Market Cap Landscape 3DHello, traders and creators! 👋
Market Cap Landscape 3D. This project is more than just a typical technical analysis tool; it's an exploration into what's possible when code meets artistry on the financial charts. It's a demonstration of how we can transcend flat, two-dimensional lines and step into a vibrant, three-dimensional world of data.
This project continues a journey that began with a previous 3D experiment, the T-Virus Sentiment, which you can explore here:
The Market Cap Landscape 3D builds on that foundation, visualizing market data—particularly crypto market caps—as a dynamic 3D mountain range. The entire landscape is procedurally generated and rendered in real-time using the powerful drawing capabilities of polyline.new() and line.new() , pushed to their creative limits.
This work is intended as a guide and a design example for all developers, born from the spirit of learning and a deep love for understanding the Pine Script™ language.
---
🧐 Core Concept: How It Works
The indicator synthesizes multiple layers of information into a single, cohesive 3D scene:
The Surface: The mountain range itself is a procedurally generated 3D mesh. Its peaks and valleys create a rich, textured landscape that serves as the canvas for our data.
Crypto Data Integration: The core feature is its ability to fetch market cap data for a list of cryptocurrencies you provide. It then sorts them in descending order and strategically places them onto the 3D surface.
The Summit: The highest point on the mountain is reserved for the asset with the #1 market cap in your list, visually represented by a flag and a custom emblem.
The Mountain Labels: The other assets are distributed across the mountainside, with their rank determining their general elevation. This creates an intuitive visual hierarchy.
The Leaderboard Pole: For clarity, a dedicated pole in the back-right corner provides a clean, ranked list of the symbols and their market caps, ensuring the data is always easy to read.
---
🧐 Example of adjusting the view
To evoke the feeling of flying over mountains
To evoke the feeling of looking at a mountain peak on a low plain
🧐 Example of predefined colors
---
🚀 How to Use
Getting started with the Market Cap Landscape 3D:
Add to Chart: Apply the "Market Cap Landscape 3D" indicator to your active chart.
Open Settings: Double-click anywhere on the 3D landscape or click the "Settings" icon next to the indicator's name.
Customize Your Crypto List: The most important setting is in the Crypto Data tab. In the "Symbols" text area, enter a comma-separated list of the crypto tickers you want to visualize (e.g., BTC,ETH,SOL,XRP ). The indicator supports up to 40 unique symbols.
> Important Note: This indicator exclusively uses TradingView's `CRYPTOCAP` data source. To find valid symbols, use the main symbol search bar on your chart. Type `CRYPTOCAP:` (including the colon) and you will see a list of available options. For example, typing `CRYPTOCAP:BTC` will confirm that `BTC` is a valid ticker for the indicator's settings. Using symbols that do not exist in the `CRYPTOCAP` index will result in a script error. or, to display other symbols, simply type CRYPTOCAP: (including the colon) and you will see a list of available options.
Adjust Your View: Use the settings in the Camera & Projection tab to rotate ( Yaw ), tilt ( Pitch ), and scale the landscape until you find a view you love.
Explore & Customize: Play with the color palettes, flag design, and other settings to make the landscape truly your own!
---
⚙️ Settings & Customization
This indicator is highly customizable. Here’s a breakdown of what each setting does:
#### 🪙 Crypto Data
Symbols: Enter the crypto tickers you want to track, separated by commas. The script automatically handles duplicates and case-insensitivity.
Show Market Cap on Mountain: When checked, it displays the full market cap value next to the symbol on the mountain. When unchecked, it shows a cleaner look with just the symbol and a colored circle background.
#### 📷 Camera & Projection
Yaw (°): Rotates the camera view horizontally (side to side).
Pitch (°): Tilts the camera view vertically (up and down).
Scale X, Y, Z: Stretches or compresses the landscape in width, depth, and height, respectively. Fine-tune these to get the perfect perspective.
#### 🏞️ Grid / Surface
Grid X/Y resolution: Controls the detail level of the 3D mesh. Higher values create a smoother surface but may use more resources.
Fill surface strips: Toggles the beautiful color gradient on the surface.
Show wireframe lines: Toggles the visibility of the grid lines.
Show nodes (markers): Toggles the small dots at each grid intersection point.
#### 🏔️ Peaks / Mountains
Fill peaks volume: Draws vertical lines on high peaks, giving them a sense of volume.
Fill peaks surface: Draws a cross-hatch pattern on the surface of high peaks.
Peak height threshold: Defines the minimum height for a peak to receive the fill effect.
Peak fill color/density: Customizes the appearance of the fill lines.
#### 🚩 Flags (3D)
Show Flag on Summit: A master switch to show or hide the flag and emblem entirely.
Flag height, width, etc.: Provides full control over the dimensions and orientation of the flag on the highest peak.
#### 🎨 Color Palette
Base Gradient Palette: Choose from 13 stunning, pre-designed color themes for the landscape, from the classic SUNSET_WAVE to vibrant themes like NEON_DREAM and OCEANIC .
#### 🛡️ Emblem / Badge Controls
This section gives you granular control over every element of the custom emblem on the flag. Tweak rotation, offsets, and scale to design your unique logo.
---
👨💻 Developer's Corner: Modifying the Core Logic
If you're a developer and wish to customize the indicator's core data source, this section is for you. The script is designed to be modular, making it easy to change what data is being ranked and visualized.
The heart of the data retrieval and ranking logic is within the f_getSortedCryptoData() function. Here’s how you can modify it:
1. Changing the Data Source (from Market Cap to something else):
The current logic uses request.security("CRYPTOCAP:" + syms.get(i), ...) to fetch market capitalization data. To change this, you need to modify this line.
Example: Ranking by RSI (14) on the Daily timeframe.
First, you'll need a function to calculate RSI. Add this function to the script:
f_getRSI(symbol, timeframe, length) =>
request.security(symbol, timeframe, ta.rsi(close, length))
Then, inside f_getSortedCryptoData() , find the `for` loop that populates the `caps` array and replace the `request.security` call:
// OLD LINE:
// caps.set(i, request.security("CRYPTOCAP:" + syms.get(i), timeframe.period, close))
// NEW LINE for RSI:
// Note: You'll need to decide how to format the symbol name (e.g., "BINANCE:" + syms.get(i) + "USDT")
caps.set(i, f_getRSI("BINANCE:" + syms.get(i) + "USDT", "D", 14))
2. Changing the Data Formatting:
The ranking values are formatted for display using the f_fmtCap() function, which currently formats large numbers into "M" (millions), "B" (billions), etc.
If you change the data source to something like RSI, you'll want to change the formatting. You can modify f_fmtCap() or create a new formatting function.
Example: Formatting for RSI.
// Modify f_fmtCap or create f_fmtRSI
f_fmtRSI(float v) =>
str.tostring(v, "#.##") // Simply format to two decimal places
Remember to update the calls to this function in the main drawing loop where the labels are created (e.g., str.format("{0}: {1}", crypto.symbol, f_fmtCap(crypto.cap)) ).
By modifying these key functions ( f_getSortedCryptoData and f_fmtCap ), you can adapt the Market Cap Landscape 3D to visualize and rank almost any dataset you can imagine, from technical indicators to fundamental data.
---
We hope you enjoy using the Market Cap Landscape 3D as much as we enjoyed creating it. Happy charting! ✨
อินดิเคเตอร์และกลยุทธ์

ZigzagLiteLibrary "ZigzagLite"
Lighter version of the Zigzag Library. Without indicators and sub-component divisions
method getPrices(pivots)
Gets the array of prices from array of Pivots
Namespace types: Pivot
Parameters:
pivots (Pivot ) : array array of Pivot objects
Returns: array array of pivot prices
method getBars(pivots)
Gets the array of bars from array of Pivots
Namespace types: Pivot
Parameters:
pivots (Pivot ) : array array of Pivot objects
Returns: array array of pivot bar indices
method getPoints(pivots)
Gets the array of chart.point from array of Pivots
Namespace types: Pivot
Parameters:
pivots (Pivot ) : array array of Pivot objects
Returns: array array of pivot points
method getPoints(this)
Namespace types: Zigzag
Parameters:
this (Zigzag)
method calculate(this, ohlc, ltfHighTime, ltfLowTime)
Calculate zigzag based on input values and indicator values
Namespace types: Zigzag
Parameters:
this (Zigzag) : Zigzag object
ohlc (float ) : Array containing OHLC values. Can also have custom values for which zigzag to be calculated
ltfHighTime (int) : Used for multi timeframe zigzags when called within request.security. Default value is current timeframe open time.
ltfLowTime (int) : Used for multi timeframe zigzags when called within request.security. Default value is current timeframe open time.
Returns: current Zigzag object
method calculate(this)
Calculate zigzag based on properties embedded within Zigzag object
Namespace types: Zigzag
Parameters:
this (Zigzag) : Zigzag object
Returns: current Zigzag object
method nextlevel(this)
Namespace types: Zigzag
Parameters:
this (Zigzag)
method clear(this)
Clears zigzag drawings array
Namespace types: ZigzagDrawing
Parameters:
this (ZigzagDrawing ) : array
Returns: void
method clear(this)
Clears zigzag drawings array
Namespace types: ZigzagDrawingPL
Parameters:
this (ZigzagDrawingPL ) : array
Returns: void
method drawplain(this)
draws fresh zigzag based on properties embedded in ZigzagDrawing object without trying to calculate
Namespace types: ZigzagDrawing
Parameters:
this (ZigzagDrawing) : ZigzagDrawing object
Returns: ZigzagDrawing object
method drawplain(this)
draws fresh zigzag based on properties embedded in ZigzagDrawingPL object without trying to calculate
Namespace types: ZigzagDrawingPL
Parameters:
this (ZigzagDrawingPL) : ZigzagDrawingPL object
Returns: ZigzagDrawingPL object
method drawfresh(this, ohlc)
draws fresh zigzag based on properties embedded in ZigzagDrawing object
Namespace types: ZigzagDrawing
Parameters:
this (ZigzagDrawing) : ZigzagDrawing object
ohlc (float ) : values on which the zigzag needs to be calculated and drawn. If not set will use regular OHLC
Returns: ZigzagDrawing object
method drawcontinuous(this, ohlc)
draws zigzag based on the zigzagmatrix input
Namespace types: ZigzagDrawing
Parameters:
this (ZigzagDrawing) : ZigzagDrawing object
ohlc (float ) : values on which the zigzag needs to be calculated and drawn. If not set will use regular OHLC
Returns:
PivotCandle
PivotCandle represents data of the candle which forms either pivot High or pivot low or both
Fields:
_high (series float) : High price of candle forming the pivot
_low (series float) : Low price of candle forming the pivot
length (series int) : Pivot length
pHighBar (series int) : represents number of bar back the pivot High occurred.
pLowBar (series int) : represents number of bar back the pivot Low occurred.
pHigh (series float) : Pivot High Price
pLow (series float) : Pivot Low Price
Pivot
Pivot refers to zigzag pivot. Each pivot can contain various data
Fields:
point (chart.point) : pivot point coordinates
dir (series int) : direction of the pivot. Valid values are 1, -1, 2, -2
level (series int) : is used for multi level zigzags. For single level, it will always be 0
ratio (series float) : Price Ratio based on previous two pivots
sizeRatio (series float)
ZigzagFlags
Flags required for drawing zigzag. Only used internally in zigzag calculation. Should not set the values explicitly
Fields:
newPivot (series bool) : true if the calculation resulted in new pivot
doublePivot (series bool) : true if the calculation resulted in two pivots on same bar
updateLastPivot (series bool) : true if new pivot calculated replaces the old one.
Zigzag
Zigzag object which contains whole zigzag calculation parameters and pivots
Fields:
length (series int) : Zigzag length. Default value is 5
numberOfPivots (series int) : max number of pivots to hold in the calculation. Default value is 20
offset (series int) : Bar offset to be considered for calculation of zigzag. Default is 0 - which means calculation is done based on the latest bar.
level (series int) : Zigzag calculation level - used in multi level recursive zigzags
zigzagPivots (Pivot ) : array which holds the last n pivots calculated.
flags (ZigzagFlags) : ZigzagFlags object which is required for continuous drawing of zigzag lines.
ZigzagObject
Zigzag Drawing Object
Fields:
zigzagLine (series line) : Line joining two pivots
zigzagLabel (series label) : Label which can be used for drawing the values, ratios, directions etc.
ZigzagProperties
Object which holds properties of zigzag drawing. To be used along with ZigzagDrawing
Fields:
lineColor (series color) : Zigzag line color. Default is color.blue
lineWidth (series int) : Zigzag line width. Default is 1
lineStyle (series string) : Zigzag line style. Default is line.style_solid.
showLabel (series bool) : If set, the drawing will show labels on each pivot. Default is false
textColor (series color) : Text color of the labels. Only applicable if showLabel is set to true.
maxObjects (series int) : Max number of zigzag lines to display. Default is 300
xloc (series string) : Time/Bar reference to be used for zigzag drawing. Default is Time - xloc.bar_time.
curved (series bool) : Boolean field to print curved zigzag - used only with polyline implementation
ZigzagDrawing
Object which holds complete zigzag drawing objects and properties.
Fields:
zigzag (Zigzag) : Zigzag object which holds the calculations.
properties (ZigzagProperties) : ZigzagProperties object which is used for setting the display styles of zigzag
drawings (ZigzagObject ) : array which contains lines and labels of zigzag drawing.
ZigzagDrawingPL
Object which holds complete zigzag drawing objects and properties - polyline version
Fields:
zigzag (Zigzag) : Zigzag object which holds the calculations.
properties (ZigzagProperties) : ZigzagProperties object which is used for setting the display styles of zigzag
zigzagLabels (label )
zigzagLine (series polyline) : polyline object of zigzag lines

ZigzagLibrary "Zigzag"
Zigzag related user defined types. Depends on DrawingTypes library for basic types
method tostring(this, sortKeys, sortOrder, includeKeys)
Converts ZigzagTypes/Pivot object to string representation
Namespace types: Pivot
Parameters:
this (Pivot) : ZigzagTypes/Pivot
sortKeys (bool) : If set to true, string output is sorted by keys.
sortOrder (int) : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys (string ) : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of ZigzagTypes/Pivot
method tostring(this, sortKeys, sortOrder, includeKeys)
Converts Array of Pivot objects to string representation
Namespace types: Pivot
Parameters:
this (Pivot ) : Pivot object array
sortKeys (bool) : If set to true, string output is sorted by keys.
sortOrder (int) : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys (string ) : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of Pivot object array
method tostring(this)
Converts ZigzagFlags object to string representation
Namespace types: ZigzagFlags
Parameters:
this (ZigzagFlags) : ZigzagFlags object
Returns: string representation of ZigzagFlags
method tostring(this, sortKeys, sortOrder, includeKeys)
Converts ZigzagTypes/Zigzag object to string representation
Namespace types: Zigzag
Parameters:
this (Zigzag) : ZigzagTypes/Zigzagobject
sortKeys (bool) : If set to true, string output is sorted by keys.
sortOrder (int) : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys (string ) : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of ZigzagTypes/Zigzag
method calculate(this, ohlc, indicators, indicatorNames)
Calculate zigzag based on input values and indicator values
Namespace types: Zigzag
Parameters:
this (Zigzag) : Zigzag object
ohlc (float ) : Array containing OHLC values. Can also have custom values for which zigzag to be calculated
indicators (matrix) : Array of indicator values
indicatorNames (string ) : Array of indicator names for which values are present. Size of indicators array should be equal to that of indicatorNames
Returns: current Zigzag object
method calculate(this)
Calculate zigzag based on properties embedded within Zigzag object
Namespace types: Zigzag
Parameters:
this (Zigzag) : Zigzag object
Returns: current Zigzag object
method nextlevel(this)
Calculate Next Level Zigzag based on the current calculated zigzag object
Namespace types: Zigzag
Parameters:
this (Zigzag) : Zigzag object
Returns: Next Level Zigzag object
method clear(this)
Clears zigzag drawings array
Namespace types: ZigzagDrawing
Parameters:
this (ZigzagDrawing ) : array
Returns: void
method drawplain(this)
draws fresh zigzag based on properties embedded in ZigzagDrawing object without trying to calculate
Namespace types: ZigzagDrawing
Parameters:
this (ZigzagDrawing) : ZigzagDrawing object
Returns: ZigzagDrawing object
method drawfresh(this, ohlc, indicators, indicatorNames)
draws fresh zigzag based on properties embedded in ZigzagDrawing object
Namespace types: ZigzagDrawing
Parameters:
this (ZigzagDrawing) : ZigzagDrawing object
ohlc (float ) : values on which the zigzag needs to be calculated and drawn. If not set will use regular OHLC
indicators (matrix) : Array of indicator values
indicatorNames (string ) : Array of indicator names for which values are present. Size of indicators array should be equal to that of indicatorNames
Returns: ZigzagDrawing object
method drawcontinuous(this, ohlc, indicators, indicatorNames)
draws zigzag based on the zigzagmatrix input
Namespace types: ZigzagDrawing
Parameters:
this (ZigzagDrawing) : ZigzagDrawing object
ohlc (float ) : values on which the zigzag needs to be calculated and drawn. If not set will use regular OHLC
indicators (matrix) : Array of indicator values
indicatorNames (string ) : Array of indicator names for which values are present. Size of indicators array should be equal to that of indicatorNames
Returns:
method getPrices(pivots)
Namespace types: Pivot
Parameters:
pivots (Pivot )
method getBars(pivots)
Namespace types: Pivot
Parameters:
pivots (Pivot )
Indicator
Indicator is collection of indicator values applied on high, low and close
Fields:
indicatorHigh (series float) : Indicator Value applied on High
indicatorLow (series float) : Indicator Value applied on Low
PivotCandle
PivotCandle represents data of the candle which forms either pivot High or pivot low or both
Fields:
_high (series float) : High price of candle forming the pivot
_low (series float) : Low price of candle forming the pivot
length (series int) : Pivot length
pHighBar (series int) : represents number of bar back the pivot High occurred.
pLowBar (series int) : represents number of bar back the pivot Low occurred.
pHigh (series float) : Pivot High Price
pLow (series float) : Pivot Low Price
indicators (Indicator ) : Array of Indicators - allows to add multiple
Pivot
Pivot refers to zigzag pivot. Each pivot can contain various data
Fields:
point (chart.point) : pivot point coordinates
dir (series int) : direction of the pivot. Valid values are 1, -1, 2, -2
level (series int) : is used for multi level zigzags. For single level, it will always be 0
componentIndex (series int) : is the lower level zigzag array index for given pivot. Used only in multi level Zigzag Pivots
subComponents (series int) : is the number of sub waves per each zigzag wave. Only applicable for multi level zigzags
microComponents (series int) : is the number of base zigzag components in a zigzag wave
ratio (series float) : Price Ratio based on previous two pivots
sizeRatio (series float)
subPivots (Pivot )
indicatorNames (string ) : Names of the indicators applied on zigzag
indicatorValues (float ) : Values of the indicators applied on zigzag
indicatorRatios (float ) : Ratios of the indicators applied on zigzag based on previous 2 pivots
ZigzagFlags
Flags required for drawing zigzag. Only used internally in zigzag calculation. Should not set the values explicitly
Fields:
newPivot (series bool) : true if the calculation resulted in new pivot
doublePivot (series bool) : true if the calculation resulted in two pivots on same bar
updateLastPivot (series bool) : true if new pivot calculated replaces the old one.
Zigzag
Zigzag object which contains whole zigzag calculation parameters and pivots
Fields:
length (series int) : Zigzag length. Default value is 5
numberOfPivots (series int) : max number of pivots to hold in the calculation. Default value is 20
offset (series int) : Bar offset to be considered for calculation of zigzag. Default is 0 - which means calculation is done based on the latest bar.
level (series int) : Zigzag calculation level - used in multi level recursive zigzags
zigzagPivots (Pivot ) : array which holds the last n pivots calculated.
flags (ZigzagFlags) : ZigzagFlags object which is required for continuous drawing of zigzag lines.
ZigzagObject
Zigzag Drawing Object
Fields:
zigzagLine (series line) : Line joining two pivots
zigzagLabel (series label) : Label which can be used for drawing the values, ratios, directions etc.
ZigzagProperties
Object which holds properties of zigzag drawing. To be used along with ZigzagDrawing
Fields:
lineColor (series color) : Zigzag line color. Default is color.blue
lineWidth (series int) : Zigzag line width. Default is 1
lineStyle (series string) : Zigzag line style. Default is line.style_solid.
showLabel (series bool) : If set, the drawing will show labels on each pivot. Default is false
textColor (series color) : Text color of the labels. Only applicable if showLabel is set to true.
maxObjects (series int) : Max number of zigzag lines to display. Default is 300
xloc (series string) : Time/Bar reference to be used for zigzag drawing. Default is Time - xloc.bar_time.
ZigzagDrawing
Object which holds complete zigzag drawing objects and properties.
Fields:
zigzag (Zigzag) : Zigzag object which holds the calculations.
properties (ZigzagProperties) : ZigzagProperties object which is used for setting the display styles of zigzag
drawings (ZigzagObject ) : array which contains lines and labels of zigzag drawing.

Angled Volume Profile [Trendoscope]Volume profile is useful tool to understand the demand and supply zones on horizontal level. But, what if you want to measure the volume levels over trend line? In trending markets, the feature to measure volume over angled levels can be very useful for traders who use these measures. Here is an attempt to provide such tool.
🎲 How to use
🎯 Interactive input for selecting starting point and angle.
Upon loading the script, you will be prompted to select
Start time and price - this is a point which you can select by moving the maroon highlighted label.
End price - though this is shown as maroon bullet, this is price only input. Hence, when you click on the bullet, a horizontal line will appear. Users can move the line to use different End price.
Start and End price are used for identifying the angle at which volume profile need to be calculated. Whereas start time is used as starting time of the volume profile. Last bar of the chart is considered as ending bar.
🎯 Other settings.
From settings, users can select the colour of volume profile and style. Step multiplier defines the distance at which the profile lines needs to be drawn. Higher multiplier leads to less dense profile lines whereas lower multiplier leads to higher density of profile lines.
🎲 Limitations
🎯 Max 500 lines
Pinescript only allows max 500 lines on an indicator. Due to this, if we set very low multiplier - this can lead to more than 500 profile lines. Due to this some lines can get removed.
On the contrary, if multiplier is too high, then you will see very few lines which may not be meaningful.
Hence, it is important to select optimal multiplier based on your timeframe
🎯 No updates on new bar
Since the profile can spawn many bars, it is not possible to recalculate the whole volume profile when price creates new bars. Hence, there will not be visual update when new bars are created. But, to update the chart, users only need to make another movement of Start or ending point on interactive input.

MathEasingFunctionsLibrary "MathEasingFunctions"
A collection of Easing functions.
Easing functions are commonly used for smoothing actions over time, They are used to smooth out the sharp edges
of a function and make it more pleasing to the eye, like for example the motion of a object through time.
Easing functions can be used in a variety of applications, including animation, video games, and scientific
simulations. They are a powerful tool for creating realistic visual effects and can help to make your work more
engaging and enjoyable to the eye.
---
Includes functions for ease in, ease out, and, ease in and out, for the following constructs:
sine, quadratic, cubic, quartic, quintic, exponential, elastic, circle, back, bounce.
---
Reference:
easings.net
learn.microsoft.com
ease_in_sine_unbound(v)
Sinusoidal function, the position over elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_sine(v)
Sinusoidal function, the position over elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_sine_unbound(v)
Sinusoidal function, the position over elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_sine(v)
Sinusoidal function, the position over elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_sine_unbound(v)
Sinusoidal function, the position over elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_sine(v)
Sinusoidal function, the position over elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_quad_unbound(v)
Quadratic function, the position equals the square of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_quad(v)
Quadratic function, the position equals the square of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_quad_unbound(v)
Quadratic function, the position equals the square of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_quad(v)
Quadratic function, the position equals the square of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_quad_unbound(v)
Quadratic function, the position equals the square of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_quad(v)
Quadratic function, the position equals the square of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_cubic_unbound(v)
Cubic function, the position equals the cube of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_cubic(v)
Cubic function, the position equals the cube of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_cubic_unbound(v)
Cubic function, the position equals the cube of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_cubic(v)
Cubic function, the position equals the cube of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_cubic_unbound(v)
Cubic function, the position equals the cube of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_cubic(v)
Cubic function, the position equals the cube of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_quart_unbound(v)
Quartic function, the position equals the formula `f(t)=t^4` of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_quart(v)
Quartic function, the position equals the formula `f(t)=t^4` of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_quart_unbound(v)
Quartic function, the position equals the formula `f(t)=t^4` of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_quart(v)
Quartic function, the position equals the formula `f(t)=t^4` of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_quart_unbound(v)
Quartic function, the position equals the formula `f(t)=t^4` of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_quart(v)
Quartic function, the position equals the formula `f(t)=t^4` of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_quint_unbound(v)
Quintic function, the position equals the formula `f(t)=t^5` of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_quint(v)
Quintic function, the position equals the formula `f(t)=t^5` of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_quint_unbound(v)
Quintic function, the position equals the formula `f(t)=t^5` of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_quint(v)
Quintic function, the position equals the formula `f(t)=t^5` of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_quint_unbound(v)
Quintic function, the position equals the formula `f(t)=t^5` of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_quint(v)
Quintic function, the position equals the formula `f(t)=t^5` of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_expo_unbound(v)
Exponential function, the position equals the exponential formula of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_expo(v)
Exponential function, the position equals the exponential formula of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_expo_unbound(v)
Exponential function, the position equals the exponential formula of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_expo(v)
Exponential function, the position equals the exponential formula of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_expo_unbound(v)
Exponential function, the position equals the exponential formula of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_expo(v)
Exponential function, the position equals the exponential formula of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_circ_unbound(v)
Circular function, the position equals the circular formula of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_circ(v)
Circular function, the position equals the circular formula of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_circ_unbound(v)
Circular function, the position equals the circular formula of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_circ(v)
Circular function, the position equals the circular formula of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_circ_unbound(v)
Circular function, the position equals the circular formula of elapsed time (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_circ(v)
Circular function, the position equals the circular formula of elapsed time (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_back_unbound(v)
Back function, the position retreats a bit before resuming (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_back(v)
Back function, the position retreats a bit before resuming (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_back_unbound(v)
Back function, the position retreats a bit before resuming (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_back(v)
Back function, the position retreats a bit before resuming (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_back_unbound(v)
Back function, the position retreats a bit before resuming (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_back(v)
Back function, the position retreats a bit before resuming (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_elastic_unbound(v)
Elastic function, the position oscilates back and forth like a spring (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_elastic(v)
Elastic function, the position oscilates back and forth like a spring (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_elastic_unbound(v)
Elastic function, the position oscilates back and forth like a spring (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_elastic(v)
Elastic function, the position oscilates back and forth like a spring (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_elastic_unbound(v)
Elastic function, the position oscilates back and forth like a spring (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_elastic(v)
Elastic function, the position oscilates back and forth like a spring (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_bounce_unbound(v)
Bounce function, the position bonces from the boundery (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_bounce(v)
Bounce function, the position bonces from the boundery (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_bounce_unbound(v)
Bounce function, the position bonces from the boundery (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_out_bounce(v)
Bounce function, the position bonces from the boundery (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_bounce_unbound(v)
Bounce function, the position bonces from the boundery (unbound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
ease_in_out_bounce(v)
Bounce function, the position bonces from the boundery (bound).
Parameters:
v (float) : `float` Elapsed time.
Returns: Ratio of change.
select(v, formula, effect, bounded)
Parameters:
v (float)
formula (string)
effect (string)
bounded (bool)

Treasury Yields Heatmap [By MUQWISHI]▋ INTRODUCTION :
The “Treasury Yields Heatmap” generates a dynamic heat map table, showing treasury yield bond values corresponding with dates. In the last column, it presents the status of the yield curve, discerning whether it’s in a normal, flat, or inverted configuration, which determined by using Pearson's linear regression coefficient. This tool is built to offer traders essential insights for effectively tracking bond values and monitoring yield curve status, featuring the flexibility to input a starting period, timeframe, and select from a range of major countries' bond data.
_______________________
▋ OVERVIEW:
______________________
▋ YIELD CURVE:
It is determined through Pearson's linear regression coefficient and considered…
R ≥ 0.7 → Normal
0.7 > R ≥ 0.35 → Slight Normal
0.35 > R > -0.35 → Flat
-0.35 ≥ R > -0.7 → Slight Inverted
-0.7 ≥ R → Inverted
_______________________
▋ INDICATOR SETTINGS:
#Section One: Table Setting
#Section Two: Technical Setting
(1) Country: Select country’s treasury yields data
(2) Timeframe: Time interval.
(3) Fetch By:
(3A) Date: Retrieve data by beginning of date.
(3B) Period: Retrieve data by specifying the number of time series back.
Enjoy. Please let me know if you have any questions.
Thank you.

Time & Sales (Tape) [By MUQWISHI]▋ INTRODUCTION :
The “Time and Sales” (Tape) indicator generates trade data, including time, direction, price, and volume for each executed trade on an exchange. This information is typically delivered in real-time on a tick-by-tick basis or lower timeframe, providing insights into the traded size for a specific security.
_______________________
▋ OVERVIEW:
_______________________
▋ Volume Dynamic Scale Bar:
It's a way for determining dominance on the time and sales table, depending on the selected length (number of rows), indicating whether buyers or sellers are in control in selected length.
_______________________
▋ INDICATOR SETTINGS:
#Section One: Table Settings
#Section Two: Technical Settings
(1) Implement By: Retrieve data by
(1A) Lower Timeframe: Fetch data from the selected lower timeframe.
(1B) Live Tick: Fetch data in real-time on a tick-by-tick basis, capturing data as soon as it's observed by the system.
(2) Length (Number of Rows): User able to select number of rows.
(3) Size Type: Volume OR Price Volume.
_____________________
▋ COMMENT:
The values in a table should not be taken as a major concept to build a trading decision.
Please let me know if you have any questions.
Thank you.

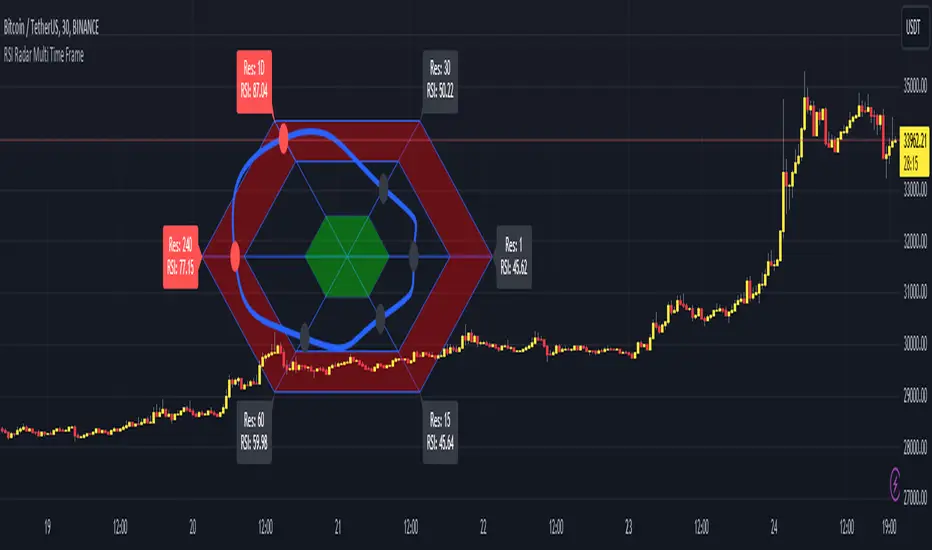
RSI Radar Multi Time FrameHello All!
First of all many Thanks to Tradingview and Pine Team for developing Pine Language all the time! Now we have a new feature and it's called Polylines and I developed RSI Radar Multi Time Frame . This script is an example and experimental work, you can use it as you wish.
The scripts gets RSI values from 6 different time frames, it doesn't matter the time frame you choose is higher/lower or chart time frame. it means that the script can get RSI values from higher or lower time frames than chart time frame.
It's designed to show RSI Radar all the time on the chart even if you zoom in/out or scroll left/right.
You can set OB/OS or RSI line colors. Also RSI polyline is shown as Curved/Hexagon optionally.
Some screenshots here:
Doesn't matter if you zoom out, it can show RSI radar in the visible area:
Another example:
You can change the colors, or see the RSI as Hexagon:
Time frames from seconds to 1Day in this example while chart time frame is any ( 30mins here )
Enjoy!
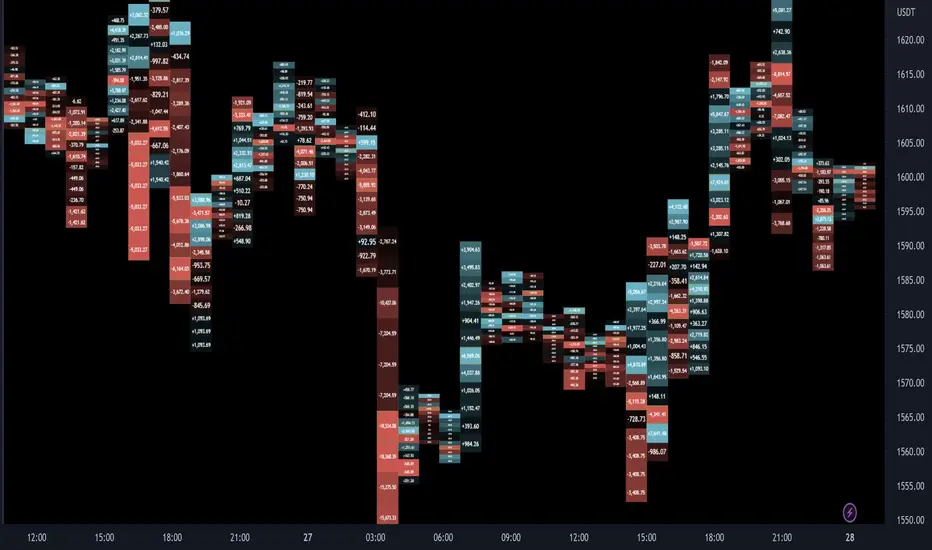
Delta Ladder [Kioseff Trading]Hello!
This script presents volume delta data in various forms!
Features
Classic mode: Volume delta boxes oriented to the right of the bar (sell closer / buy further)
On Bar mode: Volume delta boxes oriented on the bar (sell left / buy right)
Pure Ladder mode: Pure volume delta ladder
PoC highlighting
Color-coordinated delta boxes. Marginal volume differences are substantially shaded while large volume differences are lightly shaded.
Volume delta boxes can be merged and delta values removed to generate a color-only canvas reflecting vol. delta differences in price blocks.
Price bars can be split up to 497 times - allowing for greater precision.
Total volume delta for the bar and timestamp included
The image above shows Classic mode - delta blocks are oriented left/right contingent on positive/negative values!
The image above shows the same price sequence; however, delta blocks are superimposed on the price bar. Left-side blocks reflect negative delta while right-side blocks reflect positive delta! To apply this display method - select "On Bar" for the "Data Display Method" setting!
The image above shows "Pure Ladder" mode. Delta blocks remain color-coordinated; however, all delta blocks retain the same x-axis as the price bar they were calculated for!
Additionally, you can select to remove the delta values and merge the delta boxes to generate a color-based canvas indicative of volume delta at traded price levels!
The image above shows the same price sequence; however, the "Volume Assumption" setting is activated.
When active, the indicator assumes a 60/ 40 split when a level is traded at and only one metric - "buy volume" or "sell volume" is recorded. This means there shouldn't be any levels recorded where "buy volume" is greater than 0 and "sell volume" equals 0 and vice versa. While this assumption was performed arbitrarily, it may help better replicate volume delta and OI delta calculations seen on other charting platforms.
This option is configurable; you can select to have the script not assume a 60/ 40 split and instead record volume "as is" at the corresponding price level!
I plan to roll out additional features for the indicator - particularly tick-based price blocks! Stay tuned (:
Thank you!
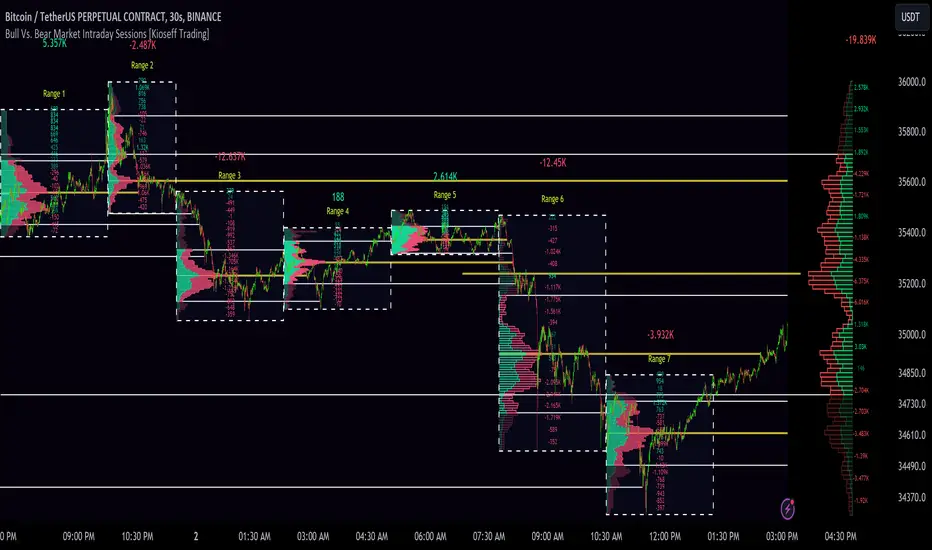
10x Bull Vs. Bear VP Intraday Sessions [Kioseff Trading]Hello!
This script "10x Bull Vs. Bear VP Intraday Sessions" lets the user configure up to 10 session ranges for Bull Vs. Bear volume profiles!
Features
Up To 10 Fixed Ranges!
Volume Profile Anchored to Fixed Range
Delta Ladder Anchored to Range
Bull vs Bear Profiles!
Standard Poc and Value Area Lines, in Addition to Separated POCs and Value Area Lines for Bull Profiles and Bear Profiles
Configurable Value Area Target
Up to 2000 Profile Rows per Visible Range
Stylistic Options for Profiles
This script generates Bull vs. Bear volume profiles for up to 10 fixed ranges!
Up to 2000 volume profile levels (price levels) Can be calculated for each profile, thanks to the new polyline feature, allowing for less aggregation / more precision of volume at price and volume delta.
Bull vs Bear Profiles
The image above shows primary functionality!
Green profiles = buying volume
Red profiles = selling volume
All colors are configurable.
Bullish & bearish POC + value areas for each fixed range are displayable!
That’s about it :D
This indicator is part of a series titled “Bull vs. Bear”.
If you have any suggestions please feel free to share!
T-Virus Sentiment [hapharmonic]🧬 T-Virus Sentiment: Visualize the Market's DNA
Remember the iconic T-Virus vial from the first Resident Evil? That powerful, swirling helix of potential has always fascinated me. It sparked an idea: what if we could visualize the market's underlying health in a similar way? What if we could capture the "genetic code" of market sentiment and contain it within a dynamic, 3D indicator? This project is the result of that idea, brought to life with Pine Script.
The indicator's main goal is to measure the strength and direction of market sentiment by analyzing the "genetic code" of price action through a variety of trusted indicators. The result is displayed as a liquid level within a DNA helix, a bubble density representing buying pressure, and a T-Virus mascot that reflects the overall mood.
🧐 Core Concept: How It Works
The primary output of the indicator is the "Active %" gauge you see on the right side of the vial. This percentage represents the overall sentiment score, calculated as an average from 7 different technical analysis tools. Each tool is analyzed on every bar and assigned a score from 1 (strong bearish pressure) to 5 (strong bullish potential).
In this indicator, we re-imagine market dynamics through the lens of a viral outbreak. A strong bear market is like a virus taking hold, pulling all technical signals down into a state of weakness. Conversely, a powerful bull market is like an antiviral serum ; positive signals rise and spread toward the top of the vial, indicating that the system is being injected with strength.
This is not just another line on a chart. It's a comprehensive sentiment dashboard designed to give an immediate, at-a-glance understanding of the confluence between 7 classic technical indicators. The incredible 3D model of the vial itself was inspired by a design concept found here .
⚛️ The 4 Core Elements of T-Virus Sentiment
These four elements work in harmony to give a complete, multi-faceted picture of market sentiment. Each component tells a different part of the story.
The Virus Mascot: An instant emotional cue. This character provides the quickest possible read on the overall market mood, combining sentiment with volume pressure.
The Antiviral Serum Level: The main quantitative output. This is the liquid level in the DNA helix and the percentage gauge on the right, representing the average sentiment score from all 7 indicators.
Buy Pressure & Bubble Density: This visualizes volume flow. The density of bubbles represents the intensity of accumulation (buying) versus distribution (selling). It's the "power" behind the move.
The Signal Distribution: This shows the confluence (or dispersion) of sentiment. Are all signals bullish and clustered at the top, or are they scattered, indicating a conflicted market? The position of the indicator labels is crucial, as each is assigned to one of five distinct zones:
Base Bottom: The market is at its weakest. Signals here suggest strong bearish control and distribution.
Lower Zone: The market is still bearish, but signals may be showing early signs of accumulation or bottoming.
Neutral Core (Center): A state of balance or sideways consolidation. The market is waiting for a new direction.
Upper Zone: Bullish momentum is becoming clear. Signals are strengthening and showing bullish control.
Top Cap: The market is "heating up" with strong bullish sentiment, potentially nearing overbought conditions.
🐂🐻 The Virus Mascot: The At-a-Glance Indicator
This character acts as a shortcut to confirm market health. It combines the sentiment score with volume, preventing false confidence in a low-volume rally.
Its state is determined by a dual-check: the overall "Antiviral Serum Level" and the "Buy Pressure" must both be above 50%.
Green & Smiling: The 'all clear' signal. This means that not only is the overall technical sentiment bullish, but it's also being supported by real buying pressure. This is a sign of a healthy bull market.
Red & Angry: A warning sign. This appears if either the sentiment is weak, or a bullish sentiment is not being confirmed by buying volume. The latter could indicate a potential "bull trap" or an exhaustive move.
This mascot can be disabled from the settings page under "Virus Mascot Styling" if a cleaner look is preferred.
🫧 Bubble Density: Gauging Buy vs. Sell Pressure
The bubbles visualize the battle between buyers and sellers. There are two modes to control how this is calculated:
Mode 1: Visible Range (The 'Big Picture' View)
This default mode is best for getting a broad, contextual understanding of the current session. It dynamically analyzes the volume of every single candlestick currently visible on the screen to calculate the buy/sell pressure ratio. It answers the question: "Over the entire period I'm looking at, who is in control?" As you zoom in or out, the calculation adapts.
Mode 2: Custom Lookback (The 'Precision' View)
This mode is for traders who need to analyze short-term pressure. You can define a fixed number of recent bars to analyze, which is perfect for scalping or understanding the volume dynamics leading into a key level. It answers the question: "What is happening right now ?" In the example above, a lookback of 2 focuses only on the most recent action, clearly showing intense, immediate selling pressure (few bubbles) and a corresponding drop in the sentiment score to 29%.
ℹ️ Interactive Tooltips: Dive Deeper
We believe in transparency, not 'black box' indicators. This feature transforms the indicator from a visual aid into an active learning tool.
Simply hover the mouse over any indicator label (like EMA, OBV, etc.) to get a detailed tooltip. It will explain the specific data points and thresholds that signal met to be placed in its current zone. This helps build trust in the signals and allows users to fine-tune the indicator settings to better match their own trading style.
🎯 The Scoring Logic Breakdown
The "Antiviral Serum Level" gauge is the average score from 7 technical analysis tools. Each is graded on a 5-point scale (1=Strong Bearish to 5=Strong Bullish). Here’s a detailed, transparent look at how each "gene" is evaluated:
Relative Strength Index (RSI)
Measures momentum and overbought/oversold conditions.
Group 1 (Strong Bearish): RSI > 80 (Extreme Overbought)
Group 2 (Bearish): 70 < RSI ≤ 80 (Overbought)
Group 3 (Neutral): 30 ≤ RSI ≤ 70
Group 4 (Bullish): 20 ≤ RSI < 30 (Oversold)
Group 5 (Strong Bullish): RSI < 20 (Extreme Oversold)
Exponential Moving Averages (EMA)
Evaluates the trend's strength and structure based on the alignment of multiple EMAs (9, 21, 50, 100, 200, 250).
Group 1 (Strong Bearish): A perfect bearish sequence (9 < 21 < 50 < ...)
Group 2 (Bearish Transition): Early signs of a potential reversal (e.g., 9 > 21 but still below 50)
Group 3 (Neutral / Mixed): MAs are intertwined or showing a partial bullish sequence.
Group 4 (Bullish): A strong bullish sequence is forming (e.g., 9 > 21 > 50 > 100)
Group 5 (Strong Bullish): A perfect bullish sequence (9 > 21 > 50 > 100 > 200 > 250)
Moving Average Convergence Divergence (MACD)
Analyzes the relationship between two moving averages to gauge momentum.
Group 1 (Strong Bearish): MACD & Histogram are negative and momentum is falling.
Group 2 (Weakening Bearish): MACD is negative but the histogram is rising or positive.
Group 3 (Neutral / Crossover): A crossover event is occurring near the zero line.
Group 4 (Bullish): MACD & Histogram are positive.
Group 5 (Strong Bullish): MACD & Histogram are positive, rising strongly, and accelerating.
Average Directional Index (ADX)
Measures trend strength, not direction. The score is based on both ADX value and the dominance of DI+ vs DI-.
Group 1 (Bearish / No Trend): ADX < 20 and DI- is dominant.
Group 2 (Developing Bearish Trend): 20 ≤ ADX < 25 and DI- is dominant.
Group 3 (Neutral / Indecision): Trend is weak or DI+ and DI- are nearly equal.
Group 4 (Developing Bullish Trend): 25 ≤ ADX ≤ 40 and DI+ is dominant.
Group 5 (Strong Bullish Trend): ADX > 40 and DI+ is dominant.
Ichimoku Cloud (IKH)
A comprehensive indicator that defines support/resistance, momentum, and trend direction.
Group 1 (Strong Bearish): Price is below the Kumo, Tenkan < Kijun, and Chikou is below price.
Group 2 (Bearish): Price is inside or below the Kumo, with mixed secondary signals.
Group 3 (Neutral / Ranging): Price is inside the Kumo, often with a Tenkan/Kijun cross.
Group 4 (Bullish): Price is above the Kumo with strong primary signals.
Group 5 (Strong Bullish): All signals are aligned bullishly: price above Kumo, bullish Tenkan/Kijun cross, bullish future Kumo, and Chikou above price.
Bollinger Bands (BB)
Measures volatility and relative price levels.
Group 1 (Strong Bearish): Price is below the lower band.
Group 2 (Bearish Territory): Price is between the lower band and the basis line.
Group 3 (Neutral): Price is hovering around the basis line.
Group 4 (Bullish Territory): Price is between the basis line and the upper band.
Group 5 (Strong Bullish): Price is above the upper band.
On-Balance Volume (OBV)
Uses volume flow to predict price changes. The score is based on OBV's trend and its position relative to its moving average.
Group 1 (Strong Bearish): OBV is below its MA and falling.
Group 2 (Weakening Bearish): OBV is below its MA but showing signs of rising.
Group 3 (Neutral): OBV is very close to its MA.
Group 4 (Bullish): OBV is above its MA and rising.
Group 5 (Strong Bullish): OBV is above its MA, rising strongly, and showing signs of a volume spike.
🧭 How to Use the T-Virus Sentiment Indicator
IMPORTANT: This indicator is a sentiment dashboard , not a direct buy/sell signal generator. Its strength lies in showing confluence and providing a quick, holistic view of the market's technical health.
Confirmation Tool: Use the "Active %" gauge to confirm a trade setup from your primary strategy. For example, if you see a bullish chart pattern, a high and rising sentiment score can add confidence to your trade.
Momentum & Trend Gauge: A consistently high score (e.g., > 75%) suggests strong, established bullish momentum. A consistently low score (< 25%) suggests strong bearish control. A score hovering around 50% often indicates a ranging or indecisive market.
Divergence & Warning System: Pay attention to divergences. If the price is making new highs but the sentiment score is failing to follow or is actively decreasing, it could be an early warning sign that the underlying momentum is weakening.
⚙️ Settings & Customization
The indicator is highly customizable to fit any trading style.
Position & Anchor: Control where the vial appears on the chart.
Styling (Vial, Helix, etc.): Nearly every visual element can be color-customized.
Signals: This is where the real power is. All underlying indicator parameters (RSI length, MACD settings, etc.) can be fine-tuned to match a personal strategy. The text labels can also be disabled if the chart feels cluttered.
Enjoy visualizing the market's DNA with the T-Virus Sentiment indicator

Intraday Spark Chart [AstrideUnicorn]The Intraday Spark Chart (ISC) is a minimalist yet powerful tool designed to track an asset’s performance relative to its daily opening price. Inspired by Nasdaq's trading-floor analog dashboards, it visualizes intraday percentage changes as a color-coded sparkline, helping traders quickly gauge momentum and session bias.
Ideal for: Day trading, scalping, and multi-asset monitoring.
Best paired with: 1m to 4H timeframes (auto-warns on higher TFs).
Key metrics:
Real-time % change from daily open.
Final daily % change (updated at session close).
Daily open price labels for orientation.
HOW TO USE
Visual Guide
Sparkline Plot:
A green area/line indicates price is above the daily open (bullish).
A red area/line signals price is below the daily open (bearish).
The baseline (0%) represents the daily open price.
Session Markers:
The dotted vertical lines separate trading days.
Gray labels near the baseline show the exact daily open price at the start of each session.
Dynamic Labels:
The labels in the upper left corner of each session range display the current (or final) daily % change. Color matches the trend (green/red) for instant readability.
Practical Use Cases
Opening Range Breakouts: Spot early momentum by observing how price reacts to the daily open.
Multi-Asset Screening: Compare intraday strength across symbols by choosing an asset in the indicator settings panel.
Session Close Prep: Anticipate daily settlement by tracking the final % change (useful for futures/swing traders).
SETTINGS
Asset (Input Symbol) : Defaults to the current chart symbol. Choose any asset to monitor its price action without switching charts - ideal for intermarket analysis or correlation tracking.

Markov Chain [3D] | FractalystWhat exactly is a Markov Chain?
This indicator uses a Markov Chain model to analyze, quantify, and visualize the transitions between market regimes (Bull, Bear, Neutral) on your chart. It dynamically detects these regimes in real-time, calculates transition probabilities, and displays them as animated 3D spheres and arrows, giving traders intuitive insight into current and future market conditions.
How does a Markov Chain work, and how should I read this spheres-and-arrows diagram?
Think of three weather modes: Sunny, Rainy, Cloudy.
Each sphere is one mode. The loop on a sphere means “stay the same next step” (e.g., Sunny again tomorrow).
The arrows leaving a sphere show where things usually go next if they change (e.g., Sunny moving to Cloudy).
Some paths matter more than others. A more prominent loop means the current mode tends to persist. A more prominent outgoing arrow means a change to that destination is the usual next step.
Direction isn’t symmetric: moving Sunny→Cloudy can behave differently than Cloudy→Sunny.
Now relabel the spheres to markets: Bull, Bear, Neutral.
Spheres: market regimes (uptrend, downtrend, range).
Self‑loop: tendency for the current regime to continue on the next bar.
Arrows: the most common next regime if a switch happens.
How to read: Start at the sphere that matches current bar state. If the loop stands out, expect continuation. If one outgoing path stands out, that switch is the typical next step. Opposite directions can differ (Bear→Neutral doesn’t have to match Neutral→Bear).
What states and transitions are shown?
The three market states visualized are:
Bullish (Bull): Upward or strong-market regime.
Bearish (Bear): Downward or weak-market regime.
Neutral: Sideways or range-bound regime.
Bidirectional animated arrows and probability labels show how likely the market is to move from one regime to another (e.g., Bull → Bear or Neutral → Bull).
How does the regime detection system work?
You can use either built-in price returns (based on adaptive Z-score normalization) or supply three custom indicators (such as volume, oscillators, etc.).
Values are statistically normalized (Z-scored) over a configurable lookback period.
The normalized outputs are classified into Bull, Bear, or Neutral zones.
If using three indicators, their regime signals are averaged and smoothed for robustness.
How are transition probabilities calculated?
On every confirmed bar, the algorithm tracks the sequence of detected market states, then builds a rolling window of transitions.
The code maintains a transition count matrix for all regime pairs (e.g., Bull → Bear).
Transition probabilities are extracted for each possible state change using Laplace smoothing for numerical stability, and frequently updated in real-time.
What is unique about the visualization?
3D animated spheres represent each regime and change visually when active.
Animated, bidirectional arrows reveal transition probabilities and allow you to see both dominant and less likely regime flows.
Particles (moving dots) animate along the arrows, enhancing the perception of regime flow direction and speed.
All elements dynamically update with each new price bar, providing a live market map in an intuitive, engaging format.
Can I use custom indicators for regime classification?
Yes! Enable the "Custom Indicators" switch and select any three chart series as inputs. These will be normalized and combined (each with equal weight), broadening the regime classification beyond just price-based movement.
What does the “Lookback Period” control?
Lookback Period (default: 100) sets how much historical data builds the probability matrix. Shorter periods adapt faster to regime changes but may be noisier. Longer periods are more stable but slower to adapt.
How is this different from a Hidden Markov Model (HMM)?
It sets the window for both regime detection and probability calculations. Lower values make the system more reactive, but potentially noisier. Higher values smooth estimates and make the system more robust.
How is this Markov Chain different from a Hidden Markov Model (HMM)?
Markov Chain (as here): All market regimes (Bull, Bear, Neutral) are directly observable on the chart. The transition matrix is built from actual detected regimes, keeping the model simple and interpretable.
Hidden Markov Model: The actual regimes are unobservable ("hidden") and must be inferred from market output or indicator "emissions" using statistical learning algorithms. HMMs are more complex, can capture more subtle structure, but are harder to visualize and require additional machine learning steps for training.
A standard Markov Chain models transitions between observable states using a simple transition matrix, while a Hidden Markov Model assumes the true states are hidden (latent) and must be inferred from observable “emissions” like price or volume data. In practical terms, a Markov Chain is transparent and easier to implement and interpret; an HMM is more expressive but requires statistical inference to estimate hidden states from data.
Markov Chain: states are observable; you directly count or estimate transition probabilities between visible states. This makes it simpler, faster, and easier to validate and tune.
HMM: states are hidden; you only observe emissions generated by those latent states. Learning involves machine learning/statistical algorithms (commonly Baum–Welch/EM for training and Viterbi for decoding) to infer both the transition dynamics and the most likely hidden state sequence from data.
How does the indicator avoid “repainting” or look-ahead bias?
All regime changes and matrix updates happen only on confirmed (closed) bars, so no future data is leaked, ensuring reliable real-time operation.
Are there practical tuning tips?
Tune the Lookback Period for your asset/timeframe: shorter for fast markets, longer for stability.
Use custom indicators if your asset has unique regime drivers.
Watch for rapid changes in transition probabilities as early warning of a possible regime shift.
Who is this indicator for?
Quants and quantitative researchers exploring probabilistic market modeling, especially those interested in regime-switching dynamics and Markov models.
Programmers and system developers who need a probabilistic regime filter for systematic and algorithmic backtesting:
The Markov Chain indicator is ideally suited for programmatic integration via its bias output (1 = Bull, 0 = Neutral, -1 = Bear).
Although the visualization is engaging, the core output is designed for automated, rules-based workflows—not for discretionary/manual trading decisions.
Developers can connect the indicator’s output directly to their Pine Script logic (using input.source()), allowing rapid and robust backtesting of regime-based strategies.
It acts as a plug-and-play regime filter: simply plug the bias output into your entry/exit logic, and you have a scientifically robust, probabilistically-derived signal for filtering, timing, position sizing, or risk regimes.
The MC's output is intentionally "trinary" (1/0/-1), focusing on clear regime states for unambiguous decision-making in code. If you require nuanced, multi-probability or soft-label state vectors, consider expanding the indicator or stacking it with a probability-weighted logic layer in your scripting.
Because it avoids subjectivity, this approach is optimal for systematic quants, algo developers building backtested, repeatable strategies based on probabilistic regime analysis.
What's the mathematical foundation behind this?
The mathematical foundation behind this Markov Chain indicator—and probabilistic regime detection in finance—draws from two principal models: the (standard) Markov Chain and the Hidden Markov Model (HMM).
How to use this indicator programmatically?
The Markov Chain indicator automatically exports a bias value (+1 for Bullish, -1 for Bearish, 0 for Neutral) as a plot visible in the Data Window. This allows you to integrate its regime signal into your own scripts and strategies for backtesting, automation, or live trading.
Step-by-Step Integration with Pine Script (input.source)
Add the Markov Chain indicator to your chart.
This must be done first, since your custom script will "pull" the bias signal from the indicator's plot.
In your strategy, create an input using input.source()
Example:
//@version=5
strategy("MC Bias Strategy Example")
mcBias = input.source(close, "MC Bias Source")
After saving, go to your script’s settings. For the “MC Bias Source” input, select the plot/output of the Markov Chain indicator (typically its bias plot).
Use the bias in your trading logic
Example (long only on Bull, flat otherwise):
if mcBias == 1
strategy.entry("Long", strategy.long)
else
strategy.close("Long")
For more advanced workflows, combine mcBias with additional filters or trailing stops.
How does this work behind-the-scenes?
TradingView’s input.source() lets you use any plot from another indicator as a real-time, “live” data feed in your own script (source).
The selected bias signal is available to your Pine code as a variable, enabling logical decisions based on regime (trend-following, mean-reversion, etc.).
This enables powerful strategy modularity : decouple regime detection from entry/exit logic, allowing fast experimentation without rewriting core signal code.
Integrating 45+ Indicators with Your Markov Chain — How & Why
The Enhanced Custom Indicators Export script exports a massive suite of over 45 technical indicators—ranging from classic momentum (RSI, MACD, Stochastic, etc.) to trend, volume, volatility, and oscillator tools—all pre-calculated, centered/scaled, and available as plots.
// Enhanced Custom Indicators Export - 45 Technical Indicators
// Comprehensive technical analysis suite for advanced market regime detection
//@version=6
indicator('Enhanced Custom Indicators Export | Fractalyst', shorttitle='Enhanced CI Export', overlay=false, scale=scale.right, max_labels_count=500, max_lines_count=500)
// |----- Input Parameters -----| //
momentum_group = "Momentum Indicators"
trend_group = "Trend Indicators"
volume_group = "Volume Indicators"
volatility_group = "Volatility Indicators"
oscillator_group = "Oscillator Indicators"
display_group = "Display Settings"
// Common lengths
length_14 = input.int(14, "Standard Length (14)", minval=1, maxval=100, group=momentum_group)
length_20 = input.int(20, "Medium Length (20)", minval=1, maxval=200, group=trend_group)
length_50 = input.int(50, "Long Length (50)", minval=1, maxval=200, group=trend_group)
// Display options
show_table = input.bool(true, "Show Values Table", group=display_group)
table_size = input.string("Small", "Table Size", options= , group=display_group)
// |----- MOMENTUM INDICATORS (15 indicators) -----| //
// 1. RSI (Relative Strength Index)
rsi_14 = ta.rsi(close, length_14)
rsi_centered = rsi_14 - 50
// 2. Stochastic Oscillator
stoch_k = ta.stoch(close, high, low, length_14)
stoch_d = ta.sma(stoch_k, 3)
stoch_centered = stoch_k - 50
// 3. Williams %R
williams_r = ta.stoch(close, high, low, length_14) - 100
// 4. MACD (Moving Average Convergence Divergence)
= ta.macd(close, 12, 26, 9)
// 5. Momentum (Rate of Change)
momentum = ta.mom(close, length_14)
momentum_pct = (momentum / close ) * 100
// 6. Rate of Change (ROC)
roc = ta.roc(close, length_14)
// 7. Commodity Channel Index (CCI)
cci = ta.cci(close, length_20)
// 8. Money Flow Index (MFI)
mfi = ta.mfi(close, length_14)
mfi_centered = mfi - 50
// 9. Awesome Oscillator (AO)
ao = ta.sma(hl2, 5) - ta.sma(hl2, 34)
// 10. Accelerator Oscillator (AC)
ac = ao - ta.sma(ao, 5)
// 11. Chande Momentum Oscillator (CMO)
cmo = ta.cmo(close, length_14)
// 12. Detrended Price Oscillator (DPO)
dpo = close - ta.sma(close, length_20)
// 13. Price Oscillator (PPO)
ppo = ta.sma(close, 12) - ta.sma(close, 26)
ppo_pct = (ppo / ta.sma(close, 26)) * 100
// 14. TRIX
trix_ema1 = ta.ema(close, length_14)
trix_ema2 = ta.ema(trix_ema1, length_14)
trix_ema3 = ta.ema(trix_ema2, length_14)
trix = ta.roc(trix_ema3, 1) * 10000
// 15. Klinger Oscillator
klinger = ta.ema(volume * (high + low + close) / 3, 34) - ta.ema(volume * (high + low + close) / 3, 55)
// 16. Fisher Transform
fisher_hl2 = 0.5 * (hl2 - ta.lowest(hl2, 10)) / (ta.highest(hl2, 10) - ta.lowest(hl2, 10)) - 0.25
fisher = 0.5 * math.log((1 + fisher_hl2) / (1 - fisher_hl2))
// 17. Stochastic RSI
stoch_rsi = ta.stoch(rsi_14, rsi_14, rsi_14, length_14)
stoch_rsi_centered = stoch_rsi - 50
// 18. Relative Vigor Index (RVI)
rvi_num = ta.swma(close - open)
rvi_den = ta.swma(high - low)
rvi = rvi_den != 0 ? rvi_num / rvi_den : 0
// 19. Balance of Power (BOP)
bop = (close - open) / (high - low)
// |----- TREND INDICATORS (10 indicators) -----| //
// 20. Simple Moving Average Momentum
sma_20 = ta.sma(close, length_20)
sma_momentum = ((close - sma_20) / sma_20) * 100
// 21. Exponential Moving Average Momentum
ema_20 = ta.ema(close, length_20)
ema_momentum = ((close - ema_20) / ema_20) * 100
// 22. Parabolic SAR
sar = ta.sar(0.02, 0.02, 0.2)
sar_trend = close > sar ? 1 : -1
// 23. Linear Regression Slope
lr_slope = ta.linreg(close, length_20, 0) - ta.linreg(close, length_20, 1)
// 24. Moving Average Convergence (MAC)
mac = ta.sma(close, 10) - ta.sma(close, 30)
// 25. Trend Intensity Index (TII)
tii_sum = 0.0
for i = 1 to length_20
tii_sum += close > close ? 1 : 0
tii = (tii_sum / length_20) * 100
// 26. Ichimoku Cloud Components
ichimoku_tenkan = (ta.highest(high, 9) + ta.lowest(low, 9)) / 2
ichimoku_kijun = (ta.highest(high, 26) + ta.lowest(low, 26)) / 2
ichimoku_signal = ichimoku_tenkan > ichimoku_kijun ? 1 : -1
// 27. MESA Adaptive Moving Average (MAMA)
mama_alpha = 2.0 / (length_20 + 1)
mama = ta.ema(close, length_20)
mama_momentum = ((close - mama) / mama) * 100
// 28. Zero Lag Exponential Moving Average (ZLEMA)
zlema_lag = math.round((length_20 - 1) / 2)
zlema_data = close + (close - close )
zlema = ta.ema(zlema_data, length_20)
zlema_momentum = ((close - zlema) / zlema) * 100
// |----- VOLUME INDICATORS (6 indicators) -----| //
// 29. On-Balance Volume (OBV)
obv = ta.obv
// 30. Volume Rate of Change (VROC)
vroc = ta.roc(volume, length_14)
// 31. Price Volume Trend (PVT)
pvt = ta.pvt
// 32. Negative Volume Index (NVI)
nvi = 0.0
nvi := volume < volume ? nvi + ((close - close ) / close ) * nvi : nvi
// 33. Positive Volume Index (PVI)
pvi = 0.0
pvi := volume > volume ? pvi + ((close - close ) / close ) * pvi : pvi
// 34. Volume Oscillator
vol_osc = ta.sma(volume, 5) - ta.sma(volume, 10)
// 35. Ease of Movement (EOM)
eom_distance = high - low
eom_box_height = volume / 1000000
eom = eom_box_height != 0 ? eom_distance / eom_box_height : 0
eom_sma = ta.sma(eom, length_14)
// 36. Force Index
force_index = volume * (close - close )
force_index_sma = ta.sma(force_index, length_14)
// |----- VOLATILITY INDICATORS (10 indicators) -----| //
// 37. Average True Range (ATR)
atr = ta.atr(length_14)
atr_pct = (atr / close) * 100
// 38. Bollinger Bands Position
bb_basis = ta.sma(close, length_20)
bb_dev = 2.0 * ta.stdev(close, length_20)
bb_upper = bb_basis + bb_dev
bb_lower = bb_basis - bb_dev
bb_position = bb_dev != 0 ? (close - bb_basis) / bb_dev : 0
bb_width = bb_dev != 0 ? (bb_upper - bb_lower) / bb_basis * 100 : 0
// 39. Keltner Channels Position
kc_basis = ta.ema(close, length_20)
kc_range = ta.ema(ta.tr, length_20)
kc_upper = kc_basis + (2.0 * kc_range)
kc_lower = kc_basis - (2.0 * kc_range)
kc_position = kc_range != 0 ? (close - kc_basis) / kc_range : 0
// 40. Donchian Channels Position
dc_upper = ta.highest(high, length_20)
dc_lower = ta.lowest(low, length_20)
dc_basis = (dc_upper + dc_lower) / 2
dc_position = (dc_upper - dc_lower) != 0 ? (close - dc_basis) / (dc_upper - dc_lower) : 0
// 41. Standard Deviation
std_dev = ta.stdev(close, length_20)
std_dev_pct = (std_dev / close) * 100
// 42. Relative Volatility Index (RVI)
rvi_up = ta.stdev(close > close ? close : 0, length_14)
rvi_down = ta.stdev(close < close ? close : 0, length_14)
rvi_total = rvi_up + rvi_down
rvi_volatility = rvi_total != 0 ? (rvi_up / rvi_total) * 100 : 50
// 43. Historical Volatility
hv_returns = math.log(close / close )
hv = ta.stdev(hv_returns, length_20) * math.sqrt(252) * 100
// 44. Garman-Klass Volatility
gk_vol = math.log(high/low) * math.log(high/low) - (2*math.log(2)-1) * math.log(close/open) * math.log(close/open)
gk_volatility = math.sqrt(ta.sma(gk_vol, length_20)) * 100
// 45. Parkinson Volatility
park_vol = math.log(high/low) * math.log(high/low)
parkinson = math.sqrt(ta.sma(park_vol, length_20) / (4 * math.log(2))) * 100
// 46. Rogers-Satchell Volatility
rs_vol = math.log(high/close) * math.log(high/open) + math.log(low/close) * math.log(low/open)
rogers_satchell = math.sqrt(ta.sma(rs_vol, length_20)) * 100
// |----- OSCILLATOR INDICATORS (5 indicators) -----| //
// 47. Elder Ray Index
elder_bull = high - ta.ema(close, 13)
elder_bear = low - ta.ema(close, 13)
elder_power = elder_bull + elder_bear
// 48. Schaff Trend Cycle (STC)
stc_macd = ta.ema(close, 23) - ta.ema(close, 50)
stc_k = ta.stoch(stc_macd, stc_macd, stc_macd, 10)
stc_d = ta.ema(stc_k, 3)
stc = ta.stoch(stc_d, stc_d, stc_d, 10)
// 49. Coppock Curve
coppock_roc1 = ta.roc(close, 14)
coppock_roc2 = ta.roc(close, 11)
coppock = ta.wma(coppock_roc1 + coppock_roc2, 10)
// 50. Know Sure Thing (KST)
kst_roc1 = ta.roc(close, 10)
kst_roc2 = ta.roc(close, 15)
kst_roc3 = ta.roc(close, 20)
kst_roc4 = ta.roc(close, 30)
kst = ta.sma(kst_roc1, 10) + 2*ta.sma(kst_roc2, 10) + 3*ta.sma(kst_roc3, 10) + 4*ta.sma(kst_roc4, 15)
// 51. Percentage Price Oscillator (PPO)
ppo_line = ((ta.ema(close, 12) - ta.ema(close, 26)) / ta.ema(close, 26)) * 100
ppo_signal = ta.ema(ppo_line, 9)
ppo_histogram = ppo_line - ppo_signal
// |----- PLOT MAIN INDICATORS -----| //
// Plot key momentum indicators
plot(rsi_centered, title="01_RSI_Centered", color=color.purple, linewidth=1)
plot(stoch_centered, title="02_Stoch_Centered", color=color.blue, linewidth=1)
plot(williams_r, title="03_Williams_R", color=color.red, linewidth=1)
plot(macd_histogram, title="04_MACD_Histogram", color=color.orange, linewidth=1)
plot(cci, title="05_CCI", color=color.green, linewidth=1)
// Plot trend indicators
plot(sma_momentum, title="06_SMA_Momentum", color=color.navy, linewidth=1)
plot(ema_momentum, title="07_EMA_Momentum", color=color.maroon, linewidth=1)
plot(sar_trend, title="08_SAR_Trend", color=color.teal, linewidth=1)
plot(lr_slope, title="09_LR_Slope", color=color.lime, linewidth=1)
plot(mac, title="10_MAC", color=color.fuchsia, linewidth=1)
// Plot volatility indicators
plot(atr_pct, title="11_ATR_Pct", color=color.yellow, linewidth=1)
plot(bb_position, title="12_BB_Position", color=color.aqua, linewidth=1)
plot(kc_position, title="13_KC_Position", color=color.olive, linewidth=1)
plot(std_dev_pct, title="14_StdDev_Pct", color=color.silver, linewidth=1)
plot(bb_width, title="15_BB_Width", color=color.gray, linewidth=1)
// Plot volume indicators
plot(vroc, title="16_VROC", color=color.blue, linewidth=1)
plot(eom_sma, title="17_EOM", color=color.red, linewidth=1)
plot(vol_osc, title="18_Vol_Osc", color=color.green, linewidth=1)
plot(force_index_sma, title="19_Force_Index", color=color.orange, linewidth=1)
plot(obv, title="20_OBV", color=color.purple, linewidth=1)
// Plot additional oscillators
plot(ao, title="21_Awesome_Osc", color=color.navy, linewidth=1)
plot(cmo, title="22_CMO", color=color.maroon, linewidth=1)
plot(dpo, title="23_DPO", color=color.teal, linewidth=1)
plot(trix, title="24_TRIX", color=color.lime, linewidth=1)
plot(fisher, title="25_Fisher", color=color.fuchsia, linewidth=1)
// Plot more momentum indicators
plot(mfi_centered, title="26_MFI_Centered", color=color.yellow, linewidth=1)
plot(ac, title="27_AC", color=color.aqua, linewidth=1)
plot(ppo_pct, title="28_PPO_Pct", color=color.olive, linewidth=1)
plot(stoch_rsi_centered, title="29_StochRSI_Centered", color=color.silver, linewidth=1)
plot(klinger, title="30_Klinger", color=color.gray, linewidth=1)
// Plot trend continuation
plot(tii, title="31_TII", color=color.blue, linewidth=1)
plot(ichimoku_signal, title="32_Ichimoku_Signal", color=color.red, linewidth=1)
plot(mama_momentum, title="33_MAMA_Momentum", color=color.green, linewidth=1)
plot(zlema_momentum, title="34_ZLEMA_Momentum", color=color.orange, linewidth=1)
plot(bop, title="35_BOP", color=color.purple, linewidth=1)
// Plot volume continuation
plot(nvi, title="36_NVI", color=color.navy, linewidth=1)
plot(pvi, title="37_PVI", color=color.maroon, linewidth=1)
plot(momentum_pct, title="38_Momentum_Pct", color=color.teal, linewidth=1)
plot(roc, title="39_ROC", color=color.lime, linewidth=1)
plot(rvi, title="40_RVI", color=color.fuchsia, linewidth=1)
// Plot volatility continuation
plot(dc_position, title="41_DC_Position", color=color.yellow, linewidth=1)
plot(rvi_volatility, title="42_RVI_Volatility", color=color.aqua, linewidth=1)
plot(hv, title="43_Historical_Vol", color=color.olive, linewidth=1)
plot(gk_volatility, title="44_GK_Volatility", color=color.silver, linewidth=1)
plot(parkinson, title="45_Parkinson_Vol", color=color.gray, linewidth=1)
// Plot final oscillators
plot(rogers_satchell, title="46_RS_Volatility", color=color.blue, linewidth=1)
plot(elder_power, title="47_Elder_Power", color=color.red, linewidth=1)
plot(stc, title="48_STC", color=color.green, linewidth=1)
plot(coppock, title="49_Coppock", color=color.orange, linewidth=1)
plot(kst, title="50_KST", color=color.purple, linewidth=1)
// Plot final indicators
plot(ppo_histogram, title="51_PPO_Histogram", color=color.navy, linewidth=1)
plot(pvt, title="52_PVT", color=color.maroon, linewidth=1)
// |----- Reference Lines -----| //
hline(0, "Zero Line", color=color.gray, linestyle=hline.style_dashed, linewidth=1)
hline(50, "Midline", color=color.gray, linestyle=hline.style_dotted, linewidth=1)
hline(-50, "Lower Midline", color=color.gray, linestyle=hline.style_dotted, linewidth=1)
hline(25, "Upper Threshold", color=color.gray, linestyle=hline.style_dotted, linewidth=1)
hline(-25, "Lower Threshold", color=color.gray, linestyle=hline.style_dotted, linewidth=1)
// |----- Enhanced Information Table -----| //
if show_table and barstate.islast
table_position = position.top_right
table_text_size = table_size == "Tiny" ? size.tiny : table_size == "Small" ? size.small : size.normal
var table info_table = table.new(table_position, 3, 18, bgcolor=color.new(color.white, 85), border_width=1, border_color=color.gray)
// Headers
table.cell(info_table, 0, 0, 'Category', text_color=color.black, text_size=table_text_size, bgcolor=color.new(color.blue, 70))
table.cell(info_table, 1, 0, 'Indicator', text_color=color.black, text_size=table_text_size, bgcolor=color.new(color.blue, 70))
table.cell(info_table, 2, 0, 'Value', text_color=color.black, text_size=table_text_size, bgcolor=color.new(color.blue, 70))
// Key Momentum Indicators
table.cell(info_table, 0, 1, 'MOMENTUM', text_color=color.purple, text_size=table_text_size, bgcolor=color.new(color.purple, 90))
table.cell(info_table, 1, 1, 'RSI Centered', text_color=color.purple, text_size=table_text_size)
table.cell(info_table, 2, 1, str.tostring(rsi_centered, '0.00'), text_color=color.purple, text_size=table_text_size)
table.cell(info_table, 0, 2, '', text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 1, 2, 'Stoch Centered', text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 2, 2, str.tostring(stoch_centered, '0.00'), text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 0, 3, '', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 1, 3, 'Williams %R', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 2, 3, str.tostring(williams_r, '0.00'), text_color=color.red, text_size=table_text_size)
table.cell(info_table, 0, 4, '', text_color=color.orange, text_size=table_text_size)
table.cell(info_table, 1, 4, 'MACD Histogram', text_color=color.orange, text_size=table_text_size)
table.cell(info_table, 2, 4, str.tostring(macd_histogram, '0.000'), text_color=color.orange, text_size=table_text_size)
table.cell(info_table, 0, 5, '', text_color=color.green, text_size=table_text_size)
table.cell(info_table, 1, 5, 'CCI', text_color=color.green, text_size=table_text_size)
table.cell(info_table, 2, 5, str.tostring(cci, '0.00'), text_color=color.green, text_size=table_text_size)
// Key Trend Indicators
table.cell(info_table, 0, 6, 'TREND', text_color=color.navy, text_size=table_text_size, bgcolor=color.new(color.navy, 90))
table.cell(info_table, 1, 6, 'SMA Momentum %', text_color=color.navy, text_size=table_text_size)
table.cell(info_table, 2, 6, str.tostring(sma_momentum, '0.00'), text_color=color.navy, text_size=table_text_size)
table.cell(info_table, 0, 7, '', text_color=color.maroon, text_size=table_text_size)
table.cell(info_table, 1, 7, 'EMA Momentum %', text_color=color.maroon, text_size=table_text_size)
table.cell(info_table, 2, 7, str.tostring(ema_momentum, '0.00'), text_color=color.maroon, text_size=table_text_size)
table.cell(info_table, 0, 8, '', text_color=color.teal, text_size=table_text_size)
table.cell(info_table, 1, 8, 'SAR Trend', text_color=color.teal, text_size=table_text_size)
table.cell(info_table, 2, 8, str.tostring(sar_trend, '0'), text_color=color.teal, text_size=table_text_size)
table.cell(info_table, 0, 9, '', text_color=color.lime, text_size=table_text_size)
table.cell(info_table, 1, 9, 'Linear Regression', text_color=color.lime, text_size=table_text_size)
table.cell(info_table, 2, 9, str.tostring(lr_slope, '0.000'), text_color=color.lime, text_size=table_text_size)
// Key Volatility Indicators
table.cell(info_table, 0, 10, 'VOLATILITY', text_color=color.yellow, text_size=table_text_size, bgcolor=color.new(color.yellow, 90))
table.cell(info_table, 1, 10, 'ATR %', text_color=color.yellow, text_size=table_text_size)
table.cell(info_table, 2, 10, str.tostring(atr_pct, '0.00'), text_color=color.yellow, text_size=table_text_size)
table.cell(info_table, 0, 11, '', text_color=color.aqua, text_size=table_text_size)
table.cell(info_table, 1, 11, 'BB Position', text_color=color.aqua, text_size=table_text_size)
table.cell(info_table, 2, 11, str.tostring(bb_position, '0.00'), text_color=color.aqua, text_size=table_text_size)
table.cell(info_table, 0, 12, '', text_color=color.olive, text_size=table_text_size)
table.cell(info_table, 1, 12, 'KC Position', text_color=color.olive, text_size=table_text_size)
table.cell(info_table, 2, 12, str.tostring(kc_position, '0.00'), text_color=color.olive, text_size=table_text_size)
// Key Volume Indicators
table.cell(info_table, 0, 13, 'VOLUME', text_color=color.blue, text_size=table_text_size, bgcolor=color.new(color.blue, 90))
table.cell(info_table, 1, 13, 'Volume ROC', text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 2, 13, str.tostring(vroc, '0.00'), text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 0, 14, '', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 1, 14, 'EOM', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 2, 14, str.tostring(eom_sma, '0.000'), text_color=color.red, text_size=table_text_size)
// Key Oscillators
table.cell(info_table, 0, 15, 'OSCILLATORS', text_color=color.purple, text_size=table_text_size, bgcolor=color.new(color.purple, 90))
table.cell(info_table, 1, 15, 'Awesome Osc', text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 2, 15, str.tostring(ao, '0.000'), text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 0, 16, '', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 1, 16, 'Fisher Transform', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 2, 16, str.tostring(fisher, '0.000'), text_color=color.red, text_size=table_text_size)
// Summary Statistics
table.cell(info_table, 0, 17, 'SUMMARY', text_color=color.black, text_size=table_text_size, bgcolor=color.new(color.gray, 70))
table.cell(info_table, 1, 17, 'Total Indicators: 52', text_color=color.black, text_size=table_text_size)
regime_color = rsi_centered > 10 ? color.green : rsi_centered < -10 ? color.red : color.gray
regime_text = rsi_centered > 10 ? "BULLISH" : rsi_centered < -10 ? "BEARISH" : "NEUTRAL"
table.cell(info_table, 2, 17, regime_text, text_color=regime_color, text_size=table_text_size)
This makes it the perfect “indicator backbone” for quantitative and systematic traders who want to prototype, combine, and test new regime detection models—especially in combination with the Markov Chain indicator.
How to use this script with the Markov Chain for research and backtesting:
Add the Enhanced Indicator Export to your chart.
Every calculated indicator is available as an individual data stream.
Connect the indicator(s) you want as custom input(s) to the Markov Chain’s “Custom Indicators” option.
In the Markov Chain indicator’s settings, turn ON the custom indicator mode.
For each of the three custom indicator inputs, select the exported plot from the Enhanced Export script—the menu lists all 45+ signals by name.
This creates a powerful, modular regime-detection engine where you can mix-and-match momentum, trend, volume, or custom combinations for advanced filtering.
Backtest regime logic directly.
Once you’ve connected your chosen indicators, the Markov Chain script performs regime detection (Bull/Neutral/Bear) based on your selected features—not just price returns.
The regime detection is robust, automatically normalized (using Z-score), and outputs bias (1, -1, 0) for plug-and-play integration.
Export the regime bias for programmatic use.
As described above, use input.source() in your Pine Script strategy or system and link the bias output.
You can now filter signals, control trade direction/size, or design pairs-trading that respect true, indicator-driven market regimes.
With this framework, you’re not limited to static or simplistic regime filters. You can rigorously define, test, and refine what “market regime” means for your strategies—using the technical features that matter most to you.
Optimize your signal generation by backtesting across a universe of meaningful indicator blends.
Enhance risk management with objective, real-time regime boundaries.
Accelerate your research: iterate quickly, swap indicator components, and see results with minimal code changes.
Automate multi-asset or pairs-trading by integrating regime context directly into strategy logic.
Add both scripts to your chart, connect your preferred features, and start investigating your best regime-based trades—entirely within the TradingView ecosystem.
References & Further Reading
Ang, A., & Bekaert, G. (2002). “Regime Switches in Interest Rates.” Journal of Business & Economic Statistics, 20(2), 163–182.
Hamilton, J. D. (1989). “A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle.” Econometrica, 57(2), 357–384.
Markov, A. A. (1906). "Extension of the Limit Theorems of Probability Theory to a Sum of Variables Connected in a Chain." The Notes of the Imperial Academy of Sciences of St. Petersburg.
Guidolin, M., & Timmermann, A. (2007). “Asset Allocation under Multivariate Regime Switching.” Journal of Economic Dynamics and Control, 31(11), 3503–3544.
Murphy, J. J. (1999). Technical Analysis of the Financial Markets. New York Institute of Finance.
Brock, W., Lakonishok, J., & LeBaron, B. (1992). “Simple Technical Trading Rules and the Stochastic Properties of Stock Returns.” Journal of Finance, 47(5), 1731–1764.
Zucchini, W., MacDonald, I. L., & Langrock, R. (2017). Hidden Markov Models for Time Series: An Introduction Using R (2nd ed.). Chapman and Hall/CRC.
On Quantitative Finance and Markov Models:
Lo, A. W., & Hasanhodzic, J. (2009). The Heretics of Finance: Conversations with Leading Practitioners of Technical Analysis. Bloomberg Press.
Patterson, S. (2016). The Man Who Solved the Market: How Jim Simons Launched the Quant Revolution. Penguin Press.
TradingView Pine Script Documentation: www.tradingview.com
TradingView Blog: “Use an Input From Another Indicator With Your Strategy” www.tradingview.com
GeeksforGeeks: “What is the Difference Between Markov Chains and Hidden Markov Models?” www.geeksforgeeks.org
What makes this indicator original and unique?
- On‑chart, real‑time Markov. The chain is drawn directly on your chart. You see the current regime, its tendency to stay (self‑loop), and the usual next step (arrows) as bars confirm.
- Source‑agnostic by design. The engine runs on any series you select via input.source() — price, your own oscillator, a composite score, anything you compute in the script.
- Automatic normalization + regime mapping. Different inputs live on different scales. The script standardizes your chosen source and maps it into clear regimes (e.g., Bull / Bear / Neutral) without you micromanaging thresholds each time.
- Rolling, bar‑by‑bar learning. Transition tendencies are computed from a rolling window of confirmed bars. What you see is exactly what the market did in that window.
- Fast experimentation. Switch the source, adjust the window, and the Markov view updates instantly. It’s a rapid way to test ideas and feel regime persistence/switch behavior.
Integrate your own signals (using input.source())
- In settings, choose the Source . This is powered by input.source() .
- Feed it price, an indicator you compute inside the script, or a custom composite series.
- The script will automatically normalize that series and process it through the Markov engine, mapping it to regimes and updating the on‑chart spheres/arrows in real time.
Credits:
Deep gratitude to @RicardoSantos for both the foundational Markov chain processing engine and inspiring open-source contributions, which made advanced probabilistic market modeling accessible to the TradingView community.
Special thanks to @Alien_Algorithms for the innovative and visually stunning 3D sphere logic that powers the indicator’s animated, regime-based visualization.
Disclaimer
This tool summarizes recent behavior. It is not financial advice and not a guarantee of future results.
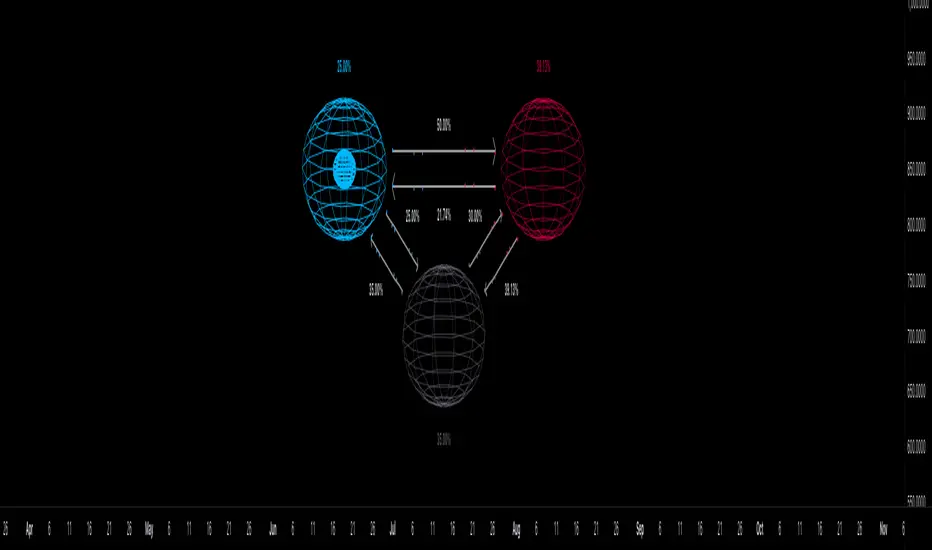
Correlation HeatMap [TradingFinder] Sessions Data Science Stats🔵 Introduction
n financial markets, correlation describes the statistical relationship between the price movements of two assets and how they interact over time. It plays a key role in both trading and investing by helping analyze asset behavior, manage portfolio risk, and understand intermarket dynamics. The Correlation Heatmap is a visual tool that shows how the correlation between multiple assets and a central reference asset (the Main Symbol) changes over time.
It supports four market types forex, stocks, crypto, and a custom mode making it adaptable to different trading environments. The heatmap uses a color-coded grid where warmer tones represent stronger negative correlations and cooler tones indicate stronger positive ones. This intuitive color system allows traders to quickly identify when assets move together or diverge, offering real-time insights that go beyond traditional correlation tables.
🟣 How to Interpret the Heatmap Visually ?
Each cell represents the correlation between the main symbol and one compared asset at a specific time.
Warm colors (e.g. red, orange) suggest strong negative correlation as one asset rises, the other tends to fall.
Cool colors (e.g. blue, green) suggest strong positive correlation both assets tend to move in the same direction.
Lighter shades indicate weaker correlations, while darker shades indicate stronger correlations.
The heatmap updates over time, allowing users to detect changes in correlation during market events or trading sessions.
One of the standout features of this indicator is its ability to overlay global market sessions such as Tokyo, London, New York, or major equity opens directly onto the heatmap timeline. This alignment lets traders observe how correlation structures respond to real-world session changes. For example, they can spot when assets shift from being inversely correlated to moving together as a new session opens, potentially signaling new momentum or macro flow. The customizable symbol setup (including up to 20 compared assets) makes it ideal not only for forex and crypto traders but also for multi-asset and sector-based stock analysis.
🟣 Use Cases and Advantages
Analyze sector rotation in equities by tracking correlation to major indices like SPX or DJI.
Monitor altcoin behavior relative to Bitcoin to find early entry opportunities in crypto markets.
Detect changes in currency alignment with DXY across trading sessions in forex.
Identify correlation breakdowns during market volatility, signaling possible new trends.
Use correlation shifts as confirmation for trade setups or to hedge multi-asset exposure
🔵 How to Use
Correlation is one of the core concepts in financial analysis and allows traders to understand how assets behave in relation to one another. The Correlation Heatmap extends this idea by going beyond a simple number or static matrix. Instead, it presents a dynamic visual map of how correlations shift over time.
In this indicator, a Main Symbol is selected as the reference point for analysis. In standard modes such as forex, stocks, or crypto, the symbol currently shown on the main chart is automatically used as the main symbol. This allows users to begin correlation analysis right away without adjusting any settings.
The horizontal axis of the heatmap shows time, while the vertical axis lists the selected assets. Each cell on the heatmap shows the correlation between that asset and the main symbol at a given moment.
This approach is especially useful for intermarket analysis. In forex, for example, tracking how currency pairs like OANDA:EURUSD EURUSD, FX:GBPUSD GBPUSD, and PEPPERSTONE:AUDUSD AUDUSD correlate with TVC:DXY DXY can give insight into broader capital flow.
If these pairs start showing increasing positive correlation with DXY say, shifting from blue to light green it could signal the start of a new phase or reversal. Conversely, if negative correlation fades gradually, it may suggest weakening relationships and more independent or volatile movement.
In the crypto market, watching how altcoins correlate with Bitcoin can help identify ideal entry points in secondary assets. In the stock market, analyzing how companies within the same sector move in relation to a major index like SP:SPX SPX or DJ:DJI DJI is also a highly effective technique for both technical and fundamental analysts.
This indicator not only visualizes correlation but also displays major market sessions. When enabled, this feature helps traders observe how correlation behavior changes at the start of each session, whether it's Tokyo, London, New York, or the opening of stock exchanges. Many key shifts, breakouts, or reversals tend to happen around these times, and the heatmap makes them easy to spot.
Another important feature is the market selection mode. Users can switch between forex, crypto, stocks, or custom markets and see correlation behavior specific to each one. In custom mode, users can manually select any combination of symbols for more advanced or personalized analysis. This makes the heatmap valuable not only for forex traders but also for stock traders, crypto analysts, and multi-asset strategists.
Finally, the heatmap's color-coded design helps users make sense of the data quickly. Warm colors such as red and orange reflect stronger negative correlations, while cool colors like blue and green represent stronger positive relationships. This simplicity and clarity make the tool accessible to both beginners and experienced traders.
🔵 Settings
Correlation Period: Allows you to set how many historical bars are used for calculating correlation. A higher number means a smoother, slower-moving heatmap, while a lower number makes it more responsive to recent changes.
Select Market: Lets you choose between Forex, Stock, Crypto, or Custom. In the first three options, the chart’s active symbol is automatically used as the Main Symbol. In Custom mode, you can manually define the Main Symbol and up to 20 Compared Symbols.
Show Open Session: Enables the display of major trading sessions such as Tokyo, London, New York, or equity market opening hours directly on the timeline. This helps you connect correlation shifts with real-world market activity.
Market Mode: Lets you select whether the displayed sessions relate to the forex or stock market.
🔵 Conclusion
The Correlation Heatmap is a robust and flexible tool for analyzing the relationship between assets across different markets. By tracking how correlations change in real time, traders can better identify alignment or divergence between symbols and gain valuable insights into market structure.
Support for multiple asset classes, session overlays, and intuitive visual cues make this one of the most effective tools for intermarket analysis.
Whether you’re looking to manage portfolio risk, validate entry points, or simply understand capital flow across markets, this heatmap provides a clear and actionable perspective that you can rely on.

TimeSeriesBenchmarkMeasuresLibrary "TimeSeriesBenchmarkMeasures"
Time Series Benchmark Metrics. \
Provides a comprehensive set of functions for benchmarking time series data, allowing you to evaluate the accuracy, stability, and risk characteristics of various models or strategies. The functions cover a wide range of statistical measures, including accuracy metrics (MAE, MSE, RMSE, NRMSE, MAPE, SMAPE), autocorrelation analysis (ACF, ADF), and risk measures (Theils Inequality, Sharpness, Resolution, Coverage, and Pinball).
___
Reference:
- github.com .
- medium.com .
- www.salesforce.com .
- towardsdatascience.com .
- github.com .
mae(actual, forecasts)
In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement.
Parameters:
actual (array) : List of actual values.
forecasts (array) : List of forecasts values.
Returns: - Mean Absolute Error (MAE).
___
Reference:
- en.wikipedia.org .
- The Orange Book of Machine Learning - Carl McBride Ellis .
mse(actual, forecasts)
The Mean Squared Error (MSE) is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
Parameters:
actual (array) : List of actual values.
forecasts (array) : List of forecasts values.
Returns: - Mean Squared Error (MSE).
___
Reference:
- en.wikipedia.org .
rmse(targets, forecasts, order, offset)
Calculates the Root Mean Squared Error (RMSE) between target observations and forecasts. RMSE is a standard measure of the differences between values predicted by a model and the values actually observed.
Parameters:
targets (array) : List of target observations.
forecasts (array) : List of forecasts.
order (int) : Model order parameter that determines the starting position in the targets array, `default=0`.
offset (int) : Forecast offset related to target, `default=0`.
Returns: - RMSE value.
nmrse(targets, forecasts, order, offset)
Normalised Root Mean Squared Error.
Parameters:
targets (array) : List of target observations.
forecasts (array) : List of forecasts.
order (int) : Model order parameter that determines the starting position in the targets array, `default=0`.
offset (int) : Forecast offset related to target, `default=0`.
Returns: - NRMSE value.
rmse_interval(targets, forecasts)
Root Mean Squared Error for a set of interval windows. Computes RMSE by converting interval forecasts (with min/max bounds) into point forecasts using the mean of the interval bounds, then compares against actual target values.
Parameters:
targets (array) : List of target observations.
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - RMSE value for the combined interval list.
mape(targets, forecasts)
Mean Average Percentual Error.
Parameters:
targets (array) : List of target observations.
forecasts (array) : List of forecasts.
Returns: - MAPE value.
smape(targets, forecasts, mode)
Symmetric Mean Average Percentual Error. Calculates the Mean Absolute Percentage Error (MAPE) between actual targets and forecasts. MAPE is a common metric for evaluating forecast accuracy, expressed as a percentage, lower values indicate a better forecast accuracy.
Parameters:
targets (array) : List of target observations.
forecasts (array) : List of forecasts.
mode (int) : Type of method: default=0:`sum(abs(Fi-Ti)) / sum(Fi+Ti)` , 1:`mean(abs(Fi-Ti) / ((Fi + Ti) / 2))` , 2:`mean(abs(Fi-Ti) / (abs(Fi) + abs(Ti))) * 100`
Returns: - SMAPE value.
mape_interval(targets, forecasts)
Mean Average Percentual Error for a set of interval windows.
Parameters:
targets (array) : List of target observations.
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - MAPE value for the combined interval list.
acf(data, k)
Autocorrelation Function (ACF) for a time series at a specified lag.
Parameters:
data (array) : Sample data of the observations.
k (int) : The lag period for which to calculate the autocorrelation. Must be a non-negative integer.
Returns: - The autocorrelation value at the specified lag, ranging from -1 to 1.
___
The autocorrelation function measures the linear dependence between observations in a time series
at different time lags. It quantifies how well the series correlates with itself at different
time intervals, which is useful for identifying patterns, seasonality, and the appropriate
lag structure for time series models.
ACF values close to 1 indicate strong positive correlation, values close to -1 indicate
strong negative correlation, and values near 0 indicate no linear correlation.
___
Reference:
- statisticsbyjim.com
acf_multiple(data, k)
Autocorrelation function (ACF) for a time series at a set of specified lags.
Parameters:
data (array) : Sample data of the observations.
k (array) : List of lag periods for which to calculate the autocorrelation. Must be a non-negative integer.
Returns: - List of ACF values for provided lags.
___
The autocorrelation function measures the linear dependence between observations in a time series
at different time lags. It quantifies how well the series correlates with itself at different
time intervals, which is useful for identifying patterns, seasonality, and the appropriate
lag structure for time series models.
ACF values close to 1 indicate strong positive correlation, values close to -1 indicate
strong negative correlation, and values near 0 indicate no linear correlation.
___
Reference:
- statisticsbyjim.com
adfuller(data, n_lag, conf)
: Augmented Dickey-Fuller test for stationarity.
Parameters:
data (array) : Data series.
n_lag (int) : Maximum lag.
conf (string) : Confidence Probability level used to test for critical value, (`90%`, `95%`, `99%`).
Returns: - `adf` The test statistic.
- `crit` Critical value for the test statistic at the 10 % levels.
- `nobs` Number of observations used for the ADF regression and calculation of the critical values.
___
The Augmented Dickey-Fuller test is used to determine whether a time series is stationary
or contains a unit root (non-stationary). The null hypothesis is that the series has a unit root
(is non-stationary), while the alternative hypothesis is that the series is stationary.
A stationary time series has statistical properties that do not change over time, making it
suitable for many time series forecasting models. If the test statistic is less than the
critical value, we reject the null hypothesis and conclude the series is stationary.
___
Reference:
- www.jstor.org
- en.wikipedia.org
theils_inequality(targets, forecasts)
Calculates Theil's Inequality Coefficient, a measure of forecast accuracy that quantifies the relative difference between actual and predicted values.
Parameters:
targets (array) : List of target observations.
forecasts (array) : Matrix with list of forecasts, ordered column wise.
Returns: - Theil's Inequality Coefficient value, value closer to 0 is better.
___
Theil's Inequality Coefficient is calculated as: `sqrt(Sum((y_i - f_i)^2)) / (sqrt(Sum(y_i^2)) + sqrt(Sum(f_i^2)))`
where `y_i` represents actual values and `f_i` represents forecast values.
This metric ranges from 0 to infinity, with 0 indicating perfect forecast accuracy.
___
Reference:
- en.wikipedia.org
sharpness(forecasts)
The average width of the forecast intervals across all observations, representing the sharpness or precision of the predictive intervals.
Parameters:
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - Sharpness The sharpness level, which is the average width of all prediction intervals across the forecast horizon.
___
Sharpness is an important metric for evaluating forecast quality. It measures how narrow or wide the
prediction intervals are. Higher sharpness (narrower intervals) indicates greater precision in the
forecast intervals, while lower sharpness (wider intervals) suggests less precision.
The sharpness metric is calculated as the mean of the interval widths across all observations, where
each interval width is the difference between the upper and lower bounds of the prediction interval.
Note: This function assumes that the forecasts matrix has at least 2 columns, with the first column
representing the lower bounds and the second column representing the upper bounds of prediction intervals.
___
Reference:
- Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: principles and practice. OTexts. otexts.com
resolution(forecasts)
Calculates the resolution of forecast intervals, measuring the average absolute difference between individual forecast interval widths and the overall sharpness measure.
Parameters:
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - The average absolute difference between individual forecast interval widths and the overall sharpness measure, representing the resolution of the forecasts.
___
Resolution is a key metric for evaluating forecast quality that measures the consistency of prediction
interval widths. It quantifies how much the individual forecast intervals vary from the average interval
width (sharpness). High resolution indicates that the forecast intervals are relatively consistent
across observations, while low resolution suggests significant variation in interval widths.
The resolution is calculated as the mean absolute deviation of individual interval widths from the
overall sharpness value. This provides insight into the uniformity of the forecast uncertainty
estimates across the forecast horizon.
Note: This function requires the forecasts matrix to have at least 2 columns (min, max) representing
the lower and upper bounds of prediction intervals.
___
Reference:
- (sites.stat.washington.edu)
- (www.jstor.org)
coverage(targets, forecasts)
Calculates the coverage probability, which is the percentage of target values that fall within the corresponding forecasted prediction intervals.
Parameters:
targets (array) : List of target values.
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - Percent of target values that fall within their corresponding forecast intervals, expressed as a decimal value between 0 and 1 (or 0% and 100%).
___
Coverage probability is a crucial metric for evaluating the reliability of prediction intervals.
It measures how well the forecast intervals capture the actual observed values. An ideal forecast
should have a coverage probability close to the nominal confidence level (e.g., 90%, 95%, or 99%).
For example, if a 95% prediction interval is used, we expect approximately 95% of the actual
target values to fall within those intervals. If the coverage is significantly lower than the
nominal level, the intervals may be too narrow; if it's significantly higher, the intervals may
be too wide.
Note: This function requires the targets array and forecasts matrix to have the same number of
observations, and the forecasts matrix must have at least 2 columns (min, max) representing
the lower and upper bounds of prediction intervals.
___
Reference:
- (www.jstor.org)
pinball(tau, target, forecast)
Pinball loss function, measures the asymmetric loss for quantile forecasts.
Parameters:
tau (float) : The quantile level (between 0 and 1), where 0.5 represents the median.
target (float) : The actual observed value to compare against.
forecast (float) : The forecasted value.
Returns: - The Pinball loss value, which quantifies the distance between the forecast and target relative to the specified quantile level.
___
The Pinball loss function is specifically designed for evaluating quantile forecasts. It is
asymmetric, meaning it penalizes underestimates and overestimates differently depending on the
quantile level being evaluated.
For a given quantile τ, the loss function is defined as:
- If target >= forecast: (target - forecast) * τ
- If target < forecast: (forecast - target) * (1 - τ)
This loss function is commonly used in quantile regression and probabilistic forecasting
to evaluate how well forecasts capture specific quantiles of the target distribution.
___
Reference:
- (www.otexts.com)
pinball_mean(tau, targets, forecasts)
Calculates the mean pinball loss for quantile regression.
Parameters:
tau (float) : The quantile level (between 0 and 1), where 0.5 represents the median.
targets (array) : The actual observed values to compare against.
forecasts (matrix) : The forecasted values in matrix format with at least 2 columns (min, max).
Returns: - The mean pinball loss value across all observations.
___
The pinball_mean() function computes the average Pinball loss across multiple observations,
making it suitable for evaluating overall forecast performance in quantile regression tasks.
This function leverages the asymmetric Pinball loss function to evaluate how well forecasts
capture specific quantiles of the target distribution. The choice of which column from the
forecasts matrix to use depends on the quantile level:
- For τ ≤ 0.5: Uses the first column (min) of forecasts
- For τ > 0.5: Uses the second column (max) of forecasts
This loss function is commonly used in quantile regression and probabilistic forecasting
to evaluate how well forecasts capture specific quantiles of the target distribution.
___
Reference:
- (www.otexts.com)
Volume Rotor Clock [hapharmonic]🕰️ Volume Rotor Clock
The Volume Rotor Clock is an indicator that separates buy and sell volume, compiling these volumes over a recent number of bars or a specified past period, as defined by the user. This helps to reveal accumulation (buying) or distribution (selling) behavior, showing which side has superior volume. With its unique and beautiful display, the Volume Rotor Clock is more than just a timepiece; it's a dynamic dashboard that visualizes the buying and selling pressure of your favorite symbols, all wrapped in an elegant and fully customizable interface.
Instead of just tracking price, this indicator focuses on the engine behind the movement: volume. It helps you instantly identify which assets are under accumulation (buying) and which are under distribution (selling).
---
🎨 20 Pre-configured Templates
---
🧐 Interpreting the Clock Display
The interface is designed to give you multiple layers of information at a glance. Let's break down what each part represents.
1. The Main Clock Hands (Current Chart Symbol)
The clock hands—hour, minute, and second—are dedicated to the symbol on your current active chart .
Minute Hand: Displays the base currency of the current symbol (e.g., USDT, USD) at its tip.
Hour Hand: Displays the percentage of the winning volume side (buy vs. sell) at its tip.
Color Gauge: The color of the text characters at the tip of both the hour and minute hands acts as your primary volume gauge for the current symbol.
If buy volume is dominant , the text will be green .
If sell volume is dominant , the text will be red .
Tooltip: Hovering your mouse over the text at the tip of the hour or minute or other spherical elements hand will reveal a detailed tooltip with the precise Buy Volume, Sell Volume, Total Volume, Buy %, and Sell % for the current chart's symbol.
2. The Volume Scanner: Bulls & Bears (Symbols Inside the Clock) 🐂🐻
The circular symbols scattered inside the clock face are your multi-symbol volume scanner. They represent the assets you've selected in the indicator's settings.
Green Circles (Bulls - Upper Half): These represent symbols from your list where the total buy volume is greater than the total sell volume over the defined "Lookback" period. They are considered to be under bullish accumulation. The size of the circle and its text grows larger as the buy percentage becomes more dominant. The percentage shown within the circle represents the buy volume's share of the total volume, calculated over the 'Lookback (Bars)' you've set.
Red Circles (Bears - Lower Half): These represent symbols where the total sell volume is greater than the total buy volume. They are considered to be under bearish distribution or selling pressure. The size of the circle indicates the dominance of the sell-side volume. The percentage shown within the circle represents the sell volume's share of the total volume, calculated over the 'Lookback (Bars)' you've set.
3. The Bullish Watchlist (Symbols Above the Clock) ⭐
The symbols arranged neatly along the top edge of the clock are the "best of the bulls." They are symbols that are not only bullish but have also passed an additional, powerful strength filter.
What it Means: A symbol appears here when it shows signs of sustained, high-volume buying interest . It's a way to filter out noise and focus on assets with potentially significant accumulation phases.
The Filter Logic: For a bullish symbol (where total buy volume > total sell volume) to be promoted to the watchlist, its trading volume must meet specific criteria based on this formula:
ta.barssince(not(volume > ta.sma(volume, X))) >= Y
In plain English, this means: The indicator checks how many consecutive bars the `volume` has been greater than its `X`-bar Simple Moving Average (`ta.sma(volume, X)`). If this count is greater than or equal to `Y` bars, the condition is met.
(You can configure `X` (Volume MA Length) and `Y` (Consecutive Days Above MA) in the settings.)
Why it's Useful: This filter is powerful because it looks for consistency . A single spike in volume can be an anomaly. However, when an asset's volume remains consistently above its recent average for several consecutive days, it strongly suggests that larger players or a significant portion of the market are actively accumulating the asset. This sustained interest can often precede a significant upward price trend.
---
⚙️ Indicator Settings Explained
The Volume Rotor Clock is highly customizable. Here’s a detailed walkthrough of every setting available in the "Inputs" tab.
🎨 Color Scheme
This group allows you to control the entire aesthetic of the clock.
Template: Choose from a wide variety of professionally designed color themes.
Use Template: A simple checkbox to switch between using a pre-designed theme and creating your own.
`Checked`: You can select a theme from the dropdown menu, which offers 20 unique templates like "Cyberpunk Neon" or "Forest Green". All custom color settings below will be disabled (grayed out and unclickable).
`Unchecked`: The template dropdown is disabled, and you gain full control over every color element in the sections below.
🖌️ Custom Appearance & Colors
These settings are only active when "Use Template" is unchecked.
Flame Head / Tail: Sets the start and end colors for the dynamic flame effect that traces the clock's border, representing the second hand.
Numbers / Main Numbers: Customize the color of the regular hour numbers (1, 2, 4, 5...) and the main cardinal numbers (3, 6, 9, 12).
Sunburst Colors (1-6): Controls the six colors used in the gradient background for the "sunburst" effect inside the clock face.
Hands & Digital: Fine-tune the colors for the Hour/Minute Hand, Second Hand, central Pivot point, and the digital time display.
Chain Color / Width: Customize the appearance of the two chains holding the clock.
📡 Volume Scanner
Control the behavior of the multi-symbol scanner.
Show Scanner Labels: A master switch to show or hide all the bull/bear symbol circles inside the clock.
Lookback (Bars): A crucial setting that defines the calculation period for buy/sell volume for all scanned symbols. The calculation is a sum over the specified number of recent bars.
`0`: Calculates using the current bar only .
`7`: Calculates the sum of volume over the last 8 bars (the current bar + 7 historical bars).
Symbols List: Here you can enable/disable up to 20 slots and input the ticker for each symbol you want to scan (e.g., BINANCE:BTCUSDT , NASDAQ:AAPL ).
⭐ Bullish Watchlist Filter
Configure the criteria for the elite watchlist symbols displayed above the clock.
Enable Watchlist: A master switch to turn the entire watchlist feature on or off.
Volume MA Length: Sets the lookback period `(X)` for the Simple Moving Average of volume used in the filter.
Consecutive Days Above MA: Sets the minimum number of consecutive days `(Y)` that volume must close above its MA to qualify.
Symbols Per Row: Determines the maximum number of watchlist symbols that can fit in a single row before a new row is created above it.
Background / Text Color: When not using a template, you can set custom colors for the watchlist symbols' background and text.
📏 Position & Size
Adjust the clock's placement and dimensions on your chart.
Clock Timezone: Sets the timezone for the digital and analog time display. You can use standard formats like "America/New_York" or enter "Exchange" to sync with the chart's timezone.
Radius (Bars): Controls the overall size of the clock. The radius is measured in terms of the number of bars on the x-axis.
X Offset (Bars): Moves the entire clock horizontally. Positive values shift it to the right; negative values shift it to the left.
Y Offset (Price %): Moves the entire clock vertically as a percentage of your screen's price pane. Positive values move it up; negative values move it down.
Prime NumbersPrime Numbers highlights prime numbers (no surprise there 😅), tokens and the recent "active" feature in "input".
🔸 CONCEPTS
🔹 What are Prime Numbers?
A prime number (or a prime) is a natural number greater than 1 that is not a product of two smaller natural numbers.
Wikipedia: Prime number
🔹 Prime Factorization
The fundamental theorem of arithmetic states that every integer larger than 1 can be written as a product of one or more primes. More strongly, this product is unique in the sense that any two prime factorizations of the same number will have the same number of copies of the same primes, although their ordering may differ. So, although there are many different ways of finding a factorization using an integer factorization algorithm, they all must produce the same result. Primes can thus be considered the "basic building blocks" of the natural numbers.
Wikipedia: Fundamental theorem of arithmetic
Math Is Fun: Prime Factorization
We divide a given number by Prime Numbers until only Primes remain.
Example:
24 / 2 = 12 | 24 / 3 = 8
12 / 3 = 4 | 8 / 2 = 4
4 / 2 = 2 | 4 / 2 = 2
|
24 = 2 x 3 x 2 | 24 = 3 x 2 x 2
or | or
24 = 2² x 3 | 24 = 2² x 3
In other words, every natural/integer number above 1 has a unique representation as a product of prime numbers, no matter how the number is divided. Only the order can change, but the factors (the basic elements) are always the same.
🔸 USAGE
The Prime Numbers publication contains two use cases:
Prime Factorization: performed on "close" prices, or a manual chosen number.
List Prime Numbers: shows a list of Prime Numbers.
The other two options are discussed in the DETAILS chapter:
Prime Factorization Without Arrays
Find Prime Numbers
🔹 Prime Factorization
Users can choose to perform Prime Factorization on close prices or a manually given number.
❗️ Note that this option only applies to close prices above 1, which are also rounded since Prime Factorization can only be performed on natural (integer) numbers above 1.
In the image below, the left example shows Prime Factorization performed on each close price for the latest 50 bars (which is set with "Run script only on 'Last x Bars'" -> 50).
The right example shows Prime Factorization performed on a manually given number, in this case "1,340,011". This is done only on the last bar.
When the "Source" option "close price" is chosen, one can toggle "Also current price", where both the historical and the latest current price are factored. If disabled, only historical prices are factored.
Note that, depending on the chosen options, only applicable settings are available, due to a recent feature, namely the parameter "active" in settings.
Setting the "Source" option to "Manual - Limited" will factorize any given number between 1 and 1,340,011, the latter being the highest value in the available arrays with primes.
Setting to "Manual - Not Limited" enables the user to enter a higher number. If all factors of the manual entered number are in the 1 - 1,340,011 range, these factors will be shown; however, if a factor is higher than 1,340,011, the calculation will stop, after which a warning is shown:
The calculated factors are displayed as a label where identical factors are simplified with an exponent notation in superscript.
For example 2 x 2 x 2 x 5 x 7 x 7 will be noted as 2³ x 5 x 7²
🔹 List Prime Numbers
The "List Prime Numbers" option enables users to enter a number, where the first found Prime Number is shown, together with the next x Prime Numbers ("Amount", max. 200)
The highest shown Prime Number is 1,340,011.
One can set the number of shown columns to customize the displayed numbers ("Max. columns", max. 20).
🔸 DETAILS
The Prime Numbers publication consists out of 4 parts:
Prime Factorization Without Arrays
Prime Factorization
List Prime Numbers
Find Prime Numbers
The usage of "Prime Factorization" and "List Prime Numbers" is explained above.
🔹 Prime Factorization Without Arrays
This option is only there to highlight a hurdle while performing Prime Factorization.
The basic method of Prime Factorization is to divide the base number by 2, 3, ... until the result is an integer number. Continue until the remaining number and its factors are all primes.
The division should be done by primes, but then you need to know which one is a prime.
In practice, one performs a loop from 2 to the base number.
Example:
Base_number = input.int(24)
arr = array.new()
n = Base_number
go = true
while go
for i = 2 to n
if n % i == 0
if n / i == 1
go := false
arr.push(i)
label.new(bar_index, high, str.tostring(arr))
else
arr.push(i)
n /= i
break
Small numbers won't cause issues, but when performing the calculations on, for example, 124,001 and a timeframe of, for example, 1 hour, the script will struggle and finally give a runtime error.
How to solve this?
If we use an array with only primes, we need fewer calculations since if we divide by a non-prime number, we have to divide further until all factors are primes.
I've filled arrays with prime numbers and made libraries of them. (see chapter "Find Prime Numbers" to know how these primes were found).
🔹 Tokens
A hurdle was to fill the libraries with as many prime numbers as possible.
Initially, the maximum token limit of a library was 80K.
Very recently, that limit was lifted to 100K. Kudos to the TradingView developers!
What are tokens?
Tokens are the smallest elements of a program that are meaningful to the compiler. They are also known as the fundamental building blocks of the program.
I have included a code block below the publication code (// - - - Educational (2) - - - ) which, if copied and made to a library, will contain exactly 100K tokens.
Adding more exported functions will throw a "too many tokens" error when saving the library. Subtracting 100K from the shown amount of tokens gives you the amount of used tokens for that particular function.
In that way, one can experiment with the impact of each code addition in terms of tokens.
For example adding the following code in the library:
export a() => a = array.from(1) will result in a 100,041 tokens error, in other words (100,041 - 100,000) that functions contains 41 tokens.
Some more examples, some are straightforward, others are not )
// adding these lines in one of the arrays results in x tokens
, 1 // 2 tokens
, 111, 111, 111 // 12 tokens
, 1111 // 5 tokens
, 111111111 // 10 tokens
, 1111111111111111111 // 20 tokens
, 1234567890123456789 // 20 tokens
, 1111111111111111111 + 1 // 20 tokens
, 1111111111111111111 + 8 // 20 tokens
, 1111111111111111111 + 9 // 20 tokens
, 1111111111111111111 * 1 // 20 tokens
, 1111111111111111111 * 9 // 21 tokens
, 9999999999999999999 // 21 tokens
, 1111111111111111111 * 10 // 21 tokens
, 11111111111111111110 // 21 tokens
//adding these functions to the library results in x tokens
export f() => 1 // 4 tokens
export f() => v = 1 // 4 tokens
export f() => var v = 1 // 4 tokens
export f() => var v = 1, v // 4 tokens
//adding these functions to the library results in x tokens
export a() => const arraya = array.from(1) // 42 tokens
export a() => arraya = array.from(1) // 42 tokens
export a() => a = array.from(1) // 41 tokens
export a() => array.from(1) // 32 tokens
export a() => a = array.new() // 44 tokens
export a() => a = array.new(), a.push(1) // 56 tokens
What if we could lower the amount of tokens, so we can export more Prime Numbers?
Look at this example:
829111, 829121, 829123, 829151, 829159, 829177, 829187, 829193
Eight numbers contain the same number 8291.
If we make a function that removes recurrent values, we get fewer tokens!
829111, 829121, 829123, 829151, 829159, 829177, 829187, 829193
//is transformed to:
829111, 21, 23, 51, 59, 77, 87, 93
The code block below the publication code (// - - - Educational (1) - - - ) shows how these values were reduced. With each step of 100, only the first Prime Number is shown fully.
This function could be enhanced even more to reduce recurrent thousands, tens of thousands, etc.
Using this technique enables us to export more Prime Numbers. The number of necessary libraries was reduced to half or less.
The reduced Prime Numbers are restored using the restoreValues() function, found in the library fikira/Primes_4.
🔹 Find Prime Numbers
This function is merely added to show how I filled arrays with Prime Numbers, which were, in turn, added to libraries (after reduction of recurrent values).
To know whether a number is a Prime Number, we divide the given number by values of the Primes array (Primes 2 -> max. 1,340,011). Once the division results in an integer, where the divisor is smaller than the dividend, the calculation stops since the given number is not a Prime.
When we perform these calculations in a loop, we can check whether a series of numbers is a Prime or not. Each time a number is proven not to be a Prime, the loop starts again with a higher number. Once all Primes of the array are used without the result being an integer, we have found a new Prime Number, which is added to the array.
Doing such calculations on one bar will result in a runtime error.
To solve this, the findPrimeNumbers() function remembers the index of the array. Once a limit has been reached on 1 bar (for example, the number of iterations), calculations will stop on that bar and restart on the next bar.
This spreads the workload over several bars, making it possible to continue these calculations without a runtime error.
The result is placed in log.info() , which can be copied and pasted into a hardcoded array of Prime Number values.
These settings adjust the amount of workload per bar:
Max Size: maximum size of Primes array.
Max Bars Runtime: maximum amount of bars where the function is called.
Max Numbers To Process Per Bar: maximum numbers to check on each bar, whether they are Prime Numbers.
Max Iterations Per Bar: maximum loop calculations per bar.
🔹 The End
❗️ The code and description is written without the help of an LLM, I've only used Grammarly to improve my description (without AI :) )

Angle Market Structure [BigBeluga]🔵 OVERVIEW
Angle Market Structure is a smart pivot-based tool that dynamically adapts to price action by accelerating breakout and breakdown detection. It draws market structure levels based on pivot highs/lows and gradually adjusts those levels closer to price using an angle threshold. Upon breakout, the indicator projects deviation zones with labeled levels (+1, +2, +3 or −1, −2, −3) to track price extension beyond structure.
🔵 CONCEPTS
Adaptive Market Structure: Uses pivots to define structure levels, which dynamically angle closer to price over time to capture breakouts sooner.
Breakout Acceleration: Pivot high levels decrease and pivot low levels increase each bar using a user-defined angle (based on ATR), improving reactivity.
Deviation Zones: Once a breakout or breakdown occurs, 3 deviation levels are projected to show how far price extends beyond the breakout point.
Count Labels: Each successful structure break is numbered sequentially, giving traders insight into momentum and trend persistence.
Visual Clarity: The script uses colored pivot points, trend lines, and extension labels for easy structural interpretation.
🔵 FEATURES
Calculates pivot highs and lows using a customizable length.
Applies an angle modifier (ATR-based) to gradually pull levels closer to price.
Plots breakout and breakdown lines in distinct colors with automatic extension.
Shows deviation zones (+1, +2, +3 or −1, −2, −3) after breakout with customizable size.
Color-coded labels for trend break count (bullish or bearish).
Dynamic label sizing and theme-aware colors.
Smart label positioning to avoid chart clutter.
Built-in limit for deviation zones to maintain clarity and performance.
🔵 HOW TO USE
Use pivot-based market structure to identify breakout and breakdown zones.
Watch for crossover (up) or crossunder (down) events as trend continuation or reversal signals.
Observe +1/+2/+3 or -1/-2/-3 levels for overextension opportunities or trailing stop ideas.
Use breakout count as a proxy for trend strength—multiple counts suggest momentum.
Combine with volume or order flow tools for higher confidence entries at breakout points.
Adjust the angle setting to fine-tune sensitivity based on market volatility.
🔵 CONCLUSION
Angle Market Structure enhances traditional pivot-based analysis by introducing breakout acceleration and structured deviation tracking. It’s a powerful tool for traders seeking a cleaner, faster read on market structure and momentum strength—especially during impulsive price moves or structural transitions.
Dynamic Swing Anchored VWAP (Zeiierman)█ Overview
Dynamic Swing Anchored VWAP (Zeiierman) is a price–volume tool that anchors VWAP at fresh swing highs/lows and then adapts its responsiveness as conditions change. Instead of one static VWAP that drifts away over time, this indicator re-anchors at meaningful structure points (swings). It computes a decayed, volume-weighted average that can speed up in volatile markets and slow down during quiet periods.
Blending swing structure with an adaptive VWAP engine creates a fair-value path that stays aligned with current price behavior, making retests, pullbacks, and mean reversion opportunities easier to spot and trade.
█ How It Works
⚪ Swing Anchor Engine
The script scans for swing highs/lows using your Swing Period.
When market direction flips (new pivot confirmed), the indicator anchors a new VWAP at that pivot and starts tracking from there.
⚪ Adaptive VWAP Core
From each anchor , VWAP is computed using a decay model (recent price×volume matters more; older data matters less).
Adaptive Price Tracking lets you set the base responsiveness in “bars.” Lower = more reactive, higher = smoother.
Volatility Adjustment (ATR vs Avg ATR) can automatically speed up the VWAP during spikes and slow it during compression, so the line stays relevant to live conditions.
█ Why This Adaptive Approach Beats a Simple VWAP
Standard VWAP is cumulative from the anchor point. As time passes and volume accumulates, it often drifts far from current price, especially in prolonged trends or multi-session moves. That drift makes retests rare and unreliable.
Dynamic Swing Anchored VWAP solves this in two ways:
⚪ Event-Driven Anchoring (Swings):
By restarting at fresh swing highs/lows, the VWAP reference reflects today’s structure. You get frequent, meaningful retests because the anchor stays near the action.
⚪ Adaptive Responsiveness (Volatility-Aware):
Markets don’t move at one speed. When volatility expands, a fixed VWAP lags; when volatility contracts, it can overreact to noise. Here, the “tracking speed” can auto-adjust using ATR vs its average.
High Volatility → faster tracking: VWAP hugs price more tightly, preserving retest relevance.
Low Volatility → smoother tracking: VWAP filters chop and stays stable.
Result: A VWAP that follows price more accurately, creating plenty of credible retest opportunities and more trustworthy mean-reversion/continuation reads than a simple, ever-growing VWAP.
█ How to Use
⚪ S wing-Aware Fair Value
Use the VWAP as a dynamic fair-value guide that restarts at key structural pivots. Pullbacks to the VWAP after impulsive moves often provide retest entries.
⚪ Trend Trading
In trends, the adaptive VWAP will ride closer to price, offering continuation pullbacks.
█ Settings
Swing Period: Number of bars to confirm swing highs/lows. Larger = bigger, cleaner pivots (slower); smaller = more frequent pivots (noisier).
Adaptive Price Tracking: Sets the base reaction speed (in bars). Lower = faster, tighter to price; higher = smoother, slower.
Adapt APT by ATR ratio: When ON, the tracking speed auto-adjusts with market volatility (ATR vs its own average). High vol → faster; low vol → calmer.
Volatility Bias: Controls how strongly volatility affects the speed. >1 = stronger effect; <1 = lighter touch.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

Trading Holidays and Expiry CalendarTrading Holiday and Expiry Calendar
This indicator displays calendar for current and next 2 months. Calendar marks ‘CRITICAL DAYS’ on the calendar.
‘CRITICAL DAYS’:
Trading Days
Trading Holidays
Weekends
Expiry Days
Out of these ‘Expiry Days’ are marked based on User input and rest of the days are derived and marked automatically.
Why this indicator:
Most of the Pine Script developers find it tedious (rather difficult or impossible) to find future holidays and expiry days.
This indicator exactly does that based on a simple input parameter
Use cases:
Calendar view of 3 months Trading days along with identification off critical activity days
Pine Script developers can extract code/functions from the indicator and use it for building indicators and strategies
Chart Snapshot

Drawdown Distribution Analysis (DDA) ACADEMIC FOUNDATION AND RESEARCH BACKGROUND
The Drawdown Distribution Analysis indicator implements quantitative risk management principles, drawing upon decades of academic research in portfolio theory, behavioral finance, and statistical risk modeling. This tool provides risk assessment capabilities for traders and portfolio managers seeking to understand their current position within historical drawdown patterns.
The theoretical foundation of this indicator rests on modern portfolio theory as established by Markowitz (1952), who introduced the fundamental concepts of risk-return optimization that continue to underpin contemporary portfolio management. Sharpe (1966) later expanded this framework by developing risk-adjusted performance measures, most notably the Sharpe ratio, which remains a cornerstone of performance evaluation in financial markets.
The specific focus on drawdown analysis builds upon the work of Chekhlov, Uryasev and Zabarankin (2005), who provided the mathematical framework for incorporating drawdown measures into portfolio optimization. Their research demonstrated that traditional mean-variance optimization often fails to capture the full risk profile of investment strategies, particularly regarding sequential losses. More recent work by Goldberg and Mahmoud (2017) has brought these theoretical concepts into practical application within institutional risk management frameworks.
Value at Risk methodology, as comprehensively outlined by Jorion (2007), provides the statistical foundation for the risk measurement components of this indicator. The coherent risk measures framework developed by Artzner et al. (1999) ensures that the risk metrics employed satisfy the mathematical properties required for sound risk management decisions. Additionally, the focus on downside risk follows the framework established by Sortino and Price (1994), while the drawdown-adjusted performance measures implement concepts introduced by Young (1991).
MATHEMATICAL METHODOLOGY
The core calculation methodology centers on a peak-tracking algorithm that continuously monitors the maximum price level achieved and calculates the percentage decline from this peak. The drawdown at any time t is defined as DD(t) = (P(t) - Peak(t)) / Peak(t) × 100, where P(t) represents the asset price at time t and Peak(t) represents the running maximum price observed up to time t.
Statistical distribution analysis forms the analytical backbone of the indicator. The system calculates key percentiles using the ta.percentile_nearest_rank() function to establish the 5th, 10th, 25th, 50th, 75th, 90th, and 95th percentiles of the historical drawdown distribution. This approach provides a complete picture of how the current drawdown compares to historical patterns.
Statistical significance assessment employs standard deviation bands at one, two, and three standard deviations from the mean, following the conventional approach where the upper band equals μ + nσ and the lower band equals μ - nσ. The Z-score calculation, defined as Z = (DD - μ) / σ, enables the identification of statistically extreme events, with thresholds set at |Z| > 2.5 for extreme drawdowns and |Z| > 3.0 for severe drawdowns, corresponding to confidence levels exceeding 99.4% and 99.7% respectively.
ADVANCED RISK METRICS
The indicator incorporates several risk-adjusted performance measures that extend beyond basic drawdown analysis. The Sharpe ratio calculation follows the standard formula Sharpe = (R - Rf) / σ, where R represents the annualized return, Rf represents the risk-free rate, and σ represents the annualized volatility. The system supports dynamic sourcing of the risk-free rate from the US 10-year Treasury yield or allows for manual specification.
The Sortino ratio addresses the limitation of the Sharpe ratio by focusing exclusively on downside risk, calculated as Sortino = (R - Rf) / σd, where σd represents the downside deviation computed using only negative returns. This measure provides a more accurate assessment of risk-adjusted performance for strategies that exhibit asymmetric return distributions.
The Calmar ratio, defined as Annual Return divided by the absolute value of Maximum Drawdown, offers a direct measure of return per unit of drawdown risk. This metric proves particularly valuable for comparing strategies or assets with different risk profiles, as it directly relates performance to the maximum historical loss experienced.
Value at Risk calculations provide quantitative estimates of potential losses at specified confidence levels. The 95% VaR corresponds to the 5th percentile of the drawdown distribution, while the 99% VaR corresponds to the 1st percentile. Conditional VaR, also known as Expected Shortfall, estimates the average loss in the worst 5% of scenarios, providing insight into tail risk that standard VaR measures may not capture.
To enable fair comparison across assets with different volatility characteristics, the indicator calculates volatility-adjusted drawdowns using the formula Adjusted DD = Raw DD / (Volatility / 20%). This normalization allows for meaningful comparison between high-volatility assets like cryptocurrencies and lower-volatility instruments like government bonds.
The Risk Efficiency Score represents a composite measure ranging from 0 to 100 that combines the Sharpe ratio and current percentile rank to provide a single metric for quick asset assessment. Higher scores indicate superior risk-adjusted performance relative to historical patterns.
COLOR SCHEMES AND VISUALIZATION
The indicator implements eight distinct color themes designed to accommodate different analytical preferences and market contexts. The EdgeTools theme employs a corporate blue palette that matches the design system used throughout the edgetools.org platform, ensuring visual consistency across analytical tools.
The Gold theme specifically targets precious metals analysis with warm tones that complement gold chart analysis, while the Quant theme provides a grayscale scheme suitable for analytical environments that prioritize clarity over aesthetic appeal. The Behavioral theme incorporates psychology-based color coding, using green to represent greed-driven market conditions and red to indicate fear-driven environments.
Additional themes include Ocean, Fire, Matrix, and Arctic schemes, each designed for specific market conditions or user preferences. All themes function effectively with both dark and light mode trading platforms, ensuring accessibility across different user interface configurations.
PRACTICAL APPLICATIONS
Asset allocation and portfolio construction represent primary use cases for this analytical framework. When comparing multiple assets such as Bitcoin, gold, and the S&P 500, traders can examine Risk Efficiency Scores to identify instruments offering superior risk-adjusted performance. The 95% VaR provides worst-case scenario comparisons, while volatility-adjusted drawdowns enable fair comparison despite varying volatility profiles.
The practical decision framework suggests that assets with Risk Efficiency Scores above 70 may be suitable for aggressive portfolio allocations, scores between 40 and 70 indicate moderate allocation potential, and scores below 40 suggest defensive positioning or avoidance. These thresholds should be adjusted based on individual risk tolerance and market conditions.
Risk management and position sizing applications utilize the current percentile rank to guide allocation decisions. When the current drawdown ranks above the 75th percentile of historical data, indicating that current conditions are better than 75% of historical periods, position increases may be warranted. Conversely, when percentile rankings fall below the 25th percentile, indicating elevated risk conditions, position reductions become advisable.
Institutional portfolio monitoring applications include hedge fund risk dashboard implementations where multiple strategies can be monitored simultaneously. Sharpe ratio tracking identifies deteriorating risk-adjusted performance across strategies, VaR monitoring ensures portfolios remain within established risk limits, and drawdown duration tracking provides valuable information for investor reporting requirements.
Market timing applications combine the statistical analysis with trend identification techniques. Strong buy signals may emerge when risk levels register as "Low" in conjunction with established uptrends, while extreme risk levels combined with downtrends may indicate exit or hedging opportunities. Z-scores exceeding 3.0 often signal statistically oversold conditions that may precede trend reversals.
STATISTICAL SIGNIFICANCE AND VALIDATION
The indicator provides 95% confidence intervals around current drawdown levels using the standard formula CI = μ ± 1.96σ. This statistical framework enables users to assess whether current conditions fall within normal market variation or represent statistically significant departures from historical patterns.
Risk level classification employs a dynamic assessment system based on percentile ranking within the historical distribution. Low risk designation applies when current drawdowns perform better than 50% of historical data, moderate risk encompasses the 25th to 50th percentile range, high risk covers the 10th to 25th percentile range, and extreme risk applies to the worst 10% of historical drawdowns.
Sample size considerations play a crucial role in statistical reliability. For daily data, the system requires a minimum of 252 trading days (approximately one year) but performs better with 500 or more observations. Weekly data analysis benefits from at least 104 weeks (two years) of history, while monthly data requires a minimum of 60 months (five years) for reliable statistical inference.
IMPLEMENTATION BEST PRACTICES
Parameter optimization should consider the specific characteristics of different asset classes. Equity analysis typically benefits from 500-day lookback periods with 21-day smoothing, while cryptocurrency analysis may employ 365-day lookback periods with 14-day smoothing to account for higher volatility patterns. Fixed income analysis often requires longer lookback periods of 756 days with 34-day smoothing to capture the lower volatility environment.
Multi-timeframe analysis provides hierarchical risk assessment capabilities. Daily timeframe analysis supports tactical risk management decisions, weekly analysis informs strategic positioning choices, and monthly analysis guides long-term allocation decisions. This hierarchical approach ensures that risk assessment occurs at appropriate temporal scales for different investment objectives.
Integration with complementary indicators enhances the analytical framework. Trend indicators such as RSI and moving averages provide directional bias context, volume analysis helps confirm the severity of drawdown conditions, and volatility measures like VIX or ATR assist in market regime identification.
ALERT SYSTEM AND AUTOMATION
The automated alert system monitors five distinct categories of risk events. Risk level changes trigger notifications when drawdowns move between risk categories, enabling proactive risk management responses. Statistical significance alerts activate when Z-scores exceed established threshold levels of 2.5 or 3.0 standard deviations.
New maximum drawdown alerts notify users when historical maximum levels are exceeded, indicating entry into uncharted risk territory. Poor risk efficiency alerts trigger when the composite risk efficiency score falls below 30, suggesting deteriorating risk-adjusted performance. Sharpe ratio decline alerts activate when risk-adjusted performance turns negative, indicating that returns no longer compensate for the risk undertaken.
TRADING STRATEGIES
Conservative risk parity strategies can be implemented by monitoring Risk Efficiency Scores across a diversified asset portfolio. Monthly rebalancing maintains equal risk contribution from each asset, with allocation reductions triggered when risk levels reach "High" status and complete exits executed when "Extreme" risk levels emerge. This approach typically results in lower overall portfolio volatility, improved risk-adjusted returns, and reduced maximum drawdown periods.
Tactical asset rotation strategies compare Risk Efficiency Scores across different asset classes to guide allocation decisions. Assets with scores exceeding 60 receive overweight allocations, while assets scoring below 40 receive underweight positions. Percentile rankings provide timing guidance for allocation adjustments, creating a systematic approach to asset allocation that responds to changing risk-return profiles.
Market timing strategies with statistical edges can be constructed by entering positions when Z-scores fall below -2.5, indicating statistically oversold conditions, and scaling out when Z-scores exceed 2.5, suggesting overbought conditions. The 95% VaR serves as a stop-loss reference point, while trend confirmation indicators provide additional validation for position entry and exit decisions.
LIMITATIONS AND CONSIDERATIONS
Several statistical limitations affect the interpretation and application of these risk measures. Historical bias represents a fundamental challenge, as past drawdown patterns may not accurately predict future risk characteristics, particularly during structural market changes or regime shifts. Sample dependence means that results can be sensitive to the selected lookback period, with shorter periods providing more responsive but potentially less stable estimates.
Market regime changes can significantly alter the statistical parameters underlying the analysis. During periods of structural market evolution, historical distributions may provide poor guidance for future expectations. Additionally, many financial assets exhibit return distributions with fat tails that deviate from normal distribution assumptions, potentially leading to underestimation of extreme event probabilities.
Practical limitations include execution risk, where theoretical signals may not translate directly into actual trading results due to factors such as slippage, timing delays, and market impact. Liquidity constraints mean that risk metrics assume perfect liquidity, which may not hold during stressed market conditions when risk management becomes most critical.
Transaction costs are not incorporated into risk-adjusted return calculations, potentially overstating the attractiveness of strategies that require frequent trading. Behavioral factors represent another limitation, as human psychology may override statistical signals, particularly during periods of extreme market stress when disciplined risk management becomes most challenging.
TECHNICAL IMPLEMENTATION
Performance optimization ensures reliable operation across different market conditions and timeframes. All technical analysis functions are extracted from conditional statements to maintain Pine Script compliance and ensure consistent execution. Memory efficiency is achieved through optimized variable scoping and array usage, while computational speed benefits from vectorized calculations where possible.
Data quality requirements include clean price data without gaps or errors that could distort distribution analysis. Sufficient historical data is essential, with a minimum of 100 bars required and 500 or more preferred for reliable statistical inference. Time alignment across related assets ensures meaningful comparison when conducting multi-asset analysis.
The configuration parameters are organized into logical groups to enhance usability. Core settings include the Distribution Analysis Period (100-2000 bars), Drawdown Smoothing Period (1-50 bars), and Price Source selection. Advanced metrics settings control risk-free rate sourcing, either from live market data or fixed rate specification, along with toggles for various risk-adjusted metric calculations.
Display options provide flexibility in visual presentation, including color theme selection from eight available schemes, automatic dark mode optimization, and control over table display, position lines, percentile bands, and standard deviation overlays. These options ensure that the indicator can be adapted to different analytical workflows and visual preferences.
CONCLUSION
The Drawdown Distribution Analysis indicator provides risk management tools for traders seeking to understand their current position within historical risk patterns. By combining established statistical methodology with practical usability features, the tool enables evidence-based risk assessment and portfolio optimization decisions.
The implementation draws upon established academic research while providing practical features that address real-world trading requirements. Dynamic risk-free rate integration ensures accurate risk-adjusted performance calculations, while multiple color schemes accommodate different analytical preferences and use cases.
Academic compliance is maintained through transparent methodology and acknowledgment of limitations. The tool implements peer-reviewed statistical techniques while clearly communicating the constraints and assumptions underlying the analysis. This approach ensures that users can make informed decisions about the appropriate application of the risk assessment framework within their broader trading and investment processes.
BIBLIOGRAPHY
Artzner, P., Delbaen, F., Eber, J.M. and Heath, D. (1999) 'Coherent Measures of Risk', Mathematical Finance, 9(3), pp. 203-228.
Chekhlov, A., Uryasev, S. and Zabarankin, M. (2005) 'Drawdown Measure in Portfolio Optimization', International Journal of Theoretical and Applied Finance, 8(1), pp. 13-58.
Goldberg, L.R. and Mahmoud, O. (2017) 'Drawdown: From Practice to Theory and Back Again', Journal of Risk Management in Financial Institutions, 10(2), pp. 140-152.
Jorion, P. (2007) Value at Risk: The New Benchmark for Managing Financial Risk. 3rd edn. New York: McGraw-Hill.
Markowitz, H. (1952) 'Portfolio Selection', Journal of Finance, 7(1), pp. 77-91.
Sharpe, W.F. (1966) 'Mutual Fund Performance', Journal of Business, 39(1), pp. 119-138.
Sortino, F.A. and Price, L.N. (1994) 'Performance Measurement in a Downside Risk Framework', Journal of Investing, 3(3), pp. 59-64.
Young, T.W. (1991) 'Calmar Ratio: A Smoother Tool', Futures, 20(1), pp. 40-42.

FunctionADFLibrary "FunctionADF"
Augmented Dickey-Fuller test (ADF), The ADF test is a statistical method used to assess whether a time series is stationary – meaning its statistical properties (like mean and variance) do not change over time. A time series with a unit root is considered non-stationary and often exhibits non-mean-reverting behavior, which is a key concept in technical analysis.
Reference:
-
- rtmath.net
- en.wikipedia.org
adftest(data, n_lag, conf)
: Augmented Dickey-Fuller test for stationarity.
Parameters:
data (array) : Data series.
n_lag (int) : Maximum lag.
conf (string) : Confidence Probability level used to test for critical value, (`90%`, `95%`, `99%`).
Returns: `adf` The test statistic. \
`crit` Critical value for the test statistic at the 10 % levels. \
`nobs` Number of observations used for the ADF regression and calculation of the critical values.

Adaptive Market Profile – Auto Detect & Dynamic Activity ZonesAdaptive Market Profile is an advanced indicator that automatically detects and displays the most relevant trend channel and market profile for any asset and timeframe. Unlike standard regression channel tools, this script uses a fully adaptive approach to identify the optimal period, providing you with the channel that best fits the current market dynamics. The calculation is based on maximizing the statistical significance of the trend using Pearson’s R coefficient, ensuring that the most relevant trend is always selected.
Within the selected channel, the indicator generates a dynamic market profile, breaking the price range into configurable zones and displaying the most active areas based on volume or the number of touches. This allows you to instantly identify high-activity price levels and potential support/resistance zones. The “most active lines” are plotted in real-time and always stay parallel to the channel, dynamically adapting to market structure.
Key features:
- Automatic detection of the optimal regression period: The script scans a wide range of lengths and selects the channel that statistically represents the strongest trend.
- Dynamic market profile: Visualizes the distribution of volume or price touches inside the trend channel, with customizable section count.
- Most active zones: Highlights the most traded or touched price levels as dynamic, parallel lines for precise support/resistance reading.
- Manual override: Optionally, users can select their own channel period for full control.
- Supports both linear and logarithmic charts: Simple toggle to match your chart scaling.
Use cases:
- Trend following and channel trading strategies.
- Quick identification of dynamic support/resistance and liquidity zones.
- Objective selection of the most statistically significant trend channel, without manual guesswork.
- Suitable for all assets and timeframes (crypto, stocks, forex, futures).
Originality:
This script goes beyond basic regression channels by integrating dynamic profile analysis and fully adaptive period detection, offering a comprehensive tool for modern technical analysts. The combination of trend detection, market profile, and activity zone mapping is unique and not available in TradingView built-ins.
Instructions:
Add Adaptive Market Profile to your chart. By default, the script automatically detects the optimal channel period and displays the corresponding regression channel with dynamic profile and activity zones. If you prefer manual control, disable “Auto trend channel period” and set your preferred period. Adjust profile settings as needed for your asset and timeframe.
For questions, suggestions, or further customization, contact Julien Eche (@Julien_Eche) directly on TradingView.
