Hybrid Adaptive Double Exponential Smoothing🙏🏻 This is HADES (Hybrid Adaptive Double Exponential Smoothing) : fully data-driven & adaptive exponential smoothing method, that gains all the necessary info directly from data in the most natural way and needs no subjective parameters & no optimizations. It gets applied to data itself -> to fit residuals & one-point forecast errors, all at O(1) algo complexity. I designed it for streaming high-frequency univariate time series data, such as medical sensor readings, orderbook data, tick charts, requests generated by a backend, etc.
The HADES method is:
fit & forecast = a + b * (1 / alpha + T - 1)
T = 0 provides in-sample fit for the current datum, and T + n provides forecast for n datapoints.
y = input time series
a = y, if no previous data exists
b = 0, if no previous data exists
otherwise:
a = alpha * y + (1 - alpha) * a
b = alpha * (a - a ) + (1 - alpha) * b
alpha = 1 / sqrt(len * 4)
len = min(ceil(exp(1 / sig)), available data)
sig = sqrt(Absolute net change in y / Sum of absolute changes in y)
For the start datapoint when both numerator and denominator are zeros, we define 0 / 0 = 1
...
The same set of operations gets applied to the data first, then to resulting fit absolute residuals to build prediction interval, and finally to absolute forecasting errors (from one-point ahead forecast) to build forecasting interval:
prediction interval = data fit +- resoduals fit * k
forecasting interval = data opf +- errors fit * k
where k = multiplier regulating intervals width, and opf = one-point forecasts calculated at each time t
...
How-to:
0) Apply to your data where it makes sense, eg. tick data;
1) Use power transform to compensate for multiplicative behavior in case it's there;
2) If you have complete data or only the data you need, like the full history of adjusted close prices: go to the next step; otherwise, guided by your goal & analysis, adjust the 'start index' setting so the calculations will start from this point;
3) Use prediction interval to detect significant deviations from the process core & make decisions according to your strategy;
4) Use one-point forecast for nowcasting;
5) Use forecasting intervals to ~ understand where the next datapoints will emerge, given the data-generating process will stay the same & lack structural breaks.
I advise k = 1 or 1.5 or 4 depending on your goal, but 1 is the most natural one.
...
Why exponential smoothing at all? Why the double one? Why adaptive? Why not Holt's method?
1) It's O(1) algo complexity & recursive nature allows it to be applied in an online fashion to high-frequency streaming data; otherwise, it makes more sense to use other methods;
2) Double exponential smoothing ensures we are taking trends into account; also, in order to model more complex time series patterns such as seasonality, we need detrended data, and this method can be used to do it;
3) The goal of adaptivity is to eliminate the window size question, in cases where it doesn't make sense to use cumulative moving typical value;
4) Holt's method creates a certain interaction between level and trend components, so its results lack symmetry and similarity with other non-recursive methods such as quantile regression or linear regression. Instead, I decided to base my work on the original double exponential smoothing method published by Rob Brown in 1956, here's the original source , it's really hard to find it online. This cool dude is considered the one who've dropped exponential smoothing to open access for the first time🤘🏻
R&D; log & explanations
If you wanna read this, you gotta know, you're taking a great responsability for this long journey, and it gonna be one hell of a trip hehe
Machine learning, apprentissage automatique, машинное обучение, digital signal processing, statistical learning, data mining, deep learning, etc., etc., etc.: all these are just artificial categories created by the local population of this wonderful world, but what really separates entities globally in the Universe is solution complexity / algorithmic complexity.
In order to get the game a lil better, it's gonna be useful to read the HTES script description first. Secondly, let me guide you through the whole R&D; process.
To discover (not to invent) the fundamental universal principle of what exponential smoothing really IS, it required the review of the whole concept, understanding that many things don't add up and don't make much sense in currently available mainstream info, and building it all from the beginning while avoiding these very basic logical & implementation flaws.
Given a complete time t, and yet, always growing time series population that can't be logically separated into subpopulations, the very first question is, 'What amount of data do we need to utilize at time t?'. Two answers: 1 and all. You can't really gain much info from 1 datum, so go for the second answer: we need the whole dataset.
So, given the sequential & incremental nature of time series, the very first and basic thing we can do on the whole dataset is to calculate a cumulative , such as cumulative moving mean or cumulative moving median.
Now we need to extend this logic to exponential smoothing, which doesn't use dataset length info directly, but all cool it can be done via a formula that quantifies the relationship between alpha (smoothing parameter) and length. The popular formulas used in mainstream are:
alpha = 1 / length
alpha = 2 / (length + 1)
The funny part starts when you realize that Cumulative Exponential Moving Averages with these 2 alpha formulas Exactly match Cumulative Moving Average and Cumulative (Linearly) Weighted Moving Average, and the same logic goes on:
alpha = 3 / (length + 1.5) , matches Cumulative Weighted Moving Average with quadratic weights, and
alpha = 4 / (length + 2) , matches Cumulative Weighted Moving Average with cubic weghts, and so on...
It all just cries in your shoulder that we need to discover another, native length->alpha formula that leverages the recursive nature of exponential smoothing, because otherwise, it doesn't make sense to use it at all, since the usual CMA and CMWA can be computed incrementally at O(1) algo complexity just as exponential smoothing.
From now on I will not mention 'cumulative' or 'linearly weighted / weighted' anymore, it's gonna be implied all the time unless stated otherwise.
What we can do is to approach the thing logically and model the response with a little help from synthetic data, a sine wave would suffice. Then we can think of relationships: Based on algo complexity from lower to higher, we have this sequence: exponential smoothing @ O(1) -> parametric statistics (mean) @ O(n) -> non-parametric statistics (50th percentile / median) @ O(n log n). Based on Initial response from slow to fast: mean -> median Based on convergence with the real expected value from slow to fast: mean (infinitely approaches it) -> median (gets it quite fast).
Based on these inputs, we need to discover such a length->alpha formula so the resulting fit will have the slowest initial response out of all 3, and have the slowest convergence with expected value out of all 3. In order to do it, we need to have some non-linear transformer in our formula (like a square root) and a couple of factors to modify the response the way we need. I ended up with this formula to meet all our requirements:
alpha = sqrt(1 / length * 2) / 2
which simplifies to:
alpha = 1 / sqrt(len * 8)
^^ as you can see on the screenshot; where the red line is median, the blue line is the mean, and the purple line is exponential smoothing with the formulas you've just seen, we've met all the requirements.
Now we just have to do the same procedure to discover the length->alpha formula but for double exponential smoothing, which models trends as well, not just level as in single exponential smoothing. For this comparison, we need to use linear regression and quantile regression instead of the mean and median.
Quantile regression requires a non-closed form solution to be solved that you can't really implement in Pine Script, but that's ok, so I made the tests using Python & sklearn:
paste.pics
^^ on this screenshot, you can see the same relationship as on the previous screenshot, but now between the responses of quantile regression & linear regression.
I followed the same logic as before for designing alpha for double exponential smoothing (also considered the initial overshoots, but that's a little detail), and ended up with this formula:
alpha = sqrt(1 / length) / 2
which simplifies to:
alpha = 1 / sqrt(len * 4)
Btw, given the pattern you see in the resulting formulas for single and double exponential smoothing, if you ever want to do triple (not Holt & Winters) exponential smoothing, you'll need len * 2 , and just len * 1 for quadruple exponential smoothing. I hope that based on this sequence, you see the hint that Maybe 4 rounds is enough.
Now since we've dealt with the length->alpha formula, we can deal with the adaptivity part.
Logically, it doesn't make sense to use a slower-than-O(1) method to generate input for an O(1) method, so it must be something universal and minimalistic: something that will help us measure consistency in our data, yet something far away from statistics and close enough to topology.
There's one perfect entity that can help us, this is fractal efficiency. The way I define fractal efficiency can be checked at the very beginning of the post, what matters is that I add a square root to the formula that is not typically added.
As explained in the description of my metric QSFS , one of the reasons for SQRT-transformed values of fractal efficiency applied in moving window mode is because they start to closely resemble normal distribution, yet with support of (0, 1). Data with this interesting property (normally distributed yet with finite support) can be modeled with the beta distribution.
Another reason is, in infinitely expanding window mode, fractal efficiency of every time series that exhibits randomness tends to infinitely approach zero, sqrt-transform kind of partially neutralizes this effect.
Yet another reason is, the square root might better reflect the dimensional inefficiency or degree of fractal complexity, since it could balance the influence of extreme deviations from the net paths.
And finally, fractals exhibit power-law scaling -> measures like length, area, or volume scale in a non-linear way. Adding a square root acknowledges this intrinsic property, while connecting our metric with the nature of fractals.
---
I suspect that, given analogies and connections with other topics in geometry, topology, fractals and most importantly positive test results of the metric, it might be that the sqrt transform is the fundamental part of fractal efficiency that should be applied by default.
Now the last part of the ballet is to convert our fractal efficiency to length value. The part about inverse proportionality is obvious: high fractal efficiency aka high consistency -> lower window size, to utilize only the last data that contain brand new information that seems to be highly reliable since we have consistency in the first place.
The non-obvious part is now we need to neutralize the side effect created by previous sqrt transform: our length values are too low, and exponentiation is the perfect candidate to fix it since translating fractal efficiency into window sizes requires something non-linear to reflect the fractal dynamics. More importantly, using exp() was the last piece that let the metric shine, any other transformations & formulas alike I've tried always had some weird results on certain data.
That exp() in the len formula was the last piece that made it all work both on synthetic and on real data.
^^ a standalone script calculating optimal dynamic window size
Omg, THAT took time to write. Comment and/or text me if you need
...
"Versace Pip-Boy, I'm a young gun coming up with no bankroll" 👻
∞
Optimal
Optimal Length BackTester [YinYangAlgorithms]This Indicator allows for a ‘Optimal Length’ to be inputted within the Settings as a Source. Unlike most Indicators and/or Strategies that rely on either Static Lengths or Internal calculations for the length, this Indicator relies on the Length being derived from an external Indicator in the form of a Source Input.
This may not sound like much, but this application may allows limitless implementations of such an idea. By allowing the input of a Length within a Source Setting you may have an ‘Optimal Length’ that adjusts automatically without the need for manual intervention. This may allow for Traditional and Non-Traditional Indicators and/or Strategies to allow modifications within their settings as well to accommodate the idea of this ‘Optimal Length’ model to create an Indicator and/or Strategy that adjusts its length based on the top performing Length within the current Market Conditions.
This specific Indicator aims to allow backtesting with an ‘Optimal Length’ inputted as a ‘Source’ within the Settings.
This ‘Optimal Length’ may be used to display and potentially optimize multiple different Traditional Indicators within this BackTester. The following Traditional Indicators are included and available to be backtested with an ‘Optimal Length’ inputted as a Source in the Settings:
Moving Average; expressed as either a: Simple Moving Average, Exponential Moving Average or Volume Weighted Moving Average
Bollinger Bands; expressed based on the Moving Average Type
Donchian Channels; expressed based on the Moving Average Type
Envelopes; expressed based on the Moving Average Type
Envelopes Adjusted; expressed based on the Moving Average Type
All of these Traditional Indicators likewise may be displayed with multiple ‘Optimal Lengths’. They have the ability for multiple different ‘Optimal Lengths’ to be inputted and displayed, such as:
Fast Optimal Length
Slow Optimal Length
Neutral Optimal Length
By allowing for the input of multiple different ‘Optimal Lengths’ we may express the ‘Optimal Movement’ of such an expressed Indicator based on different Time Frames and potentially also movement based on Fast, Slow and Neutral (Inclusive) Lengths.
This in general is a simple Indicator that simply allows for the input of multiple different varieties of ‘Optimal Lengths’ to be displayed in different ways using Tradition Indicators. However, the idea and model of accepting a Length as a Source is unique and may be adopted in many different forms and endless ideas.
Tutorial:
You may add an ‘Optimal Length’ within the Settings as a ‘Source’ as followed in the example above. This Indicator allows for the input of a:
Neutral ‘Optimal Length’
Fast ‘Optimal Length’
Slow ‘Optimal Length’
It is important to account for all three as they generally encompass different min/max length values and therefore result in varying ‘Optimal Length’s’.
For instance, say you’re calculating the ‘Optimal Length’ and you use:
Min: 1
Max: 400
This would therefore be scanning for 400 (inclusive) lengths.
As a general way of calculating you may assume the following for which lengths are being used within an ‘Optimal Length’ calculation:
Fast: 1 - 199
Slow: 200 - 400
Neutral: 1 - 400
This allows for the calculation of a Fast and Slow length within the predetermined lengths allotted. However, it likewise allows for a Neutral length which is inclusive to all lengths alloted and may be deemed the ‘Most Accurate’ for these reasons. However, just because the Neutral is inclusive to all lengths, doesn’t mean the Fast and Slow lengths are irrelevant. The Fast and Slow length inputs may be useful for seeing how specifically zoned lengths may fair, and likewise when they cross over and/or under the Neutral ‘Optimal Length’.
This Indicator features the ability to display multiple different types of Traditional Indicators within the ‘Display Type’.
We will go over all of the different ‘Display Types’ with examples on how using a Fast, Slow and Neutral length would impact it:
Simple Moving Average:
In this example above have the Fast, Slow and Neutral Optimal Length formatted as a Slow Moving Average. The first example is on the 15 minute Time Frame and the second is on the 1 Day Time Frame, demonstrating how the length changes based on the Time Frame and the effects it may have.
Here we can see that by inputting ‘Optimal Lengths’ as a Simple Moving Average we may see moving averages that change over time with their ‘Optimal Lengths’. These lengths may help identify Support and/or Resistance locations. By using an 'Optimal Length' rather than a static length, we may create a Moving Average which may be more accurate as it attempts to be adaptive to current Market Conditions.
Bollinger Bands:
Bollinger Bands are a way to see a Simple Moving Average (SMA) that then uses Standard Deviation to identify how much deviation has occurred. This Deviation is then Added and Subtracted from the SMA to create the Bollinger Bands which help Identify possible movement zones that are ‘within range’. This may mean that the price may face Support / Resistance when it reaches the Outer / Inner bounds of the Bollinger Bands. Likewise, it may mean the Price is ‘Overbought’ when outside and above or ‘Underbought’ when outside and below the Bollinger Bands.
By applying All 3 different types of Optimal Lengths towards a Traditional Bollinger Band calculation we may hope to see different ranges of Bollinger Bands and how different lookback lengths may imply possible movement ranges on both a Short Term, Long Term and Neutral perspective. By seeing these possible ranges you may have the ability to identify more levels of Support and Resistance over different lengths and Trading Styles.
Donchian Channels:
Above you’ll see two examples of Machine Learning: Optimal Length applied to Donchian Channels. These are displayed with both the 15 Minute Time Frame and the 1 Day Time Frame.
Donchian Channels are a way of seeing potential Support and Resistance within a given lookback length. They are a way of withholding the High’s and Low’s of a specific lookback length and looking for deviation within this length. By applying a Fast, Slow and Neutral Machine Learning: Optimal Length to these Donchian Channels way may hope to achieve a viable range of High’s and Low’s that one may use to Identify Support and Resistance locations for different ranges of Optimal Lengths and likewise potentially different Trading Strategies.
Envelopes / Envelopes Adjusted:
Envelopes are an interesting one in the sense that they both may be perceived as useful; however we deem that with the use of an ‘Optimal Length’ that the ‘Envelopes Adjusted’ may work best. We will start with examples of the Traditional Envelope then showcase the Adjusted version.
Envelopes:
As you may see, a Traditional form of Envelopes even produced with a Machine Learning: Optimal Length may not produce optimal results. Unfortunately this may occur with some Traditional Indicators and they may need some adjustments as you’ll notice with the ‘Envelopes Adjusted’ version. However, even without the adjustments, these Envelopes may be useful for seeing ‘Overbought’ and ‘Oversold’ locations within a Machine Learning: Optimal Length standpoint.
Envelopes Adjusted:
By adding an adjustment to these Envelopes, we may hope to better reflect our Optimal Length within it. This is caused by adding a ratio reflection towards the current length of the Optimal Length and the max Length used. This allows for the Fast and Neutral (and potentially Slow if Neutral is greater) to achieve a potentially more accurate result.
Envelopes, much like Bollinger Bands are a way of seeing potential movement zones along with potential Support and Resistance. However, unlike Bollinger Bands which are based on Standard Deviation, Envelopes are based on percentages +/- from the Simple Moving Average.
We will conclude our Tutorial here. Hopefully this has given you some insight into how useful adding a ‘Optimal Length’ within an external (secondary) Indicator as a Source within the Settings may be. Likewise, how useful it may be for automation sake in the sense that when the ‘Optimal Length’ changes, it doesn’t rely on an alert where you need to manually update it yourself; instead it will update Automatically and you may reap the benefits of such with little manual input needed (aside from the initial setup).
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

Machine Learning: Optimal RSI [YinYangAlgorithms]This Indicator, will rate multiple different lengths of RSIs to determine which RSI to RSI MA cross produced the highest profit within the lookback span. This ‘Optimal RSI’ is then passed back, and if toggled will then be thrown into a Machine Learning calculation. You have the option to Filter RSI and RSI MA’s within the Machine Learning calculation. What this does is, only other Optimal RSI’s which are in the same bullish or bearish direction (is the RSI above or below the RSI MA) will be added to the calculation.
You can either (by default) use a Simple Average; which is essentially just a Mean of all the Optimal RSI’s with a length of Machine Learning. Or, you can opt to use a k-Nearest Neighbour (KNN) calculation which takes a Fast and Slow Speed. We essentially turn the Optimal RSI into a MA with different lengths and then compare the distance between the two within our KNN Function.
RSI may very well be one of the most used Indicators for identifying crucial Overbought and Oversold locations. Not only that but when it crosses its Moving Average (MA) line it may also indicate good locations to Buy and Sell. Many traders simply use the RSI with the standard length (14), however, does that mean this is the best length?
By using the length of the top performing RSI and then applying some Machine Learning logic to it, we hope to create what may be a more accurate, smooth, optimal, RSI.
Tutorial:
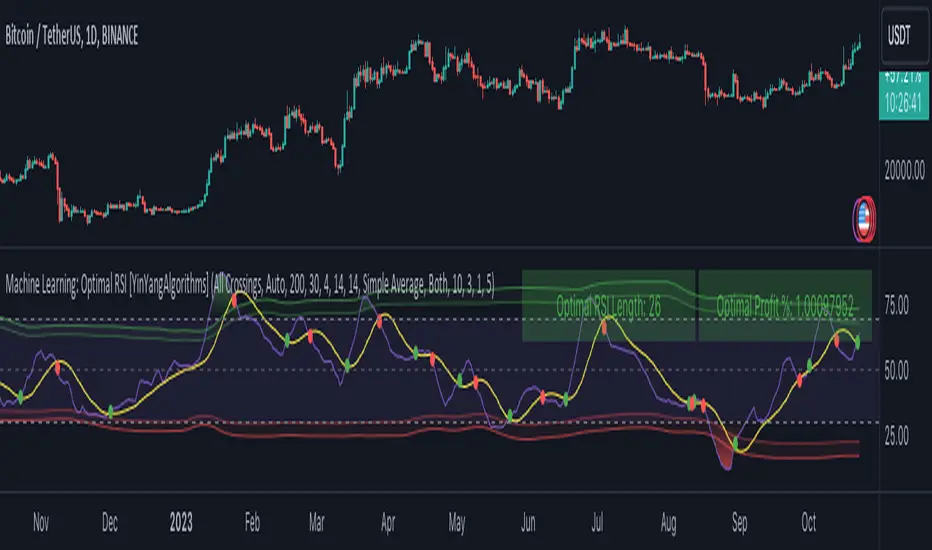
This is a pretty zoomed out Perspective of what the Indicator looks like with its default settings (except with Bollinger Bands and Signals disabled). If you look at the Tables above, you’ll notice, currently the Top Performing RSI Length is 13 with an Optimal Profit % of: 1.00054973. On its default settings, what it does is Scan X amount of RSI Lengths and checks for when the RSI and RSI MA cross each other. It then records the profitability of each cross to identify which length produced the overall highest crossing profitability. Whichever length produces the highest profit is then the RSI length that is used in the plots, until another length takes its place. This may result in what we deem to be the ‘Optimal RSI’ as it is an adaptive RSI which changes based on performance.
In our next example, we changed the ‘Optimal RSI Type’ from ‘All Crossings’ to ‘Extremity Crossings’. If you compare the last two examples to each other, you’ll notice some similarities, but overall they’re quite different. The reason why is, the Optimal RSI is calculated differently. When using ‘All Crossings’ everytime the RSI and RSI MA cross, we evaluate it for profit (short and long). However, with ‘Extremity Crossings’, we only evaluate it when the RSI crosses over the RSI MA and RSI <= 40 or RSI crosses under the RSI MA and RSI >= 60. We conclude the crossing when it crosses back on its opposite of the extremity, and that is how it finds its Optimal RSI.
The way we determine the Optimal RSI is crucial to calculating which length is currently optimal.
In this next example we have zoomed in a bit, and have the full default settings on. Now we have signals (which you can set alerts for), for when the RSI and RSI MA cross (green is bullish and red is bearish). We also have our Optimal RSI Bollinger Bands enabled here too. These bands allow you to see where there may be Support and Resistance within the RSI at levels that aren’t static; such as 30 and 70. The length the RSI Bollinger Bands use is the Optimal RSI Length, allowing it to likewise change in correlation to the Optimal RSI.
In the example above, we’ve zoomed out as far as the Optimal RSI Bollinger Bands go. You’ll notice, the Bollinger Bands may act as Support and Resistance locations within and outside of the RSI Mid zone (30-70). In the next example we will highlight these areas so they may be easier to see.
Circled above, you may see how many times the Optimal RSI faced Support and Resistance locations on the Bollinger Bands. These Bollinger Bands may give a second location for Support and Resistance. The key Support and Resistance may still be the 30/50/70, however the Bollinger Bands allows us to have a more adaptive, moving form of Support and Resistance. This helps to show where it may ‘bounce’ if it surpasses any of the static levels (30/50/70).
Due to the fact that this Indicator may take a long time to execute and it can throw errors for such, we have added a Setting called: Adjust Optimal RSI Lookback and RSI Count. This settings will automatically modify the Optimal RSI Lookback Length and the RSI Count based on the Time Frame you are on and the Bar Indexes that are within. For instance, if we switch to the 1 Hour Time Frame, it will adjust the length from 200->90 and RSI Count from 30->20. If this wasn’t adjusted, the Indicator would Timeout.
You may however, change the Setting ‘Adjust Optimal RSI Lookback and RSI Count’ to ‘Manual’ from ‘Auto’. This will give you control over the ‘Optimal RSI Lookback Length’ and ‘RSI Count’ within the Settings. Please note, it will likely take some “fine tuning” to find working settings without the Indicator timing out, but there are definitely times you can find better settings than our ‘Auto’ will create; especially on higher Time Frames. The Minimum our ‘Auto’ will create is:
Optimal RSI Lookback Length: 90
RSI Count: 20
The Maximum it will create is:
Optimal RSI Lookback Length: 200
RSI Count: 30
If there isn’t much bar index history, for instance, if you’re on the 1 Day and the pair is BTC/USDT you’ll get < 4000 Bar Indexes worth of data. For this reason it is possible to manually increase the settings to say:
Optimal RSI Lookback Length: 500
RSI Count: 50
But, please note, if you make it too high, it may also lead to inaccuracies.
We will conclude our Tutorial here, hopefully this has given you some insight as to how calculating our Optimal RSI and then using it within Machine Learning may create a more adaptive RSI.
Settings:
Optimal RSI:
Show Crossing Signals: Display signals where the RSI and RSI Cross.
Show Tables: Display Information Tables to show information like, Optimal RSI Length, Best Profit, New Optimal RSI Lookback Length and New RSI Count.
Show Bollinger Bands: Show RSI Bollinger Bands. These bands work like the TDI Indicator, except its length changes as it uses the current RSI Optimal Length.
Optimal RSI Type: This is how we calculate our Optimal RSI. Do we use all RSI and RSI MA Crossings or just when it crosses within the Extremities.
Adjust Optimal RSI Lookback and RSI Count: Auto means the script will automatically adjust the Optimal RSI Lookback Length and RSI Count based on the current Time Frame and Bar Index's on chart. This will attempt to stop the script from 'Taking too long to Execute'. Manual means you have full control of the Optimal RSI Lookback Length and RSI Count.
Optimal RSI Lookback Length: How far back are we looking to see which RSI length is optimal? Please note the more bars the lower this needs to be. For instance with BTC/USDT you can use 500 here on 1D but only 200 for 15 Minutes; otherwise it will timeout.
RSI Count: How many lengths are we checking? For instance, if our 'RSI Minimum Length' is 4 and this is 30, the valid RSI lengths we check is 4-34.
RSI Minimum Length: What is the RSI length we start our scans at? We are capped with RSI Count otherwise it will cause the Indicator to timeout, so we don't want to waste any processing power on irrelevant lengths.
RSI MA Length: What length are we using to calculate the optimal RSI cross' and likewise plot our RSI MA with?
Extremity Crossings RSI Backup Length: When there is no Optimal RSI (if using Extremity Crossings), which RSI should we use instead?
Machine Learning:
Use Rational Quadratics: Rationalizing our Close may be beneficial for usage within ML calculations.
Filter RSI and RSI MA: Should we filter the RSI's before usage in ML calculations? Essentially should we only use RSI data that are of the same type as our Optimal RSI? For instance if our Optimal RSI is Bullish (RSI > RSI MA), should we only use ML RSI's that are likewise bullish?
Machine Learning Type: Are we using a Simple ML Average, KNN Mean Average, KNN Exponential Average or None?
KNN Distance Type: We need to check if distance is within the KNN Min/Max distance, which distance checks are we using.
Machine Learning Length: How far back is our Machine Learning going to keep data for.
k-Nearest Neighbour (KNN) Length: How many k-Nearest Neighbours will we account for?
Fast ML Data Length: What is our Fast ML Length? This is used with our Slow Length to create our KNN Distance.
Slow ML Data Length: What is our Slow ML Length? This is used with our Fast Length to create our KNN Distance.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
Optimal Weighted Moving AverageThe Optimal Weighted Moving Average was created by Thomas Hutchinson and Peter G. Zhang, Ph.D. (Stocks & Commodities V. 11:12 (500-505)) and it is very similar to a classic weighted moving average but it uses the correlation between the input and the optimal weighted moving average output to use as the weights. Buy when the line turns green and sell when it turns red.
Let me know if you would like to see me publish any other scripts or if you want something custom done!
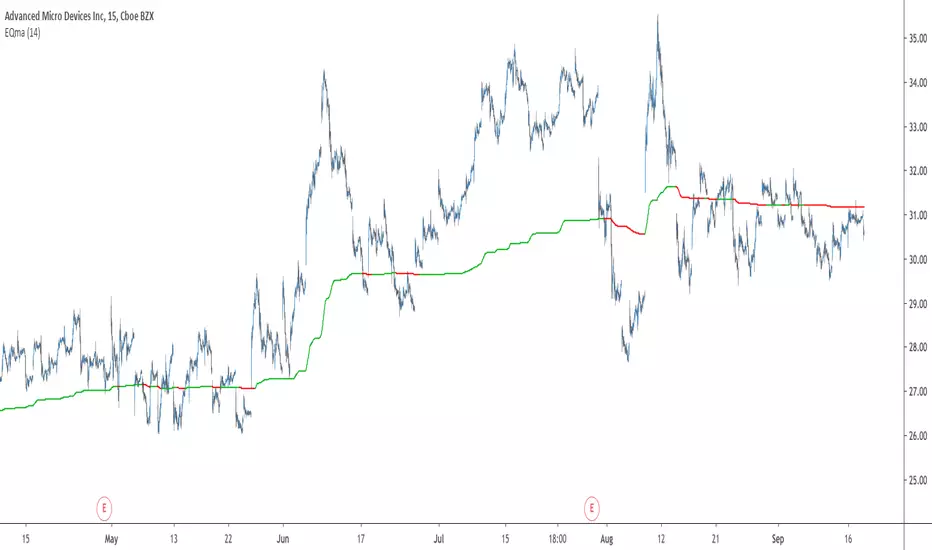
EQma - Adaptive Smoothing Based On Optimal Markets DetectionIntroduction
"You don’t put sunscreen when there is no sun, you don’t use an umbrella when there is no rain, you don’t use a kite when there is no wind, so why would you use a trend following strategy when there is no trend ?"
This is how i start my 4th paper "A New Technical Indicator For Optimal Markets Detection" where i present two new technical indicators. We talked about the first one, running equity, which aim to detect the best moment to enter trades, based on this new metric i made an adaptive moving average.
You can see the full paper here figshare.com
The Indicator
The moving average is based on exponential averaging and use a smoothing variable alpha based on the running equity metric, in order to calculate alpha the running equity is divided by the optimal equity which show the best returns possible for the conditions used. Basically the indicator work as follow :
When the running equity is close to the optimal equity it means that the price need no/little filtering since it does not contain information that need to be filtered, therefore alpha is high, however when the running equity is far from the optimal equity this mean that the price posses malign information that need to be removed.
This is why the indicator will be closer to the price when length is high :
See the full paper for an explanation on how this work.
I added various options for the indicator, one will reduce the lag by squaring alpha, thus giving for length = 14 :
The efficient option will make use of recursion to provide a more efficient indicator :
In green the efficient version, note how this option can allow a better fit with the price.
Conclusion
This is an indicator but at its core its rather a framework, if you have read the paper you'll see that the conditions are just 1 and -1 that changes with time, basically its like making a strategy with :
Condition = if buy then 1 else if sell then -1 else Precedent value of condition.
So those two indicators allow to give useful and usable information about your strategy. I hope it can be of use for anyone here, if so don't hesitate to send me what you made using the proposed indicator (and with all my indicators in general). If you are writing a paper and you think this indicator could fit in your work then let me know so i can be aware of it :)
Thanks for reading !
Acknowledgement
My papers are quite ridiculous but they still manage to get some views, some researchers don't even reach those number in so little time which is quite unfortunate but also really motivating for me, so thanks to those who take time to read them and give me some feedback :)
Optimal 4H Moving Average Ribbon for ETH
Stolen from Madrid Moving Average Ribbon : 2.0 : MMAR
madridjourneyonws.blogspot.com
Adapted for 4H optimal EMAs
This plots a moving average ribbon, please use the exponential not the standard.
It is based on a constant calculation of the most profitable EMAs to trade on the 4H time frame for Ethereum!
Thus the values will be updated with time as they change.
As an example trading the EMA 167 will return ~17742% (15.8.2019)on initial investment starting March 2016, compared to holding giving ~1225%.
It is a simple price breaks above EMAs to go long and break below to go short strategy but I recomened waiting for the full twist.
Lime : Uptrend. Long trading
Green : Reentry (buy the dip) or downtrend reversal warning
Red : Downtrend. Short trading
Maroon : Short Reentry (sell the peak) or uptrend reversal warning

Optimal 4H Moving Average Ribbon//
// Stolen from Madrid Moving Average Ribbon : 2.0 : MMAR
// madridjourneyonws.blogspot.com
// Adapted for 4H optimal EMAs
//
// This plots a moving average ribbon, please use the exponential not the standard.
// It is based on a constant calculation of the most profitable EMAs to trade on the 4H time frame for Ethereum!
// Thus the values will be updated with time as they change.
// As an example trading the EMA 167 will return ~17742% (15.8.2019)on initial investment starting March 2016, compared to holding giving ~1225%.
// It is a simple price breaks above EMAs to go long and break below to go short strategy but I recomened waiting for the full twist.
//
//
// Lime : Uptrend. Long trading
// Green : Reentry (buy the dip) or downtrend reversal warning
// Red : Downtrend. Short trading
// Maroon : Short Reentry (sell the peak) or uptrend reversal warning
//

Ehlers Modified Optimum Elliptic FilterThis indicator was originally developed by John F. Ehlers (Stocks & Commodities, V.18:7 (July, 2000): "Optimal Detrending").
Mr. Ehlers didn't stop and improved his Optimum Elliptic Filter. To reduce the effects of lag he added the one day momentum of the price to the price value.
This modification produce a better response.
Ehlers Optimum Elliptic FilterThis indicator was originally developed by John F. Ehlers (Stocks & Commodities, V.18:7 (July, 2000): "Optimal Detrending").
Mr. Ehlers worked on the smoother that could have no more than a one-bar lag. An elliptic filter provides the maximum amount of smoothing under the constraint of a given lag.