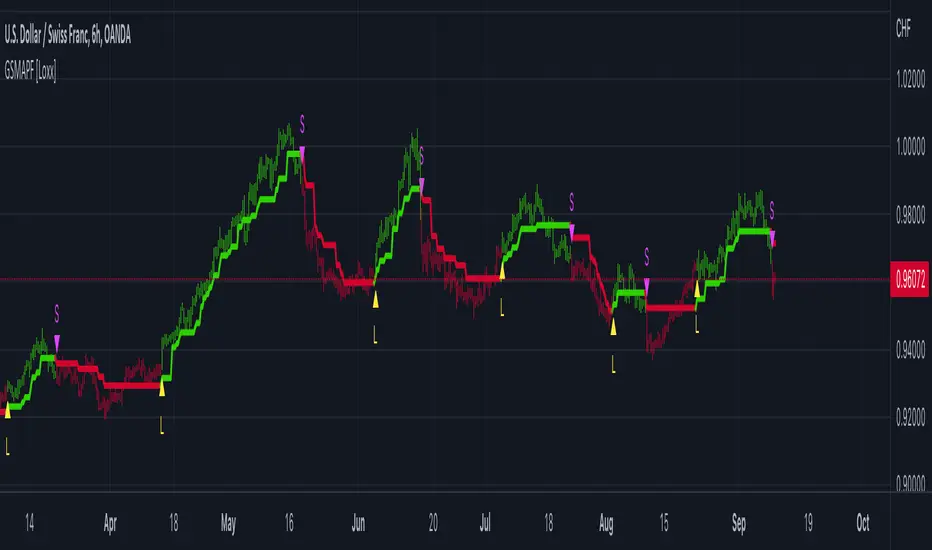
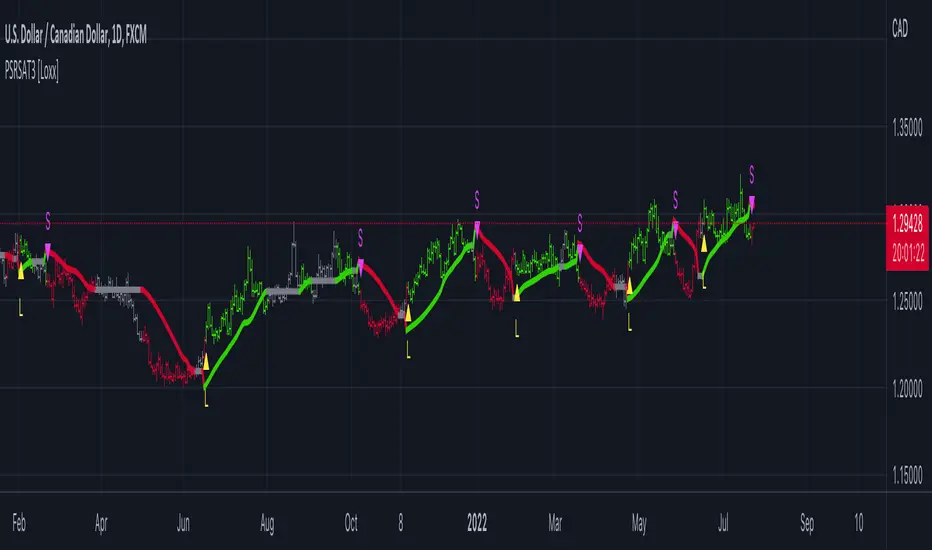
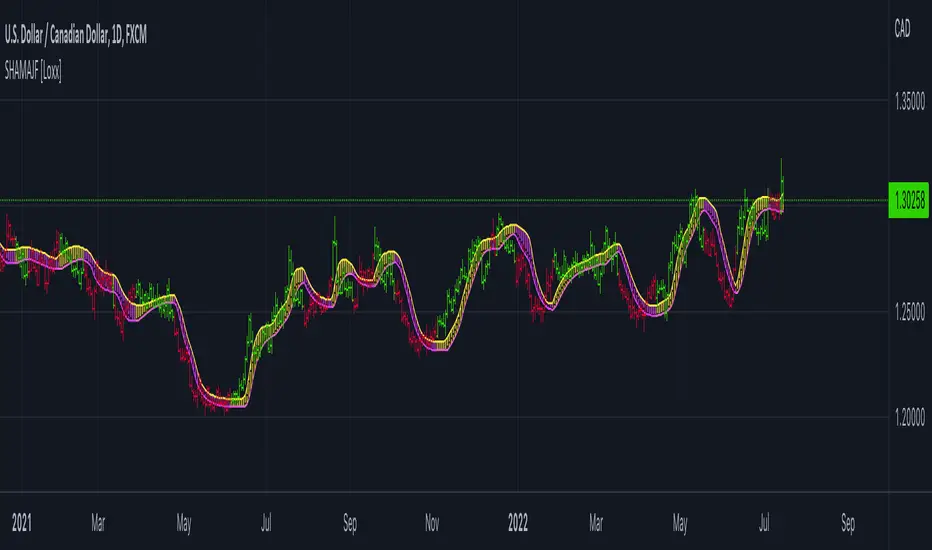
Generalized Step Moving Average w/ Pips Filter [Loxx]Generalized Step Moving Average w/ Pips Filter is a stepping function on source input to derive a moving average. This general form the stepping can also be applied to any other input such as EMA, SMA, HMA, WMA, etc.. This moving average employ a filtering system based on the following:
Core filter, both min and max value: pips * (multiplier) or the (average of momentum) * (multiplier).
Post processing filter: pips * (multiplier)
These filtering options require trend to shift by the above values before changing direction thereby reducing noise and yielding a better defined trend.
Things to note
This indicator requires fine tuning to make it work on all tickers. If you place this on a chart and it shows all green or red candles, then you must adjust the indicator to coincide with the pip movement of that ticker.
This indicator can be used on any timeframe.
Included
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
อินดิเคเตอร์ Pine Script®