Long and Short Strategy with Multi Indicators [B1P5]Long and Short Strategy with RSI, ROC, MA Selection, Exit Visualization, and Strength Indicator
Forecasting

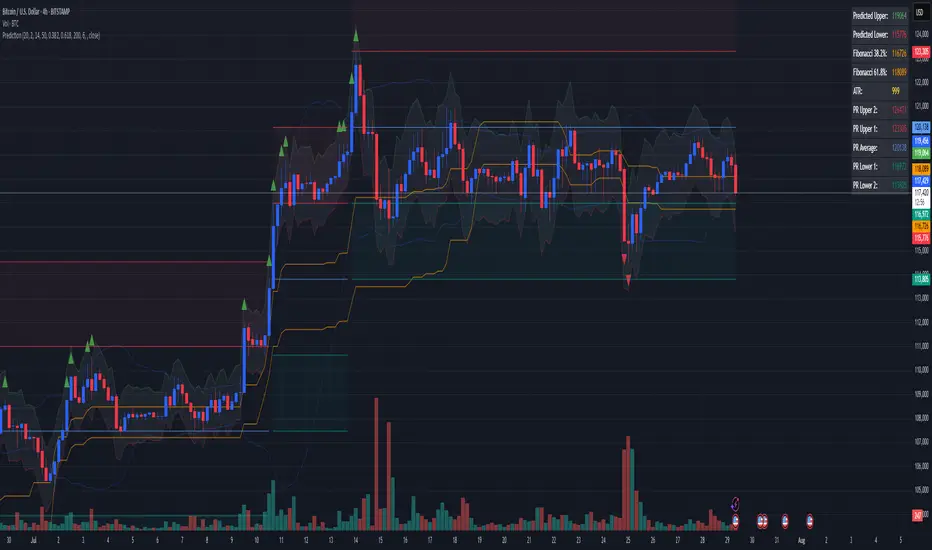
Combined Predictive Indicator### Combined Predictive Zones & Levels
This indicator is a powerful hybrid tool designed to provide a comprehensive map of potential future price action. It merges two distinct predictive models into a single, cohesive view, helping traders identify key levels of support, resistance, and areas of high confluence.
#### How It Works: Two Models in One
This script is built on two core components that you can use together or analyze separately:
**Part 1: Classic Range & Fibonacci Prediction**
This model uses classic technical analysis principles to project a potential range for the upcoming price action.
* **Highest High / Lowest Low:** It identifies the significant trading range over a user-defined lookback period.
* **Fibonacci Levels:** It automatically plots key Fibonacci retracement levels (e.g., 38.2% and 61.8%) within this range, which often act as critical support or resistance.
* **ATR & Average Range:** It calculates a "predicted" upper and lower boundary based on the average historical range and current volatility (ATR).
**Part 2: Advanced Predictive Ranges (Self-Adjusting Channels)**
This is a dynamic model that creates adaptive support and resistance zones based on a smoothed average price and volatility.
* **Dynamic Average:** It uses a unique moving average that only adjusts when the price moves significantly, creating a stable baseline.
* **ATR-Based Zones:** It projects multiple levels of support (S1, S2) and resistance (R1, R2) around this average, which widen and narrow based on market volatility. These zones often signal areas where price might stall or reverse.
#### Key Features:
* **Hybrid Model for Confluence:** The true power of this indicator lies in finding where the levels from both models overlap. A Fibonacci level aligning with a Predictive Range support zone is a much stronger signal.
* **Comprehensive Data Table:** A clean, on-chart table displays the precise values of all key predictive levels, allowing for quick reference and precise trade planning.
* **Multi-Timeframe (MTF) Capability:** The Advanced Predictive Ranges can be calculated on a higher timeframe, giving you a broader market context.
* **Fully Customizable:** All lengths, multipliers, and levels for both models are fully adjustable in the settings to fit any asset or trading style.
* **Clear Visuals:** All zones and levels are color-coded for intuitive and easy-to-read analysis.
#### How to Use:
1. Look for areas of **confluence** where multiple levels from both models cluster together. These are high-probability zones for price reactions.
2. Use the Predictive Range zones (S1/S2 and R1/R2) as potential targets for trades or as areas to watch for entries and exits.
3. Pay attention to the on-chart table for exact price levels to set limit orders or stop-losses.
**Disclaimer:** This script is an analytical tool for educational purposes and should not be considered financial advice. All trading involves risk. Past performance is not indicative of future results. Always use this indicator as part of a comprehensive trading strategy with proper risk management.
Feedback is welcome! If you find this tool useful, please leave a like.
3 EMA Pullback Strategy with ATRThis script will not only plot the moving averages but also identify potential trade setups by highlighting trend conditions, marking entry points, and dynamically plotting the corresponding Stop Loss and Take Profit levels directly on your chart.
Here is the Pine Script code for your strategy.

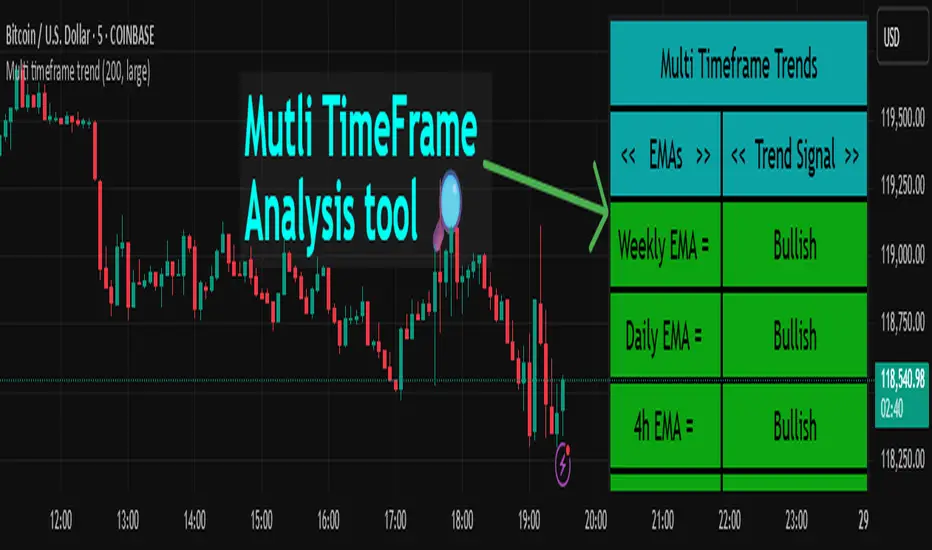
Multi timeframe trendDESCRIPTION
This indicator, Multi Timeframe Trend, is a powerful tool designed to give traders a comprehensive overview of market trends across multiple timeframes using a single, customizable Exponential Moving Average (EMA). It visually displays whether the price is trading above or below the EMA on each timeframe, helping traders quickly determine the dominant trend at a glance.
The real-time dashboard is plotted directly on your chart and color-coded to show bullish (green) or bearish (red) conditions per timeframe, from 15 minutes to 1 week. It is especially helpful for identifying trend alignment across multiple timeframes—an essential component of many professional trading strategies.
USER INPUTS
* Enter the EMA length – Adjust the EMA period used in the trend calculation (default: 200)
* Table Size – Choose how large the on-chart table appears: "tiny", "small", "normal", or "large"
INDICATOR LOGIC
* The indicator calculates the EMA for each of the following timeframes: 1W, 1D, 4H, 1H, 30M, and 15M
* It checks whether the current close is above or below each EMA and labels it as:
* Bullish if close > EMA
* Bearish if close < EMA
* Each timeframe’s trend is displayed in a dynamic table in the top-right corner of the chart
* The background color of each cell changes according to trend condition for quick visual interpretation
* Real-time responsiveness: handles both historical and live bars to maintain accurate, flicker-free updates
WHY IT IS UNIQUE
* Combines multiple timeframe trend analysis into a single glance
* Clean and color-coded dashboard overlay for real-time trading decisions
* Avoids repainting using barstate logic for accurate trend updates
* Fully customizable table size and EMA length
* Works on any chart, including stocks, crypto, forex, indices
HOW USERS CAN BENEFIT FROM IT
* Multi-timeframe confirmation: Easily confirm alignment across timeframes before entering a trade
* Avoid false signals by ensuring higher timeframe trends agree with lower timeframe setups
* Enhance strategy filters: Use as a trend filter in combination with your existing entry indicators
* Quick market analysis: No need to switch between charts or manually calculate EMAs
* Visual clarity: Trend conditions are easy to read and interpret in real-time
ATR as % of CloseATR 14day period in % terms
the Normal ATR indicator by TV helps but this gives a clear idea as to the range in percentage terms as and when market rises to newer and newer highs
better than an absolute value

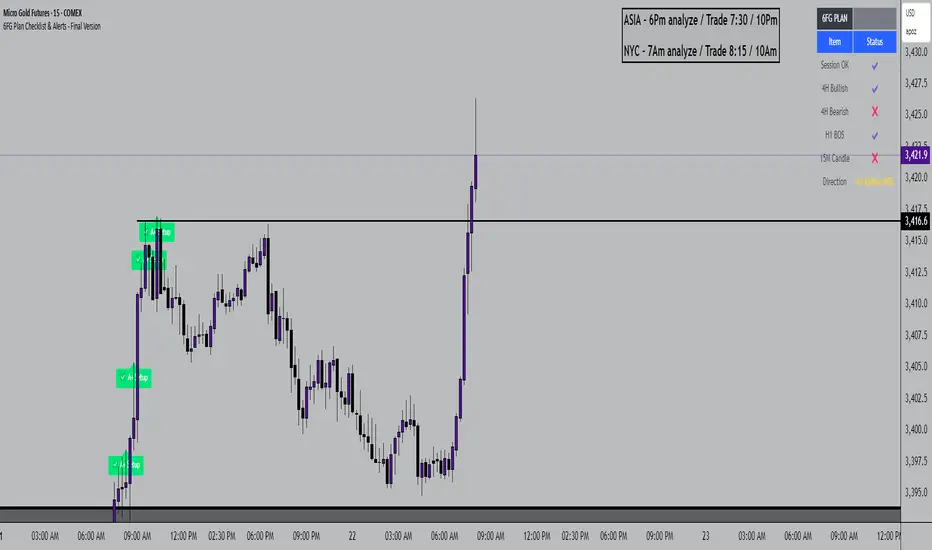
6FG Plan Checklist & Alerts - Final Version🧠 SCRIPT OVERVIEW: "6FG A+ SETUP - Simplified"
This script is designed to identify high-probability A+ trade setups in alignment with your personal 6FG trading plan, based on:
H1 Break of Structure (required)
4H trend confirmation
15M candle confirmation
Session filter
A+ Label & Visual Table Checklist
✅ KEY COMPONENTS
1. Toggle Inputs
These allow you to customize your view and filters without changing the code:
showSession: Only allow alerts inside Asian or NY sessions
show4hTrend: Include or ignore 4H directional bias
show15mConfirm: Include or ignore confirmation from 15M candles
showTable: Display checklist table on chart
showLabel: Display the “✅ A+” label on qualifying bars
2. Session Filter
Defines valid timeframes for trading (Asian or New York)
Helps avoid setups during low-liquidity hours
Controlled by showSession
3. 4H Trend (Confirmation Only)
Uses a 20-period SMA on 4H to detect general bias:
Bullish = Price above SMA
Bearish = Price below SMA
This trend is not mandatory for an alert if toggle is off
4. H1 Break of Structure (REQUIRED)
Looks at the highest high and lowest low of the last 10 candles on the 1H timeframe
Detects either:
Bullish BOS = Current close > highest high
Bearish BOS = Current close < lowest low
This is the core trigger for the A+ setup
If BOS doesn't happen, no entry is valid
5. 15M Confirmation Candles
(Optional - controlled by show15mConfirm)
Checks for one of three confirmation patterns:
Bullish Engulfing
Bearish Engulfing
Pin Bar
This adds confidence but can be toggled off
6. Entry Conditions (A+ Setup)
All the following must be true for entryOK = true:
✅ H1 BOS (required)
✅ Session is valid (if toggle is on)
✅ 15M confirmation pattern (if toggle is on)
✅ 4H trend (if toggle is on)
7. Visual Output
If entryOK = true:
✅ A green "A+" label appears below price
✅ A checklist table on the top-right shows:
Session status ✔️❌
4H bullish/bearish ✔️❌
H1 BOS ✔️❌
15M confirmation ✔️❌
Final Direction: Bullish / Bearish / —
A+ Setup: ✔️❌
8. Alerts
You will receive a TradingView alert when an A+ Setup is detected:
Enhanced Market Structure StrategyATR-Based Risk Management:
Stop Loss: 2 ATR from entry (configurable)
Take Profit: 3 ATR from entry (configurable)
Dynamic Position Sizing: Based on ATR stop distance and max risk percentage
Advanced Signal Filters:
RSI Filter:
Long trades: RSI < 70 and > 40 (avoiding overbought)
Short trades: RSI > 30 and < 60 (avoiding oversold)
Volume Filter:
Requires volume > 1.2x the 20-period moving average
Ensures institutional participation
MACD Filter (Optional):
Long: MACD line above signal line and rising
Short: MACD line below signal line and falling
EMA Trend Filter:
50-period EMA for trend confirmation
Long trades require price above rising EMA
Short trades require price below falling EMA
Higher Timeframe Filter:
Uses 4H/Daily EMA for multi-timeframe confluence
Enhanced Entry Logic:
Regular Entries: IDM + BOS + ALL filters must pass
Sweep Entries: Failed breakouts with tighter stops (1.6 ATR)
High-Probability Focus: Only trades when multiple confirmations align
Visual Improvements:
Detailed Entry Labels: Show entry, stop, target, and risk percentage
SL/TP Lines: Visual representation of risk/reward
Filter Status: Bar coloring shows when all filters align
Comprehensive Statistics: Real-time performance metrics
Key Strategy Parameters:
pinescript// Recommended Settings for Different Markets:
// Forex (4H-Daily):
// - CHoCH Period: 50-75
// - ATR SL: 2.0, ATR TP: 3.0
// - All filters enabled
// Crypto (1H-4H):
// - CHoCH Period: 30-50
// - ATR SL: 2.5, ATR TP: 4.0
// - Volume filter especially important
// Indices (4H-Daily):
// - CHoCH Period: 50-100
// - ATR SL: 1.8, ATR TP: 2.7
// - EMA and MACD filters crucial
Expected Performance Improvements:
Win Rate: 55-70% (improved filtering)
Profit Factor: 2.0-3.5+ (better risk/reward with ATR)
Reduced Drawdown: Stricter filters reduce false signals
Consistent Risk: ATR-based stops adapt to volatility
This enhanced version provides much more robust signal filtering while maintaining the core market structure edge, resulting in higher-probability trades with consistent risk management.

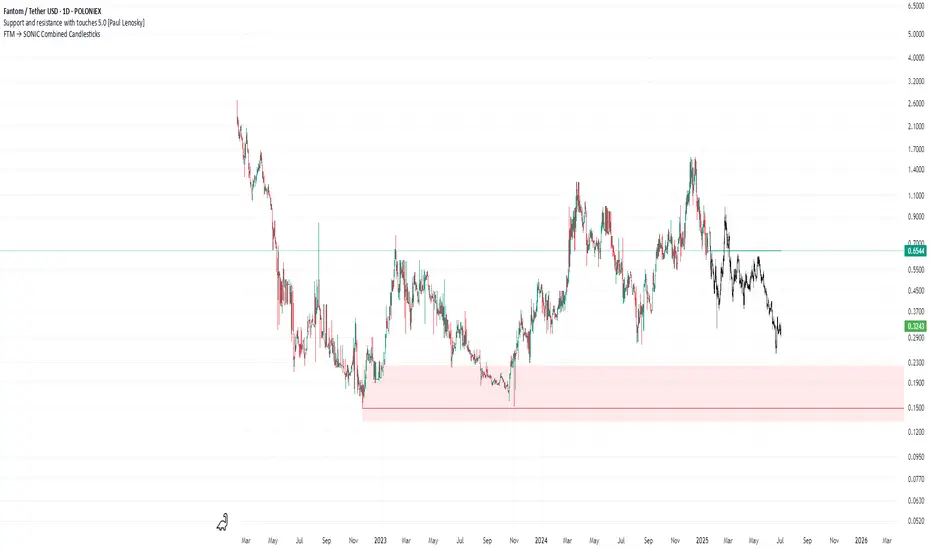
FTM → SONIC Combined Candlesticksthis script combines the chart of FTM and SONIC to get a better overview of the entire price action
Markov Chain Trend ProbabilityA Markov Chain is a mathematical model that predicts future states based on the current state, assuming that the future depends only on the present (not the past). Originally developed by Russian mathematician Andrey Markov, this concept is widely used in:
Finance: Risk modeling, portfolio optimization, credit scoring, algorithmic trading
Weather Forecasting: Predicting sunny/rainy days, temperature patterns, storm tracking
Here's an example of a Markov chain: If the weather is sunny, the probability that will be sunny 30 min later is say 90%. However, if the state changes, i.e. it starts raining, how the probability that will be raining 30 min later is say 70% and only 30% sunny.
Similar concept can be applied to markets price action and trends.
Mathematical Foundation
The core principle follows the Markov Property: P(X_{t+1}|X_t, X_{t-1}, ..., X_0) = P(X_{t+1}|X_t)
Transition Matrix :
-------------Next State
Current----
--------P11 P12
-----P21 P22
Probability Calculations:
P(Up→Up) = Count(Up→Up) / Count(Up states)
P(Down→Down) = Count(Down→Down) / Count(Down states)
Steady-state probability: π = πP (where π is the stationary distribution)
State Definition:
State = UPTREND if (Price_t - Price_{t-n})/ATR > threshold
State = DOWNTREND if (Price_t - Price_{t-n})/ATR < -threshold
How It Works in Trading
This indicator applies Markov Chain theory to market trends by:
Defining States: Classifies market conditions as UPTREND or DOWNTREND based on price movement relative to ATR (Average True Range)
Learning Transitions: Analyzes historical data to calculate probabilities of moving from one state to another
Predicting Probabilities: Estimates the likelihood of future trend continuation or reversal
How to Use
Parameters:
Lookback Period: Number of bars to analyze for trend detection (default: 14)
ATR Threshold: Sensitivity multiplier for state changes (default: 0.5)
Historical Periods: Sample size for probability calculations (default: 33)
Trading Applications:
Trend confirmation for entry/exit decisions
Risk assessment through probability analysis
Market regime identification
Early warning system for potential trend reversals
The indicator works on any timeframe and asset class. Enjoy!

Clarix 5m Scalping Breakout StrategyPurpose
A 5-minute scalping breakout strategy designed to capture fast 3-5 pip moves, using premium/discount zone filters and market bias conditions.
How It Works
The script monitors price action in 5-minute intervals, forming a 15-minute high and low range by tracking the highs and lows of the first 3 consecutive 5-minute candles starting from a custom time. In the next 3 candles, it waits for a breakout above the 15m high or below the 15m low while confirming market bias using custom equilibrium zones.
Buy signals trigger when price breaks the 15m high while in a discount zone
Sell signals trigger when price breaks the 15m low while in a premium zone
The strategy simulates trades with fixed 3-5 pip take profit and stop loss values (configurable). All trades are recorded in a backtest table with live trade results and an automatically updated win rate.
Features
Designed exclusively for the 5-minute timeframe
Custom 15-minute high/low breakout logic
Premium, Discount, and Equilibrium zone display
Built-in backtest tracker with live trade results, statistics, and win rate
Customizable start time, take profit, and stop loss settings
Real-time alerts on breakout signals
Visual markers for trade entries and failed trades
Consistent win rate exceeding 90–95% on average when following market conditions
Usage Tips
Use strictly on 5-minute charts for accurate signal performance. Avoid during high-impact news releases.
Important: Once a trade is opened, manually set your take profit at +3 to +5 pips immediately to secure the move, as these quick scalps often hit the target within a single candle. This prevents missed exits during rapid price action.
30s OR ProjectionsThis script gets the opening range for NQ,ES, and YM. It then created deviations based on this range as targets to take profit from. You may also use the deviations to enter into trades looking for the other side of the range. You have the ability to shade areas of the range.

Date Marker GPTDate Marker GPT
By Jimmy Dimos (corrected by ChatGPT-o3)
Description
This overlay indicator automatically plots vertical lines at each weekly option-expiration timestamp (Friday at 3 PM CST) for both historical and upcoming periods, helping you visualize key expiration dates alongside your price action and regression tools. Shown is my Date Maker GPT vertical blue Lines, Linear Regression Channel(not part of my script) and zigzag++ also not part of my script.
⸻
Key Features
• Past Expirations: Draws 12 past Friday markers at 3 PM CST
• Future Expirations: Projects 12 upcoming Friday markers at 3 PM CST
• Timezone Handling: Uses UTC internally (21:00 UTC = 3 PM CST)
• Customizable: num_fridays_past and num_fridays_future inputs let you adjust how many weeks to display
⸻
How It Works
1. Timestamp Calculation
• Uses Pine Script’s dayofweek() and timestamp() functions to find each Friday at the target hour.
• Two helper functions, get_previous_friday() and get_next_friday(), compute offsets in days/weeks based on the current bar’s date.
2. Drawing Lines
• Loops through the specified number of weeks in the past and future.
• Calls line.new() for each expiration timestamp, extending lines across the entire chart.
⸻
Usage Tips
• Overlay this script on any OHLC chart to see how price tends to cluster around option expirations.
• Combine with a linear regression or trend-channel indicator to anticipate likely trading ranges leading into expiration.
• Tweak the num_fridays_past and num_fridays_future parameters to focus on shorter or longer horizons.
⸻
Disclaimer: This tool is provided for educational and analytical purposes only. It is not financial advice. Always conduct your own research and risk management.
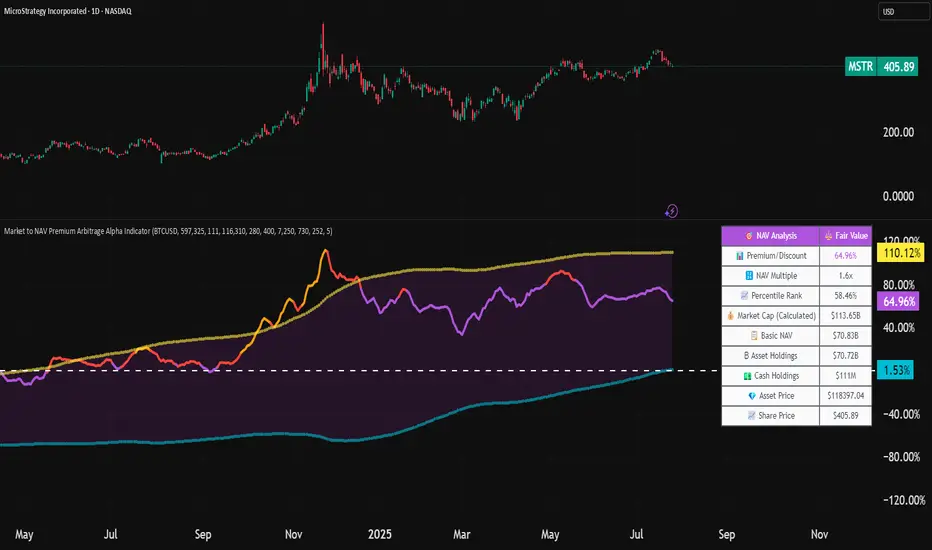
Market to NAV Premium Arbitrage Alpha IndicatorBitcoin treasury companies such as Microstrategy are known for trading at significant premiums. but how big exactly is the premium? And how can we measure it in real time?
I developed this quantitative tool to identify statistical mispricings between market capitalization and net asset value (NAV), specifically designed for arbitrage strategies and alpha generation in Bitcoin-holding companies, such as MicroStrategy or Sharplink Gaming, or SPACs used primarily to hold cryptocurrencies, Bitcoin ETFs, and other NAV-based instruments. It can probably also be used in certain spin-offs.
KEY FEATURES:
✅ Real-time Premium/Discount Calculation
• Automatically retrieves market cap data from TradingView
• Calculates precise NAV based on underlying asset holdings (for example Bitcoin)
• Formula: (Market Cap - NAV) / NAV × 100
✅ Statistical Analysis
• Historical percentile rankings (customizable lookback period)
• Standard deviation bands (2σ) for extreme value detection (close to these values might be seen as interesting points to short or go long)
• Smoothing period to reduce noise
✅ Multi-Source Market Cap Detection
• You can add the ticker of the NAV asset, but if necessary, you can also put it manually. Priority system: TradingView data → Calculated → Manual override
✅ Advanced NAV Modeling
• Basic NAV: Asset holdings + cash.
• Adjusted NAV: Includes software business value, debt, preferred shares. If the company has a lot of this kind of intrinsic value, put it in the "cash" field
• Support for any underlying asset (BTC, ETH, etc.)
TRADING APPLICATIONS:
🎯 Pairs Trading Signals
• Long/Short opportunities when premium reaches statistical extremes
• Mean reversion strategies based on historical ranges
• Risk-adjusted position sizing using percentile ranks
🎯 Arbitrage Detection
• Identifies when market pricing significantly deviates from fair value
• Quantifies the magnitude of mispricing for profit potential
• Historical context for timing entry/exit points
CONFIGURATION OPTIONS:
• Underlying Asset: Any symbol (default: COINBASE:BTCUSD) NEEDS MANUAL INPUT
• Asset Quantity: Precise holdings amount (for example, how much BTC does the company currently hold). NEEDS MANUAL INPUT
• Cash Holdings: Additional liquid assets. NEEDS MANUAL INPUT
• Market Cap Mode: Auto-detect, calculated, or manual
• Advanced Adjustments: Business value, debt, preferred shares
• Display Settings: Lookback period, smoothing, custom colors
IT CAN BE USED BY:
• Quantitative traders focused on statistical arbitrage
• Institutional investors monitoring NAV-based instruments
• Bitcoin ETF and MSTR traders seeking alpha generation
• Risk managers tracking premium/discount exposures
• Academic researchers studying market efficiency (as you can see, markets are not efficient 😉)
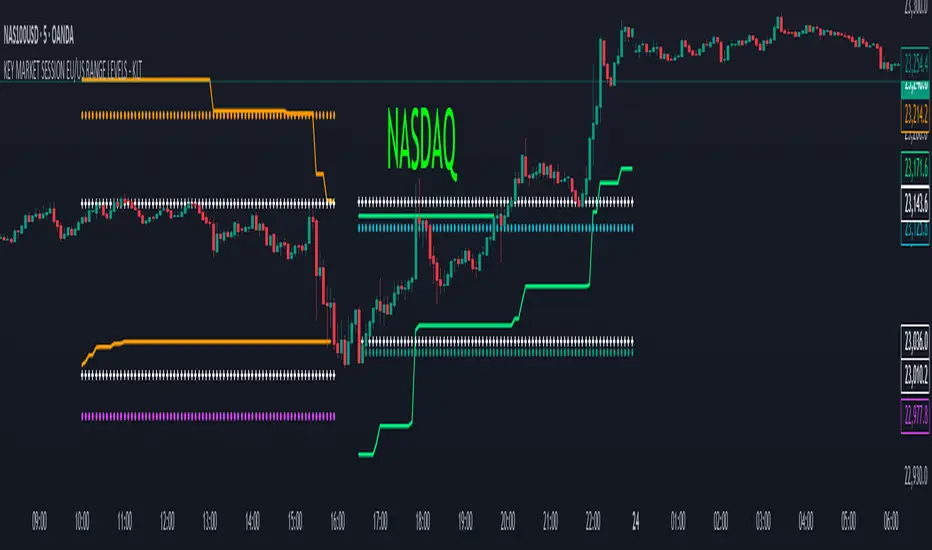
KEY MARKET SESSION EU/US RANGE LEVELS - KLT🔹 KEY MARKET SESSION EU/US RANGE LEVELS - KLT
This indicator highlights critical trading levels during the European and U.S. sessions, with Overbought (OB) and Oversold (OS) markers derived from each session's price range.
It’s designed to support traders in identifying key zones of interest and historical price reactions across sessions.
✳️ Features
🕒 Session Recognition
European Session (EU): 08:00 to 14:00 UTC
United States Session (US): 14:30 to 21:00 UTC
The indicator automatically detects the current session and updates levels in real time.
📈 Overbought / Oversold (OB/OS) Levels
Helps identify potential reversal or reaction zones.
🔁 Previous Session OB/OS Crosses
OB/OS levels from the previous session are plotted as white crosses during the opposite session:
EU OB/OS shown during the US session
US OB/OS shown during the EU session
These levels act as potential price targets or reaction areas based on prior session behavior.
🎨 Session-Based Color Coding
EU Session
High/Low: Orange / Fuchsia
OB/OS: Orange / Lime
Previous OB/OS: White crosses during the US session
US Session
High/Low: Aqua / Teal
OB/OS: Aqua / Lime
Previous OB/OS: White crosses during the EU session
🧠 How to Use
Use the OB/OS levels to gauge potential turning points or extended moves.
Watch for previous session crosses to spot historically relevant zones that may attract price.
Monitor extended High/Low lines as potential magnets for price continuation.
🛠 Additional Notes
No repainting; levels are session-locked and tracked in real time.
Optimized for intraday strategies, scalping, and session-based planning.
Works best on assets with clear session behavior (e.g., forex, indices, major commodities).
Average Daily Range in TicksPurpose: The ADR Ticks Indicator calculates and displays the average daily price range of a financial instrument, expressed in ticks, over a user-specified number of days. It provides traders with a measure of average daily volatility, which can be used for position sizing, setting stop-loss/take-profit levels, or assessing market activity.
Calculation: Computes the average daily range by taking the difference between the daily high and low prices, averaging this range over a customizable number of days, and converting the result into ticks (using the instrument's minimum tick size).
Customization: Includes a user input to adjust the number of days for the average calculation and a toggle to show/hide the ADR Ticks value in the table.
Risk Management: Helps traders estimate typical daily price movement to set appropriate stop-loss or take-profit levels.
Market Analysis: Offers insight into average daily volatility, useful for day traders or swing traders assessing whether a market is trending or ranging.
Technical Notes:
The indicator uses barstate.islast to update the table only on the last bar, reducing computational load and preventing overlap.
The script handles different chart timeframes by pulling daily data via request.security, making it robust across various instruments and timeframes.

Share Size FinderEnter your target gain and return timeframe to calculate how many shares to buy and the price you’ll need to sell at to meet that goal.
The return timeframe is based on how many candles (based on the ATR) it may take to reach your exit price. I use 2 for scalping.
The table shows the total cost of buying that share amount at the current price—useful for managing account risk, especially for cash accounts or those under PDT rules.
A chart of the exit price is also included to help you compare with projections like Fibonacci extensions.

🌊 Reinhart-Rogoff Financial Instability Index (RR-FII)Overview
The Reinhart-Rogoff Financial Instability Index (RR-FII) is a multi-factor indicator that consolidates historical crisis patterns into a single risk score ranging from 0 to 100. Drawing from the extensive research in "This Time is Different: Eight Centuries of Financial Crises" by Carmen M. Reinhart and Kenneth S. Rogoff, the RR-FII translates nearly a millennium of crisis data into practical insights for financial markets.
What It Does
The RR-FII acts like a real-time financial weather forecast by tracking four key stress indicators that historically signal the build-up to major financial crises. Unlike traditional indicators based only on price, it takes a broader view, examining the global market's interconnected conditions to provide a holistic assessment of systemic risk.
The Four Crisis Components
- Capital Flow Stress (Default weight: 25%)
- Data analyzed: Volatility (ATR) and price movements of the selected asset.
- Detects abrupt volatility surges or sharp price falls, which often precede debt defaults due to sudden stops in capital inflow.
- Commodity Cycle (Default weight: 20%)
- Data analyzed: US crude oil prices (customizable).
- Watches for significant declines from recent highs, since commodity price troughs often signal looming crises in emerging markets.
- Currency Crisis (Default weight: 30%)
- Data analyzed: US Dollar Index (DXY, customizable).
- Flags if the currency depreciates by more than 15% in a year, aligning with historical criteria for currency crashes linked to defaults.
- Banking Sector Health (Default weight: 25%)
- Data analyzed: Performance of financial sector ETFs (e.g., XLF) relative to broad market benchmarks (SPY).
- Monitors for underperformance in the financial sector, a strong indicator of broader financial instability.
Risk Scale Interpretation
- 0-20: Safe – Low systemic risk, normal conditions.
- 20-40: Moderate – Some signs of stress, increased caution advised.
- 40-60: Elevated – Multiple risk factors, consider adjusting positions.
- 60-80: High – Significant probability of crisis, implement strong risk controls.
- 80-100: Critical – Several crisis indicators active, exercise maximum caution.
Visual Features
- The main risk line changes color with increasing risk.
- Background colors show different risk zones for quick reference.
- Option to view individual component scores.
- A real-time status table summarizes all component readings.
- Crisis event markers appear when thresholds are breached.
- Customizable alerts notify users of changing risk levels.
How to Use
- Apply as an overlay for broad risk management at the portfolio level.
- Adjust position sizes inversely to the crisis index score.
- Use high index readings as a warning to increase vigilance or reduce exposure.
- Set up alerts for changes in risk levels.
- Analyze using various timeframes; daily and weekly charts yield the best macro insights.
Customizable Settings
- Change the weighting of each crisis factor.
- Switch commodity, currency, banking sector, and benchmark symbols for customized views or regional focus.
- Adjust thresholds and visual settings to match individual risk preferences.
Academic Foundation
Rooted in rigorous analysis of 66 countries and 800 years of data, the RR-FII uses empirically validated relationships and thresholds to assess systemic risk. The indicator embodies key findings: financial crises often follow established patterns, different types of crises frequently coincide, and clear quantitative signals often precede major events.
Best Practices
- Use RR-FII as part of a comprehensive risk management strategy, not as a standalone trading signal.
- Combine with fundamental analysis for complete market insight.
- Monitor for differences between component readings and the overall index.
- Favor higher timeframes for a broader macro view.
- Adjust component importance to suit specific market interests.
Important Disclaimers
- RR-FII assesses risk using patterns from past crises but does not predict future events.
- Historical performance is not a guarantee of future results.
- Always employ proper risk management.
- Consider this tool as one element in a broader analytical toolkit.
- Even with high risk readings, markets may not react immediately.
Technical Requirements
- Compatible with Pine Script v6, suitable for all timeframes and symbols.
- Pulls data automatically for USOIL, DXY, XLF, and SPY.
- Operates without repainting, using only confirmed data.
The RR-FII condenses centuries of financial crisis knowledge into a modern risk management tool, equipping investors and traders with a deeper understanding of when systemic risks are most pronounced.

% / ATR Buy, Target, Stop + Overlay & P/L% / ATR Buy, Target, Stop + Overlay & P/L
This tool combines volatility‑based and fixed‑percentage trade planning into a single, on‑chart overlay—with built‑in profit‑and‑loss estimates. Toggle between ATR or percentage modes, plot your Buy, Target and Stop levels, and see the dollar gain or loss for a specified position size—all in one interactive table and chart display.
NOTE: To activate plotted lines, price labels, P/L rows and table values, enter a Buy Price greater than zero.
What It Does
Mode Toggle: Choose between “ATR” (volatility‑based) or “%” (fixed‑percentage) calculations.
Buy Price Input: Manually enter your entry price.
ATR Mode:
Target = Buy + (ATR × Target Multiplier)
Stop = Buy − (ATR × Stop Multiplier)
Percentage Mode:
Target = Buy × (1 + Target % / 100)
Stop = Buy × (1 – Stop % / 100)
P/L Estimates: Specify a dollar amount to “invest” at your Buy price, and the script calculates:
Gain ($): Profit if Target is hit
Loss ($): Cost if Stop is hit
Visual Overlay: Draws horizontal lines for Buy, Target and Stop, with optional price labels on the chart scale.
Interactive Table: Displays Buy, Target, Stop, ATR/timeframe info (in ATR mode), percentages (in % mode), and P/L rows.
Customization Options
Line Settings:
Choose color, style (solid/dashed/dotted), and width for Buy, Target, Stop lines.
Extend lines rightward only or in both directions.
Table Settings:
Position the table (top/bottom × left/right).
Toggle individual rows: Buy Price; Target (multiplier or %); Stop (multiplier or %); Target ATR %; Stop ATR %; ATR Time Frame; ATR Value; Gain ($); Loss ($).
Customize text colors for each row and background transparency.
General Inputs:
ATR length and optional ATR timeframe override (e.g. use daily ATR on an intraday chart).
Target/Stop multipliers or percentages.
Dollar Amount for P/L calculations.
How to Use It for Trading
Plan Your Entry: Enter your intended Buy Price and position size (dollar amount).
Select Mode: Toggle between ATR or % mode depending on whether you prefer volatility‑based or fixed offsets.
Assess R:R and P/L: Instantly see your Target, Stop levels, and potential profit or loss in dollars.
Visual Reference: Lines and price labels update in real time as you tweak inputs—ideal for live trading, backtesting or trade journaling.
Ideal For
Traders who want both volatility‑based and percentage‑based exit options in one tool
Those who need on‑chart P/L estimates based on position size
Swing and intraday traders focused on objective, rule‑based trade management
Anyone who uses ATR for adaptive stops/targets or fixed percentages for simpler exits
Log Return DistributionThis indicator calculates the statistical distribution of logarithmic returns over a user-defined lookback period and visualizes it as a horizontal profile anchored to the most recent opening price.
Lookback Length: The number of recent bars to include in the distribution analysis. A larger value (e.g., 252) provides a long-term statistical view, while a smaller value (e.g., 20) focuses on recent, short-term volatility.
Bins Count: The number of price levels to divide the distribution into. An odd number is recommended (e.g., 31, 51) to ensure a dedicated central line for the 0% return.
Max Line Length: The horizontal length (in bars) of the line representing the most frequent return bin (the mode). This setting scales the entire profile, allowing you to make differences in frequency more or less pronounced visually.

LANZ Strategy 6.0 [Backtest]🔷 LANZ Strategy 6.0 — Precision Backtesting Based on 09:00 NY Candle, Dynamic SL/TP, and Lot Size per Trade
LANZ Strategy 6.0 is the simulation version of the original LANZ 6.0 indicator. It executes a single LIMIT BUY order per day based on the 09:00 a.m. New York candle, using dynamic Stop Loss and Take Profit levels derived from the candle range. Position sizing is calculated automatically using capital, risk percentage, and pip value — allowing accurate trade simulation and performance tracking.
📌 This is a strategy script — It simulates real trades using strategy.entry() and strategy.exit() with full money management for risk-based backtesting.
🧠 Core Logic & Trade Conditions
🔹 BUY Signal Trigger:
At 09:00 a.m. NY (New York time), if:
The current candle is bullish (close > open)
→ A BUY order is placed at the candle’s close price (EP)
Only one signal is evaluated per day.
⚙️ Stop Loss / Take Profit Logic
SL can be:
Wick low (0%)
Or dynamically calculated using a % of the full candle range
TP is calculated using the user-defined Risk/Reward ratio (e.g., 1:4)
The TP and SL levels are passed to strategy.exit() for each trade simulation.
💰 Risk Management & Lot Size Calculation
Before placing the trade:
The system calculates pip distance from EP to SL
Computes the lot size based on:
Account capital
Risk % per trade
Pip value (auto or manual)
This ensures every trade uses consistent, scalable risk regardless of instrument.
🕒 Manual Close at 3:00 p.m. NY
If the trade is still open by 15:00 NY time, it will be closed using strategy.close().
The final result is the actual % gain/loss based on how far price moved relative to SL.
📊 Backtest Accuracy
One trade per day
LIMIT order at the candle close
SL and TP pre-defined at execution
No repainting
Session-restricted (only runs on 1H timeframe)
✅ Ideal For:
Traders who want to backtest a clean and simple daily entry system
Strategy developers seeking reproducible, high-conviction trades
Users who prefer non-repainting, session-based simulations
👨💻 Credits:
💡 Developed by: LANZ
🧠 Logic & Money Management Engine: LANZ
📈 Designed for: 1H charts
🧪 Purpose: Accurate simulation of LANZ 6.0's NY Candle Entry system

TheDevashishratio-MomentumThis custom momentum indicator is inspired by Fibonacci principles but builds a unique sequence with steps of 0.5 (i.e., 0, 0.5, 1, 1.5, 2, ...). Instead of traditional Fibonacci numbers, each step functions as a dynamic lookback period for a momentum calculation. By cycling through these fractional steps, you capture a layered view of price momentum over varying intervals.
The "Fibonacci" Series Used
Sequence:
0, 0.5, 1, 1.5, 2, … up to a user-defined maximum
For trading indicators, lag values (lookback) must be integers, so each step is rounded to the nearest integer and duplicates are removed, resulting in lookbacks:
1, 2, 3, 4, ... N
Indicator Logic
For each selected lookback, the indicator calculates momentum as:
Momentum
n
=
close
−
close
Momentum
n
=close−close
Where:
close = current price
n = integer from your series of
You can combine these momenta for an averaged or weighted momentum profile, displaying the composite as an oscillator.
How To Use
Bullish: Oscillator above zero indicates positive composite momentum.
Bearish: Oscillator below zero indicates negative composite momentum.
Crosses: A cross from below to above zero may signal emerging bullish momentum, and vice versa.
Customization
Adjust max_step to control how many interval lags you want in your composite.
This oscillator averages across many short and mid-term momenta, reducing noise while still being sensitive to changes.
Summary
TheDevashishratio-Momentum offers a fresh momentum oscillator, blending a "Fibonacci-like" progression with technical analysis, and can be easily copy-pasted into TradingView to experiment and refine your edge.
For more on momentum indicator logic or how to use arrays and series in Pine Script, explore TradingView's official documentation and open-source scripts
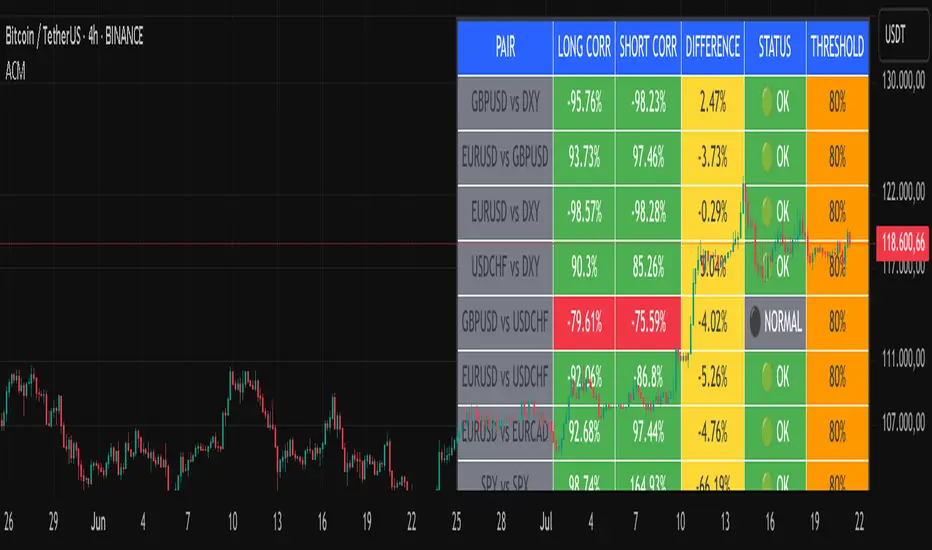
Advanced Correlation Monitor📊 Advanced Correlation Monitor - Pine Script v6
🎯 What does this indicator do?
Monitors real-time correlations between 13 different asset pairs and alerts you when historically strong correlations break, indicating potential trading opportunities or changes in market dynamics.
🚀 Key Features
✨ Multi-Market Monitoring
7 Forex Pairs (GBPUSD/DXY, EURUSD/GBPUSD, etc.)
6 Index/Stock Pairs (SPY/S&P500, DAX/NASDAQ, TSLA/NVDA, etc.)
Fully configurable - change any pair from inputs
📈 Dual Correlation Analysis
Long Period (90 bars): Identifies historically strong correlations
Short Period (6 bars): Detects recent breakdowns
Pearson Correlation using Pine Script v6 native functions
🎨 Intuitive Visualization
Real-time table with 6 information columns
Color coding: Green (correlated), Red (broken), Gray (normal)
Visual states: 🟢 OK, 🔴 BROKEN, ⚫ NORMAL
🚨 Smart Alert System
Only alerts previously correlated pairs (>80% historical)
Detects breakdowns when short correlation <80%
Consolidated alert with all affected pairs
🛠️ Flexible Configuration
Adjustable Parameters:
📅 Periods: Long (30-500), Short (2-50)
🎯 Threshold: 50%-99% (default 80%)
🎨 Table: Configurable position and size
📊 Symbols: All pairs are configurable
Default Pairs:
FOREX: INDICES/STOCKS:
- GBPUSD vs DXY • SPY vs S&P500
- EURUSD vs GBPUSD • DAX vs S&P500
- EURUSD vs DXY • DAX vs NASDAQ
- USDCHF vs DXY • TSLA vs NVDA
- GBPUSD vs USDCHF • MSFT vs NVDA
- EURUSD vs USDCHF • AAPL vs NVDA
- EURUSD vs EURCAD
💡 Practical Use Cases
🔄 Pairs Trading
Detects when strong correlations break for:
Statistical arbitrage
Mean reversion trading
Divergence opportunities
🛡️ Risk Management
Identifies when "safe" assets start moving independently:
Portfolio diversification
Smart hedging
Regime change detection
📊 Market Analysis
Understand underlying market structure:
Forex/DXY correlations
Tech sector rotation
Regional market disconnection
🎓 Results Interpretation
Reading Example:
EURUSD vs DXY: -98.57% → -98.27% | 🟢 OK
└─ Perfect negative correlation maintained (EUR rises when DXY falls)
TSLA vs NVDA: 78.12% → 0% | ⚫ NORMAL
└─ Lost tech correlation (divergence opportunity)
Trading Signals:
🟢 → 🔴: Broken correlation = Possible opportunity
Large difference: Indicates correlation tension
Multiple breaks: Market regime change
PnL_EMA_TRACK12_PRO_3.3_full_adjusted# Multi-Ticker Support
Manage up to 12 tickers simultaneously.
- For each symbol, input share quantities, entry prices, and two optional additional entry points (E2, E3) with their own shares and offset percentages.
- Dynamic handling of inputs using arrays for easier maintenance and scalability.
# Average Cost and PnL Calculation
- Computes weighted average entry costs across all position parts (E1 and optionally E2 and E3).
- Calculates real-time Profit & Loss (PnL) both in USD and percentage relative to the current price.
- Color-coded values: green for profit, red for loss — for quick visual feedback.
# Moving Averages as Benchmarks
- Uses daily EMAs (10, 21, 65) and 15-minute SMA 200 as reference levels.
- Calculates percentage deviations of these moving averages from the average entry price.
- Calculates dollar differences based on the total shares held.
# Chart Visualization
- Draws a dashed yellow line for the average cost of each position.
- Optionally draws two additional lines and labels for E2 (blue) and E3 (purple) if activated.
- Lines extend to the right to emphasize current relevance.
- Labels can be positioned left or right, with customizable horizontal offset.
# Interactive Table in Chart
- Positions the info table in any chosen corner or center of the chart (top/right/left/middle, etc.).
- Displays symbol, PnL (dollar and percentage), and deviations to key EMAs and SMA.
- Colors PnL values according to profit or loss for instant clarity.
# User-Friendly Settings
- Flexible font size options for both the table and labels.
- Customizable colors for positive and negative values (default green/red).
- Choice of label position and X-axis offset to fit your chart style.
