloud dips below the long-term cloud and the price falls beneath both, confirming bearish dominance.
Cloud Visualization: The green cloud (8/21 EMA) tracks fast-moving trends, while the red cloud (34/50 EMA) anchors the broader market direction—together, they filter noise and spotlight tradable moves.
Why Traders Will Love It:
Designed for those who value precision over guesswork, this indicator cuts through market clutter to deliver signals you can trust. Whether you’re trading stocks, forex, crypto, or futures, its adaptability and strict logic make it a must-have tool for serious traders. Customize the EMA lengths, tweak the timeframe, and watch your edge sharpen.
Add EMA Clouds with Strict Buy/Sell Signals to your chart today and experience the confidence of trading with a tool that’s as disciplined as you are. Your next big move is waiting—don’t let it slip away.
TASC 2025.04 The Ultimate Oscillator█ OVERVIEW
This script implements an alternative, refined version of the Ultimate Oscillator (UO) designed to reduce lag and enhance responsiveness in momentum indicators, as introduced by John F. Ehlers in his article "Less Lag In Momentum Indicators, The Ultimate Oscillator" from the April 2025 edition of TASC's Traders' Tips .
█ CONCEPTS
In his article, Ehlers states that indicators are essentially filters that remove unwanted noise (i.e., unnecessary information) from market data. Simply put, they process a series of data to place focus on specific information, providing a different perspective on price dynamics. Various filter types attenuate different periodic signals within the data. For instance, a lowpass filter allows only low-frequency signals, a highpass filter allows only high-frequency signals, and a bandpass filter allows signals within a specific frequency range .
Ehlers explains that the key to removing indicator lag is to combine filters of different types in such a way that the result preserves necessary, useful signals while minimizing delay (lag). His proposed UltimateOscillator aims to maintain responsiveness to a specific frequency range by measuring the difference between two highpass filters' outputs. The oscillator uses the following formula:
UO = (HP1 - HP2) / RMS
Where:
HP1 is the first highpass filter.
HP2 is another highpass filter that allows only shorter wavelengths than the critical period of HP1.
RMS is the root mean square of the highpass filter difference, used as a scaling factor to standardize the output.
The resulting oscillator is similar to a bandpass filter , because it emphasizes wavelengths between the critical periods of the two highpass filters. Ehlers' UO responds quickly to value changes in a series, providing a responsive view of momentum with little to no lag.
█ USAGE
Ehlers' UltimateOscillator sets the critical periods of its highpass filters using two parameters: BandEdge and Bandwidth :
The BandEdge sets the critical period of the second highpass filter, which determines the shortest wavelengths in the response.
The Bandwidth is a multiple of the BandEdge used for the critical period of the first highpass filter, which determines the longest wavelengths in the response. Ehlers suggests that a Bandwidth value of 2 works well for most applications. However, traders can use any value above or equal to 1.4.
Users can customize these parameters with the "Bandwidth" and "BandEdge" inputs in the "Settings/Inputs" tab.
The script plots the UO calculated for the specified "Source" series in a separate pane, with a color based on the chart's foreground color. Positive UO values indicate upward momentum or trends, and negative UO values indicate the opposite.
Additionally, this indicator provides the option to display a "cloud" from 10 additional UO series with different settings for an aggregate view of momentum. The "Cloud" input offers four display choices: "Bandwidth", "BandEdge", "Bandwidth + BandEdge", or "None".
The "Bandwidth" option calculates oscillators with different Bandwidth values based on the main oscillator's setting. Likewise, the "BandEdge" option calculates oscillators with varying BandEdge values. The "Bandwidth + BandEdge" option calculates the extra oscillators with different values for both parameters.
When a user selects any of these options, the script plots the maximum and minimum oscillator values and fills their space with a color gradient. The fill color corresponds to the net sum of each UO's sign , indicating whether most of the UOs reflect positive or negative momentum. Green hues mean most oscillators are above zero, signifying stronger upward momentum. Red hues mean most are below zero, indicating stronger downward momentum.
Momentum Volume Divergence (MVD) EnhancedMomentum Volume Divergence (MVD) Enhanced is a powerful indicator that detects price-momentum divergences and momentum suppression for reversal trading. Optimized for XRP on 1D charts, it features dynamic lookbacks, ATR-adjusted thresholds, and SMA confirmation. Signals include strong divergences (triangles) and suppression warnings (crosses). Includes a detailed user guide—try it out and share your feedback!
Setup: Add to XRP 1D chart with defaults (mom_length_base=8, vol_length_base=10). Signals: Red triangle (sell), Green triangle (buy), Orange cross (bear warning), Yellow cross (bull warning). Confirm with 5-day SMA crossovers. See full guide for details!
Disclaimer: This indicator is for educational purposes only, not financial advice. Trading involves risk—use at your discretion.
Momentum Volume Divergence (MVD) Enhanced Indicator User Guide
Version: Pine Script v6
Designed for: TradingView
Recommended Use: XRP on 1-day (1D) chart
Date: March 18, 2025
Author: Herschel with assistance from Grok 3 (xAI)
Overview
The Momentum Volume Divergence (MVD) Enhanced indicator is a powerful tool for identifying price-momentum divergences and momentum suppression patterns on XRP’s 1-day (1D) chart. Plotted below the price chart, it provides clear visual signals to help traders spot potential reversals and trend shifts.
Purpose
Detect divergences between price and momentum for buy/sell opportunities.
Highlight momentum suppression as warnings of fading trends.
Offer actionable trading signals with intuitive markers.
Indicator Components
Main Plot
Volume-Weighted Momentum (vw_mom): Blue line showing momentum adjusted by volume.
Above 0 = bullish momentum.
Below 0 = bearish momentum.
Zero Line: Gray dashed line at 0, separating bullish/bearish zones.
Key Signals
Strong Bearish Divergence:
Marker: Red triangle at the top.
Meaning: Price makes a higher high, but momentum weakens, confirmed by a drop below the 5-day SMA.
Action: Potential sell/short signal.
Strong Bullish Divergence:
Marker: Green triangle at the bottom.
Meaning: Price makes a lower low, but momentum strengthens, confirmed by a rise above the 5-day SMA.
Action: Potential buy/long signal.
Bearish Suppression:
Marker: Orange cross at the top + red background.
Meaning: Strong bullish momentum with low volume in a volume downtrend, suggesting fading strength.
Action: Warning to avoid longs or exit early.
Bullish Suppression:
Marker: Yellow cross at the bottom + green background.
Meaning: Strong bearish momentum with low volume in a volume uptrend, suggesting fading weakness.
Action: Warning to avoid shorts or exit early.
Debug Plots (Optional)
Volume Ratio: Gray line (volume vs. its MA) vs. yellow line (threshold).
Momentum Threshold: Purple lines (positive/negative momentum cutoffs).
Smoothed Momentum: Orange line (raw momentum).
Confirmation SMA: Purple line (price trend confirmation).
Labels
Text labels (e.g., "Bear Div," "Bull Supp") mark detected patterns.
How to Use the Indicator
Step-by-Step Trading Process
1. Monitor the Chart
Load your XRP 1D chart with the indicator applied.
Observe the blue vw_mom line and signal markers.
2. Spot a Signal
Primary Signals: Look for red triangles (strong_bear) or green triangles (strong_bull).
Warnings: Note orange crosses (suppression_bear) or yellow crosses (suppression_bull).
3. Confirm the Signal
For Strong Bullish Divergence (Buy):
Green triangle appears.
Price closes above the 5-day SMA (purple line) and a recent swing high.
Optional: Volume ratio (gray line) exceeds the threshold (yellow line).
For Strong Bearish Divergence (Sell):
Red triangle appears.
Price closes below the 5-day SMA and a recent swing low.
Optional: Volume ratio (gray line) falls below the threshold (yellow line).
4. Enter the Trade
Long:
Buy at the close of the signal bar.
Stop loss: Below the recent swing low or 2 × ATR(14) below entry.
Short:
Sell/short at the close of the signal bar.
Stop loss: Above the recent swing high or 2 × ATR(14) above entry.
5. Manage the Trade
Take Profit:
Aim for a 2:1 or 3:1 risk-reward ratio (e.g., risk $0.05, target $0.10-$0.15).
Or exit when an opposite suppression signal appears (e.g., orange cross for longs).
Trailing Stop:
Move stop to breakeven after a 1:1 RR move.
Trail using the 5-day SMA or 2 × ATR(14).
Early Exit:
Exit if a suppression signal appears against your position (e.g., suppression_bull while short).
6. Filter Out Noise
Avoid trades if a suppression signal precedes a divergence within 2-3 days.
Optional: Add a 50-day SMA on the price chart:
Longs only if price > 50-SMA.
Shorts only if price < 50-SMA.
Example Trades (XRP 1D)
Bullish Trade
Signal: Green triangle (strong_bull) at $0.55.
Confirmation: Price closes above 5-SMA and $0.57 high.
Entry: Buy at $0.58.
Stop Loss: $0.53 (recent low).
Take Profit: $0.63 (2:1 RR) or exit on suppression_bear.
Outcome: Price hits $0.64, exit at $0.63 for profit.
Bearish Trade
Signal: Red triangle (strong_bear) at $0.70.
Confirmation: Price closes below 5-SMA and $0.68 low.
Entry: Short at $0.67.
Stop Loss: $0.71 (recent high).
Take Profit: $0.62 (2:1 RR) or exit on suppression_bull.
Outcome: Price drops to $0.61, exit at $0.62 for profit.
Tips for Success
Combine with Price Levels:
Use support/resistance zones (e.g., weekly pivots) to confirm entries.
Monitor Volume:
Rising volume (gray line above yellow) strengthens signals.
Adjust Sensitivity:
Too many signals? Increase div_strength_threshold to 0.7.
Too few signals? Decrease to 0.3.
Backtest:
Review 20-30 past signals on XRP 1D to assess performance.
Avoid Choppy Markets:
Skip signals during low volatility (tight price ranges).
Troubleshooting
No Signals:
Lower div_strength_threshold to 0.3 or mom_threshold_base to 0.2.
Check if XRP’s volatility is unusually low.
False Signals:
Increase sma_confirm_length to 7 or add a 50-SMA filter.
Indicator Not Loading:
Ensure the script compiles without errors.
Customization (Optional)
Change Colors: Edit color.* values (e.g., color.red to color.purple).
Add Alerts: Use TradingView’s alert menu for "Strong Bearish Divergence Confirmed," etc.
Test Other Assets: Experiment with BTC or ETH, adjusting inputs as needed.
Disclaimer
This indicator is for educational purposes only and not financial advice. Trading involves risk, and past performance does not guarantee future results. Use at your own discretion.
Setup: Use on XRP 1D with defaults (mom_length_base=8, vol_length_base=10). Signals: Red triangle (sell), Green triangle (buy), Orange cross (bear warning), Yellow cross (bull warning). Confirm with 5-day SMA cross. Stop: 2x ATR(14). Profit: 2:1 RR or suppression exit. Full guide available separately!
FOMO Indicator - % of Stocks Above 5-Day AvgThe FOMO Indicator plots the breadth indicators NCFD and S5FD below the price chart, representing the percentage of stocks in the Nasdaq Composite (NCFD) or S&P 500 (S5FD) trading above their respective 5-day moving averages.
This indicator identifies short-term market sentiment and investor positioning. When over 85% of stocks exceed their 5-day averages, it signals widespread buying pressure and potential FOMO (Fear Of Missing Out) among investors. Conversely, levels below 15% may indicate oversold conditions. By analyzing these breadth metrics over a short time window, the FOMO Indicator helps traders gauge shifts in investor sentiment and positioning.